



【论文笔记】Face R-FCN:Detecting Faces Using Region-based Fully Convolutional Networks
一、思路以及对前人做的工作的思考
人脸检测上的挑战:
实际图片中复杂的多样性(variants):脸部被遮挡、人脸不同的尺度、丰富的表情、图片的光照条件、图片中人摆出的姿势等。
思考:
在该论文提出的时候,基于region的方法在人脸检测中取得较大的成功,然而直接将特定region运作的策略应用到FCN(Fully Convolutional Network),如ResNets中,则会导致降低分类的精度。之后提出的R-FCN网络可以定位FCN中的问题。R-FCN中的ConvNet可以共享整个图片的计算,对训练和测试的效率有所提升。
比起R-CNN,R-FCN结合FCN以及region-based module使用更少的region-wise层来平衡分类和检测的学习。
Q:直接将region应用在FCN中,为什么会降低分类的精度?R-FCN可以定位,所以怎么定位?
需要看一下相关论文,之后补充
二、本篇论文的贡献
1、通过集成一些新颖的有效的技巧将面部的特殊属性纳入思考范围;
2、使用新颖的(novel)positive-sensitive average pooling。该池化方法重新定义在score maps中权重的分布,因此降低了每个面部部位的non-uniformed的分布的影响,即使用加权平均,而不是直接平均的方法。
三、网络结构

1、基于R-FCN的结构
使用101-layer的ResNet作为主干,其中ResNet作用是特征提取,它能提取出高度有代表性的图像特征(highly representative image feature),包含更大的感受野;同时在ResNet的最后阶段(last stage)中使用空洞卷积(atrous/dilated conv),保证特征图的尺度不会再更大的感受野中丢失上下文信息,因此在检测很小的人脸(tiny face)时,可以从其上下文信息中受益。
2、Position-sensitive average pooling
使用position-sensitive average pooling替换原先的global average pooling,来做最后的feature voting(对最后分类的所有结果投票,简单多数)。相较于global average pooling的绝对平均,position-sentive average pooling使用了加权平均,对一个特征图的尺度(n*n)训练参数(n*n)。这样做是因为考虑到人脸检测中面部的每个位置的关注程度可能是不一样,比如对眼睛的关注可能高于对嘴巴的关注程度,所以不能直接取平均值,而是取加权平均,这样能够更好地对人脸进行标识。
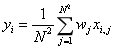
其中wj指的是第jth个参数,N是选取的RoI的scale。
3、Multi-scale Training and Testing
在训练时:shortest side为1024或1200pixels。使得本论文提出的模型能够在检测不同尺度的人脸时保持鲁棒性,特别是在检测tiny人脸时。同时在negative samples中使用OHEM(On-line Hard Example Mining),设置positive samples:negative samples=1:3;OHEM时自举法(bootstrpping)的有效技巧。
在测试时,建立image pyramid,每个scale都被独立测试,来自不同尺度的结果最终整合起来作为图像的结果。
四、分析
1、R-FCN与Faster R-CNN之间的比较
R-FCN使用更深的CNN,且没有在头部使用entire image的共享计算来加快速度;
使用position sensitive RoI pooling,在每个RoI中编码入位置信息,通过一组feature maps池化到output score maps中的确切定位;
没有将fully connected layers引入到ResNet结构中,R-FCN训练得到的feature maps信息更加丰富,而且更方便网络学习class score以及bounding box定位。
2、实验中的设置
分别在WIDER Face dataset与FDDB dataset中进行实验。WIDER FACE中共有32203张图片,共393703标记出的人脸,其中设置训练集、验证集和测试集的划分为40、10、50。基于识别的困难程度将验证集和测试集划分成三个子集(Easy,Medium,Hard)。FDDB中共2845张图片,共5171标记人脸。

