
hash_map的简洁实现
hash_map的简洁实现
hash_map是经常被使用的一种数据结构,而其实现方式也是多种多样。如果要求我们使用尽可能简单的方式实现hash_map,具体该如何做呢?
我们知道hash_map最重要两个概念是hash函数和冲突解决算法。hash_map键-值之间的映射关系,hash函数将键映射为内存地址,冲突解决算法用于解决不同的键映射为相同地址时候的情况。
数据结构和算法导论中介绍了大量的hash函数和冲突解决算法,如果选择实现精简的hash_map,那么可以选择“除留取余法”作为hash函数,选择“开散列地址链”作为冲入解决算法。这样的选择不仅使得hash_map实现简单,而且有很高的查询效率。其设计结构如下:
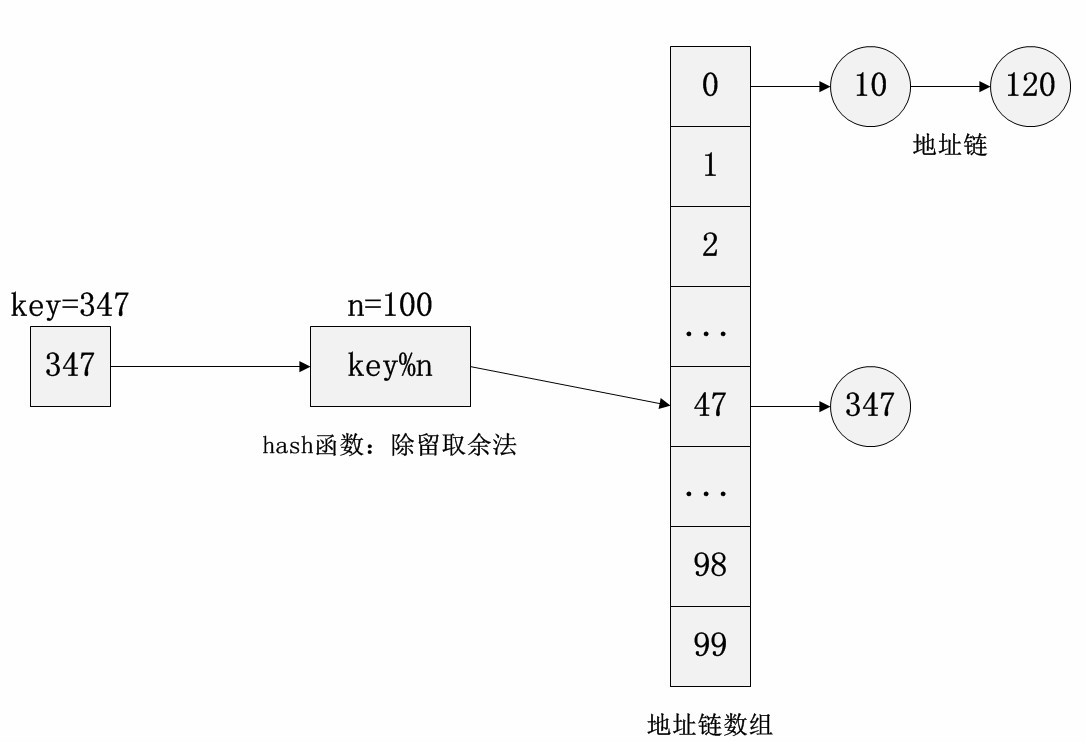
基于地址链的开散列哈希表实现
如图所示,键347通过除留取余法得到地址链的索引,然后将347对应的元素插入到该地址链的尾端。
为了实现地址链,我们需要定义链表节点类型Node。为了简化问题,我们将键值都定义为int类型。

{
int key;//键
int value;//值
Node*next;//链接指针
Node(int k,int v):key(k),value(v),next(NULL){}
};
value用于记录节点数组,key在检索节点时会被使用,next保存链表关系。
基于此,定义hash_map类型SimHash。
class SimHash
{
Node**map;//地址链数组
size_t hash(int key)//hash函数,除留取余法
{
return key%SIZE;
}
public:
SimHash()
{
map=new Node*[SIZE];
for(size_t i=0;i<SIZE;i++)map[i]=NULL;//初始化数组为空
}
~SimHash()
{
for(size_t i=0;i<SIZE;i++)//清除所有节点
{
Node*p;
while(p=map[i])
{
map[i]=p->next;
delete p;
}
}
delete[] map;//清除数组
}
void insert(int key,int value)
{
Node*f=find(key);//插入前查询
if(f)
{
f->value=value;//存在键则覆盖
return;
}
Node*p=map[hash(key)];//确定地址链索引
Node*q=new Node(key,value);//创建节点
while(p&&p->next)p=p->next;//索引到地址链末端
if(p)p->next=q;//添加节点
else map[hash(key)]=q;//地址链的第一个节点
}
void remove(int key)
{
Node*p=map[hash(key)];//确定地址链索引
Node*q=NULL;//前驱指针
while(p)
{
if(p->key==key)//找到键
{
if(q)q->next=p->next;//删除节点
else map[hash(key)]=p->next;//删除地址链的最后一个节点
delete p;
break;
}
q=p;
p=p->next;
}
}
Node* find(int key)
{
Node*p=map[hash(key)];//确定地址链索引
while(p)
{
if(p->key==key)break;//查询成功
p=p->next;
}
return p;
}
};
首先,我们需要一个Node**类型的指针map记录地址链数组的地址,至于数组大小,我们给一个较大的值(这里设置为100),为了简化问题,不需要考虑插入时表满等情况。在构造函数和析构函数内对map内存分配和撤销。另外,节点的内存是动态增加的,因此析构时需要单独处理每个地址链表。
对于数据结构,最关键的便是插入、删除、检索操作,为此定义操作insert、remove、find。
检索操作实现时,首先通过hash函数定位地址链表的索引,然后在地址链表上检索键是否存在即可。
插入操作实现时,首先会检索键是否存在,如果存在则仅仅更新对应节点的数据即可,否则创建新的节点,插入到链表的结尾。对于空链表需要做特殊处理。
