


【论文笔记】CornerNet:Detecting Objects as Paired Keypoints
&论文概述
题目:CornerNet: Detecting Objects as Paired Keypoints
作者及单位:Hei Law · Jia Deng
获取地址:https://arxiv.org/abs/1808.01244v1
&总结与个人观点
本文提出了CornerNet,通过对分组的corners(top-left、bottom-right)来进行目标检测,在MS COCO数据集中实现了较好的结果。
本片文章中较大的创新点在于Corner pooling的提出,以及embedding vector的使用。但是整体结果并没有达到当前最好的情况,虽然corner pooling的使用确实对结果有所提升,二阶段的Cascade R-CNN仍然超越了该方法,当然此方法仍有较大的进步空间。
&贡献
1) 提出使用单个网络通过关键点(top-left、bottom-right)检测来定位目标的bbox的CornerNet,使用single-stage检测器消除设计anchor boxes的需求。
2) 提出corner pooling方法,使得网络更好地定位corners。
&拟解决的问题
问题:主要针对anchor-based框架存在的问题,以及与当前keypoints框架的对比中的问题
分析:
1、Anchor-based方法主要存在2个缺陷:
- 需要非常大的anchor boxes的集合,确保能够覆盖ground truth,而其中只有极少的部分是positive anchor,导致了negative anchor与positive anchor间的极度的不平衡;
- Anchor boxes的使用引入了许多超参数(anchor的数量,size,scale等)与design choices(大多根据ad-hoc heuristics作出决策,尤其当结合单个网络在不同的分辨率上做分离的预测,且每个尺度使用不同的特征以及独立的anchor boxes的集合的多尺度结构时,将会变得更加复杂)。
对关键点,即corner的检测优于bbox中心或候选框检测结果提出假设:
- 相比于anchor-based方法,定位box的中心需要目标所有的4条边,而定位一个角只需要2条边,因此会更简单,甚至在编码入角的定义的先验分布的corner pooling来说会使效果更明显
- 使用corner提供了离散化box空间的更有效的方法,只需要O(wh)个corners就可以代表O(w2h2)个anchor的可能性。
根据以上分析,本文选择了keypoints的检测方法来进行目标检测。
2、基于对一些使用关键点检测框架的分析,将一些策略加入到检测框架中,下表显示了CornerNet针对DeNet、PLN作出的相应的改进:
|
DeNet |
PLN(Point Linking Network) |
CornerNet |
|
two-stage,没有验证两个角是否来自相同的目标,而仅仅依靠子检测网络来拒绝差的RoIs |
|
one-stage,使用单个ConvNet来对corner进行检测以及分组 |
|
在用于分类的区域的确定位置进行特征选取 |
|
不需要任何的特征选取步骤 |
|
|
通过预测像素的位置来对corner以及center进行分组 |
使用预测的embeding向量对corner分组 |
3、每个角所在的地方大多数情况下并不包含目标的信息,即每个角所在的位置并不是存在目标的位置。
提出corner pooling方法来更好地定位corner。
&框架及主要方法
1、CornerNet网络的检测过程

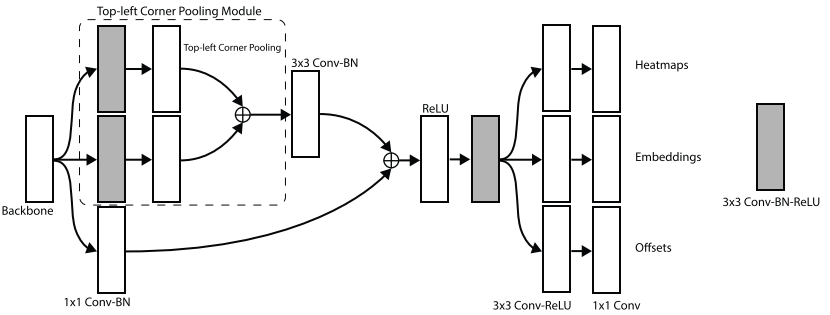
如上图所示,输入的图片经过ConvNet分别提取top-left以及bottom-right的heatmaps,对提取得到的heatmaps进行embedding处理,也即对corners进行分组,然后将其转换为bbox,即可得到输出结果。
1) 检测corners(heatmaps)
每个heatmap拥有C(类别数量)个通道,没有背景channel,每个channel都是一个binary mask,表示一个类别中corners的位置。

