
我用Awesome-Graphs看论文:解读Naiad
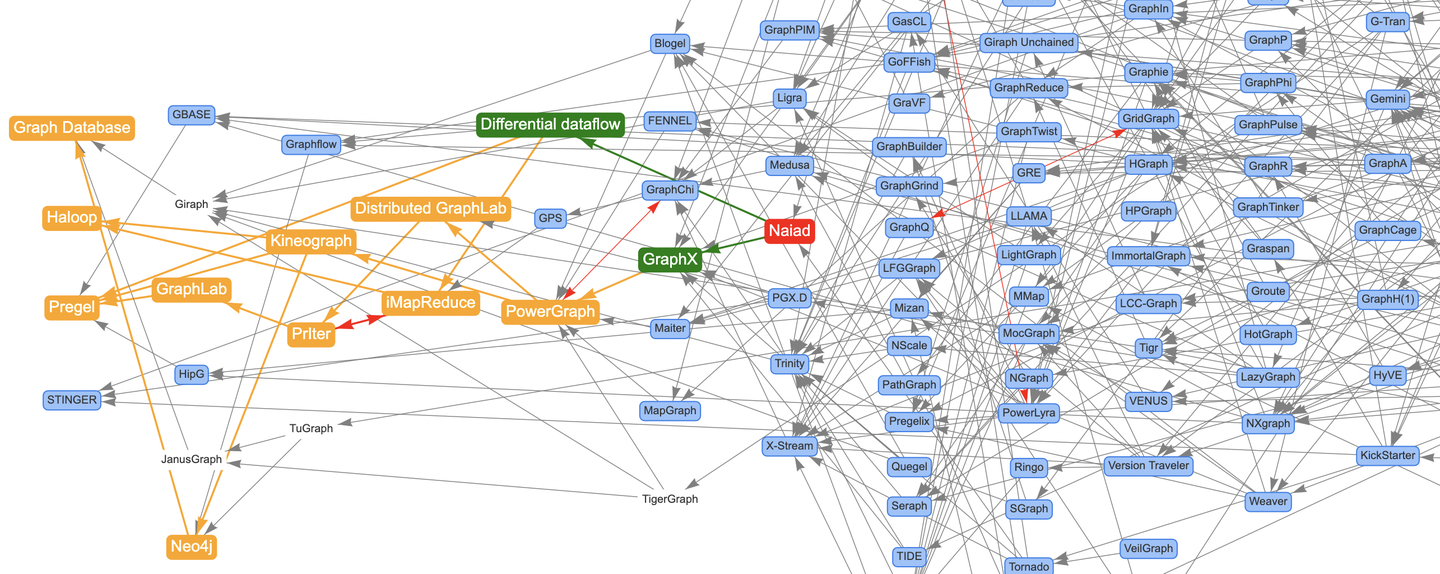
前面通过文章《论文图谱当如是:Awesome-Graphs用200篇图系统论文打个样》向大家介绍了论文图谱项目Awesome-Graphs,并分享了Google的Pregel、OSDI'12的PowerGraph、SOSP'13的X-Stream。这次向大家分享Microsoft发表在SOSP'13的另一篇关于流处理系统论文Naiad,TimelyDataflow是它的开源实现。该论文促进了后续的流图系统的设计与创新,从其调度框架设计中也可以看到TuGraph Analytics调度器的影子。
对图计算技术感兴趣的同学可以多做了解,也非常欢迎大家关注和参与论文图谱的开源项目:
- Awesome-Graphs:https://github.com/TuGraph-family/Awesome-Graphs
- OSGraph:https://github.com/TuGraph-family/OSGraph
提前感谢给项目点Star的小伙伴,接下来我们直接进入正文!
摘要
Naiad是一个可执行有环数据流的分布式数据并行系统,提供了高吞吐的批处理、低延迟的流处理,以及迭代和增量计算的能力。