删除操作实现时,需要使用两个指针记录节点的位置信息,当遇到满足键的节点时,就将该节点从链表内删除即可。如果删除链表的第一个节点,需要做特殊处理。
以上,便是一个较简单的hash_map的实现了,代码行约80行左右,当然这肯定不是最简单的,如果你有兴趣可以再做进一步的简化。
如果考虑哈希表的键值类型、特殊键类型的hash映射(字符串类型键如何映射为数值)、特殊键类型的比较处理(怎么比较两个自定义类型键是否相等)、索引运算重载这些问题的话,hash_map的实现就变得复杂了。不过这些在STL内实现的比较完整,若你感兴趣可以多做了解。这里我给出自己的一个考虑以上问题的简单hash_map实现。
{
size_t operator()(const char* str)const
{
size_t ret=0;
while(*str)ret=(ret<<5)+*str++;
return ret;
}
};
struct str_cmp
{
bool operator()(const char* str1,const char* str2)const
{
while(*str1&&*str2)
{
if(*str1++!=*str2++)return false;
}
return !*str1&&!*str2;
}
};
template<class K,class T>
class Hashnode
{
public:
Hashnode(K k,T d):key(k),data(d),next(NULL)
{}
K key;
T data;
Hashnode*next;
};
template<class K,class T,class H,class C>
class Hashmap
{
Hashnode<K,T>**map;//hash链表数组
size_t div;//数组大小
size_t hash(K key)//hash函数,获取桶号——除留余数法
{
return h(key)%div;
}
H h;
C c;
Hashnode<K,T>* _find(K key)
{
size_t pos=hash(key);//获取桶号
for(Hashnode<K,T>*p=map[pos];p;p=p->next)
{
if(c(p->key,key))//找到了key
{
return p;
}
}
return NULL;
}
public:
size_t size;//hash表容量
size_t count;//元素个数
Hashmap(size_t sz=6):size(6),div(2),count(0)
{
if(sz>6)
{
size=sz;
div=size/3;
}
map=new Hashnode<K,T>*[div];
for(size_t i=0;i<div;i++)map[i]=NULL;
}
~Hashmap()
{
for(size_t i=0;i<div;i++)
{
while(true)
{
Hashnode<K,T>*p=map[i];
if(p)
{
map[i]=p->next;
delete p;
}
else break;
}
}
delete[] map;
}
void insert(K key,T data)
{
if(count>=size)//表满,增加空间
{
Hashnode<K,T>**oldmap=map;
size_t olddiv=div;
size*=2;
div=size/3;
map=new Hashnode<K,T>*[div];
for(size_t i=0;i<div;i++)map[i]=NULL;
for(size_t i=0;i<olddiv;i++)
{
for(Hashnode<K,T>*p=oldmap[i],*t;p;p=t)
{
t=p->next;
p->next=NULL;//消除后继信息
size_t pos=hash(p->key);//重新映射
Hashnode<K,T>*q;
for(q=map[pos];q&&q->next;q=q->next);
if(!q)map[pos]=p;
else q->next=p;
}
}
delete oldmap;
}
Hashnode<K,T>*p=_find(key);//已经存在,替换数据
if(p)p->data=data;
else
{