对于每个corner来说,只有一个ground-truth positive location,其他的都是negative。如果一组negative corner非常接近对应的ground truth的位置,也能生成一个足以覆盖目标的bbox,如上图所示,故对positive corner附近的以r位半径的圆的范围内减少negative corner的惩罚系数。这个r由目标的size以及与ground truth间的最小的IoU确定。
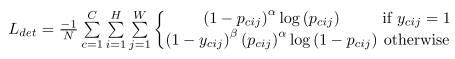
其中pcij是在heatmap中的位置(i, j)上类c的得分,ycij是由非正则化的高斯增强的ground-truth的heatmap。
Offset:
通常使用下采样来整合全局信息以及降低内存消耗。但当其全卷积地应用到图片中时,输出的size通常会小于整张图片,因此原图中的(x, y)映射到heatmap中为,如果此时将heatmap重映射到原图中,可能会损失一些精度,而这种情况可能会在计算一些小的bbox与ground-truth之间的IoU时产生较大的影响。因此定义offset在将heatmap映射到输入的分辨率前对corner的定位进行微调。

在训练中,使用平滑的第一范式损失函数进行位置调整:

下表为对offset的使用进行的消融实现,可以看出offset在每种情况的人脸下均有提升,尤其在小人脸中提升最大。

2) 将corners进行分组(embedding layers)
受Associative Embedding方法,根据embedding的距离对corner进行分组:如果一个左上与右下角属于相同的bbox,其embedding间的距离应当很小。因为只有embedding间的距离被用于对corners进行分组,embedding的实际值并不重要。使用“pull”loss来训练网络对corner进行分组,“push”loss将corner分离:
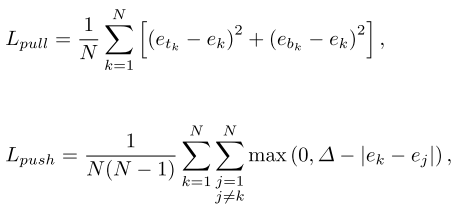
其中ebk、etk分别是第k个目标的bottom-right、top-left角,ek是两者的均值。Pull loss是为了使得etk、ebk间的距离尽量小,push loss则是为了使得每组corner的embedding值尽量大。
2、Corner Pooling
如果使用普通的pooling层,在所有的位置放置相同的权重,然而通常情况下,每个角的地方并没有局部的可视的信息,因此考虑使用一个新颖的pooling方式。

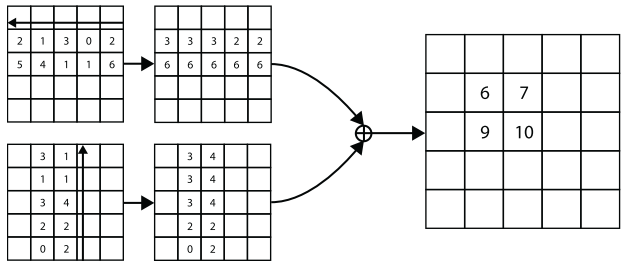
如上图所示,对于Corner Pooling,为确定当前像素位置是否为左上角,需要水平向右查找目标的最上方的边界,竖直向下查找最左方的边界。对于右下角也与之类似。具体操作方法可看下图:
在预测模型中使用将第一个卷积模块替换用corner pooling替换的修正的残差模块,之后连接到卷积模块中,输出多分支分别预测heatmaps,embeddins以及offsets。
使用消融实验,用来验证corner pooling的作用。根据下表可以看出,corner pooling的使用使得整体的AP提高了2个点。

下图为是否使用corner pooling进行bbox结果的对比。从途中可以看出,corner pooling的使用不仅使得结果的bbox更贴近ground truth,同时也可能增强识别的精度。

&遇到的问题
根据Corner Pooling的说法,在进行pooling的过程中,如果有一张图片中存在多个处于同一行的top-left或者同一列的bottom-right,会不会对结果造成很大的误差?

