


【目标检测-模型对比1】R-CNN、SPPnet、Fast R-CNN、Faster R-CNN的对比
1、 每个模型的发展及思考
R-CNN:
(1)将location的问题作为一个回归问题在实践中效果不佳;
(2)使用滑动窗口检测,此前的CNNs大多用于受限的目标类别(faces、pedestrians etc),为了保留high spatial resolution,仅使用两层conv和pooling层;
(3)在只有少量标注的数据集时,如何训练一个high capacity模型。

1)SS(Selective Search)选出候选区域
Q:怎么从中选出2000个区域
在操作过程中,SS算法的第一步操作通过过分割将整张图片划分成1k-2k个图像块,最后通过合并等操作。此处的2k个区域仅是一个大致的说法,主要是划定初始的图像块的数量。
2)对候选区域进行图像调整至适合CNN输入的大小
3)CNN
4)特定区域微调
Q:微调为什么会对结果优化那么高?
现象:因为训练的速度太慢,故在训练时仅使用30个epoch,batch_size:64,最终结果ACC=27.4%,但使用过微调后(3个epoch,batch_size:64),整体ACC=93.45%。
解释:之前的理解错误,将预训练(pre_train)的信息给忽略了,此处使用的操作相当于迁移学习,之前的预训练是对更大的数据集或者类似的数据集进行操作,此时的微调使用的是真实给与的数据集,是真正对当前数据集的训练过程。
5)Bounding box regression & SVMs
每个RP(region proposal)输入到每个SVM后,会给出score即属于该类的概率,Bounding box回归过程中回对score进行NMS,去除一些RPs。
SPPnet(Spatial Pyramid Pooling):
考虑到R-CNN中所有的RPs都会先从原始图片中截取出来然后输入到CNN中得到对应的conv feature,需要对卷积特征进行重复计算,且花费了大量的时间。空间金字塔池化网络的提出是为了针对解决这一问题。
在SPPnet中,直接将原始图片输入到卷积神经网络中提取出所有的conv features,结合SS提取出的RPs,在conv feature中选择对应区域的特征,输入到空间金字塔中。在空间金字塔中会对RPs的特征进行不同size的池化,然后将所有的结果拼接起来,输出一个固定长度的特征向量。

最后的分类与Bounding box的回归过程仍与R-CNN相同。
Fast R-CNN:
在SPPnet网络中,虽然对R-CNN的RPs的特征提取过程进行了优化,但是由于深层网络的使用,导致微调操作在卷积层中无效,同时整个结构仍是分离的:卷积特征、分类、Bounding box回归还是分成了三步。
训练与测试的速度都慢。

1)选出候选区域(SS)
2)计算整张图像的卷积特征图
3)从特征图中选出候选区域的RoI,通过池化层得到固定长度的特征向量
Q:RoI池化层怎么使用的?
只有一层SPP。使用较浅的网络便于后向传播,同时使得conv layers能够被fine_tune。
4)一系列的全连接层(fcs)
5)(K+1)类的softmax可能性评估 & bbox regressor
Q:softmax替换SVMs?
SVMs是二分类器,输出的是属于当前类的概率,所以使用softmax分类器输出(K+1)个类的概率也能体现SVMs的作用。最终SVMs对整体的提升率较低,故直接使用softmax分类。
Faster R-CNN
Fast R-CNN对后面的网络结构进行合并训练,使整个系统呈现出端到端的趋势。但是整体花费在RoIs提取上的时间太多,直接使用网络学习如何提取出适合的RoIs。提出RPN,从entire image的conv feature maps中学习提取RoIs,然后将feature maps以及RoIs作为RoI pooling层的输入,进行分类以及Bbox回归。
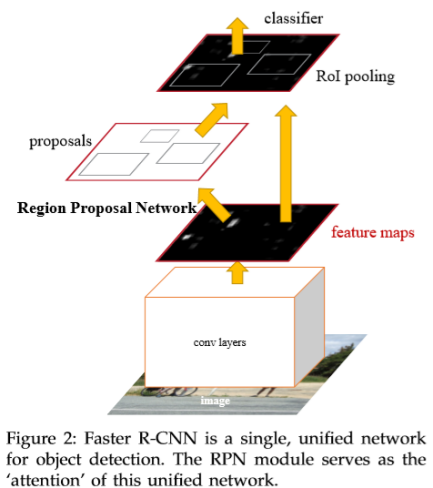
Q:什么是Anchor,怎么通过Anchor来生成RoIs?
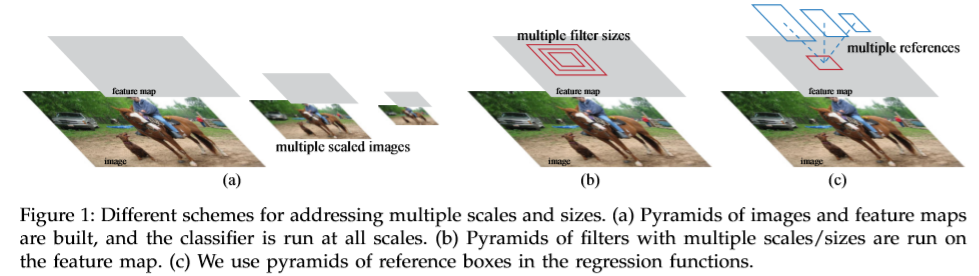
在提取RoIs时,在conv feature maps上使用一个small network进行滑动,输入大小为n*n(3*3),在提取出需要的RoIs后将特征map到一个低维的feature vector。Anchor是当前滑动窗口所在区域的中心点,假定最多能提取出k个RoIs,这k个RoIs的提取根据Anchor的scale以及aspect ratio进行选取。同时下面两幅图展示了,使用Anchor与传统的方式(Spatial Pyramid of images & Spatial Pyramid of filters)的区别:可以认为Spatial Pyramid of images & Spatial Pyramid of filters都是使用一定的scales来提取特征,最后将特征进行整合以及归一化,所以,直接使用anchor并不会导致精度在特征提取方面的损失,但是使用Anchor可以减少计算时间。

2、从整个迭代过程中有什么收获?从眼界、思考方式等方面叙述
(1)一个新方法的提出/使用,需要对整体流程中的局限性进行思考,针对其中的某些地方进行改进;
(2)而对于改进现有的方法,只需要分析在哪些地方造成性能无法提高,就这些问题进行更新即可。
参考文献:
[1] Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik. “Rich feature hierarchies for accurate object detection and semantic segmentation”. arXIv:1311.2524v3 [cs.CV] 7 May 2014.
[2] Ross Girshick Microsoft Research. “Fast R-CNN” in IEEE International Conference on Computer Vision (ICCV), 2015.
[3] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015.
[4] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In TPAMI, 2017.