size_t pos=hash(key);//获取桶号
Hashnode<K,T>*p;
for(p=map[pos];p&&p->next;p=p->next);//索引到最后位置
Hashnode<K,T>*q=new Hashnode<K,T>(key,data);
if(!p)map[pos]=q;//插入数据节点
else p->next=q;
count++;
}
}
void remove(K key)
{
if(count<=size/2)//元素少于一半
{
Hashnode<K,T>**oldmap=map;
size_t olddiv=div;
size/=2;
div=size/3;
map=new Hashnode<K,T>*[div];
for(size_t i=0;i<div;i++)map[i]=NULL;
for(size_t i=0;i<olddiv;i++)
{
for(Hashnode<K,T>*p=oldmap[i],*t;p;p=t)
{
t=p->next;
p->next=NULL;//消除后继信息
size_t pos=hash(p->key);//重新映射
Hashnode<K,T>*q;
for(q=map[pos];q&&q->next;q=q->next);
if(!q)map[pos]=p;
else q->next=p;
}
}
delete oldmap;
}
size_t pos=hash(key);//获取桶号
for(Hashnode<K,T>*p=map[pos],*q=NULL;p;p=p->next)
{
if(c(p->key,key))//找到了key
{
if(q)q->next=p->next;
else map[pos]=p->next;
delete p;
count--;
break;
}
q=p;
}
}
T& get(K key)
{
Hashnode<K,T>*p=_find(key);
if(p)return p->data;
//没有key,插入map[key]=0
insert(key,0);
return get(key);
}
T& operator[](K key)
{
return get(key);
}
bool find(K key)
{
return !!_find(key);
}
};
int main()
{
Hashmap<char*,int,str_hash,str_cmp> hashmap;
hashmap["A"]=1;
hashmap["B"]=2;
hashmap["C"]=3;
hashmap["D"]=4;
hashmap["E"]=5;
hashmap["F"]=6;
hashmap["G"]=7;
hashmap["H"]=8;
cout<<hashmap["A"]<<" "<<hashmap["B"]<<endl;
cout<<hashmap["C"]<<" "<<hashmap["D"]<<endl;
cout<<hashmap["E"]<<" "<<hashmap["F"]<<endl;
cout<<hashmap["G"]<<" "<<hashmap["H"]<<endl;
cout<<hashmap.size<<endl;
hashmap.remove("A");
hashmap.remove("B");
hashmap.remove("C");
hashmap.remove("D");
hashmap.remove("E");
cout<<hashmap.size<<endl;
cout<<hashmap["A"]<<" "<<hashmap["B"]<<endl;
cout<<hashmap["C"]<<" "<<hashmap["D"]<<endl;
cout<<hashmap["E"]<<" "<<hashmap["F"]<<endl;
cout<<hashmap["G"]<<" "<<hashmap["H"]<<endl;
cout<<hashmap.size<<endl;
return 0;
}
若本文对你有所帮助,您的 关注 和 推荐 是我分享知识的动力!




【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· spring官宣接入deepseek,真的太香了~