1. 介绍
支持特性:
- 循环结构化,支持反向边(feedback)。
- 有状态的数据流节点,支持无需全局协调的生产消费能力。
- 节点收齐特定轮次/迭代的输入后的通知机制。
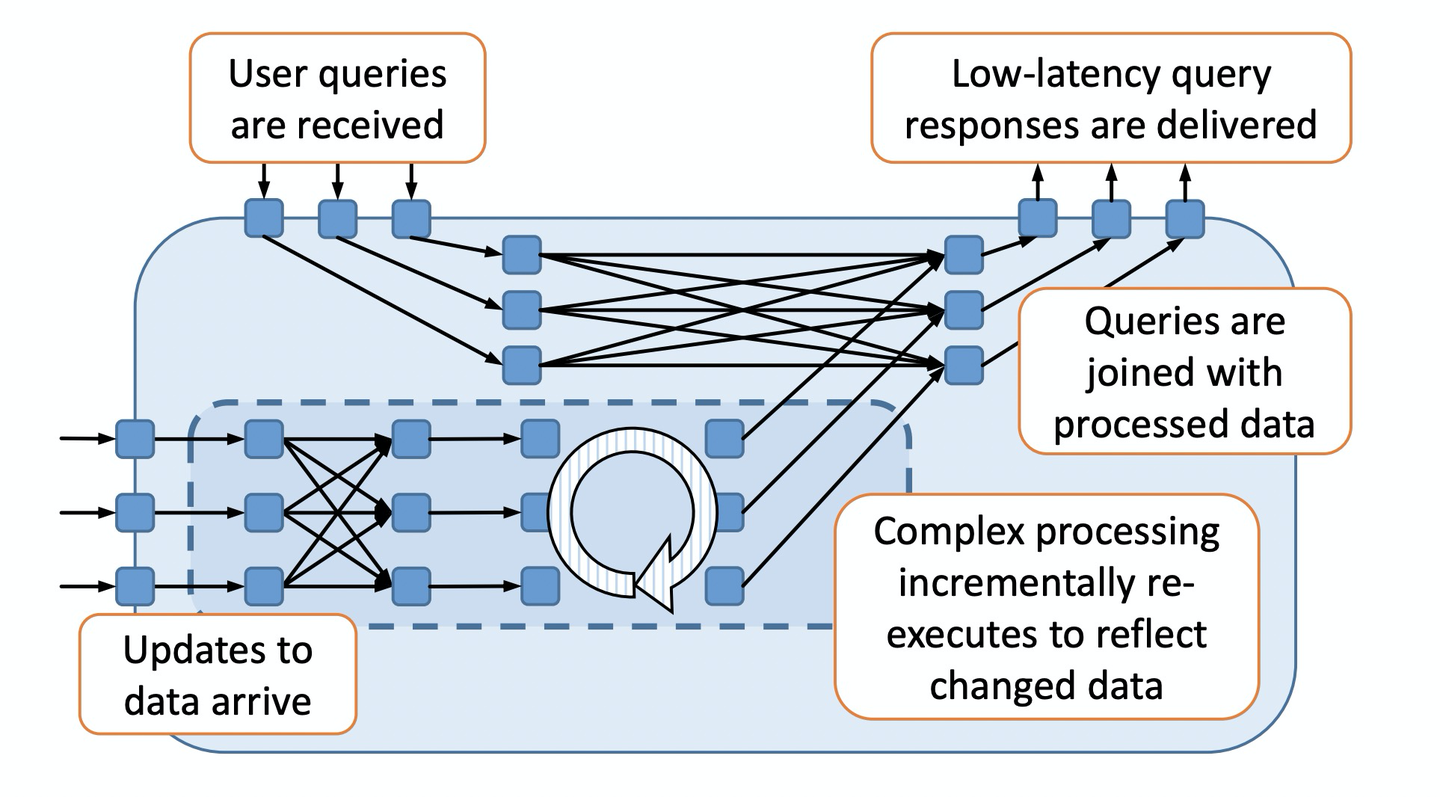
2. 及时数据流
数据流图可以包含嵌套的循环结构,时间戳用于区分数据是由哪个轮次/迭代产生的。
2.1 图结构
及时数据流图包含输入/输出节点,输入节点从外部的生产者接受消息序列,输出节点将消息序列发送到外部消费者。
外部的生产者为每个消息打标了一个轮次(epoch),当没有消息需要输入时,会主动通知输入节点。
生产者也可以关闭输入节点,表示输入节点将不会再收到任何消息。
输出节点的消息也会打标这个轮次,同样当没有消息需要输出时,也会通知外部消费者。
及时数据流图里可以包含嵌套的循环上下文(loop contexts):
- 入口点(ingress vertex):数据流图的边进入循环上下文必须经过入口点,如I。
- 出口点(egress vertex):数据流图的边离开循环上下文必须经过出口点,如E。
- 反馈点(feedback vertex):循环上下文内必须包含反馈点,如F。
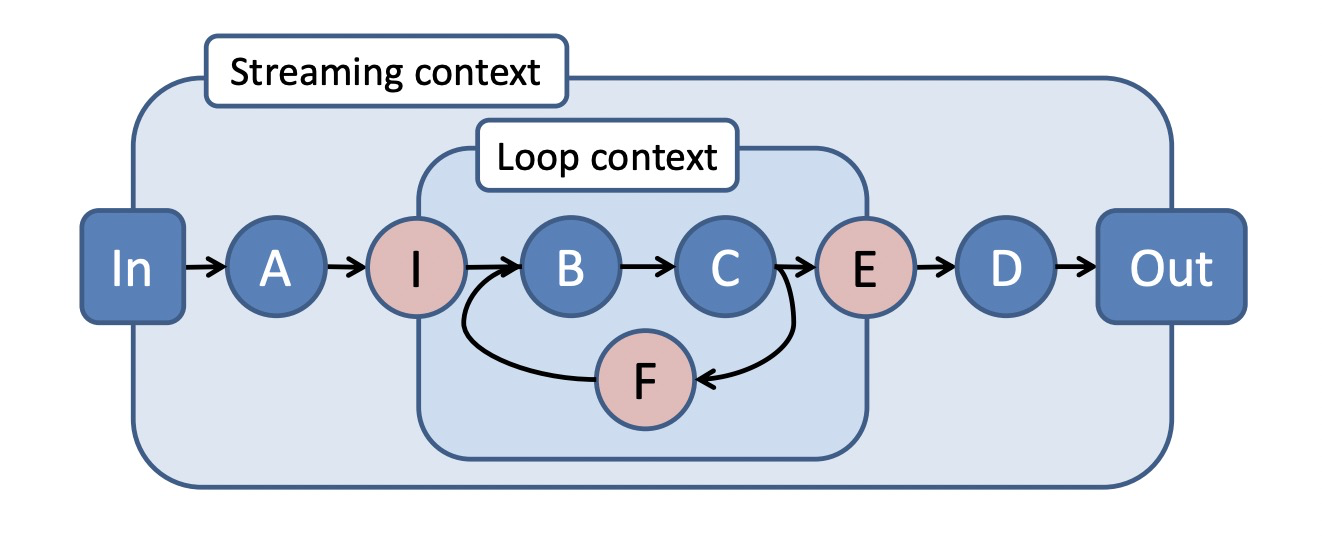
针对上图所表达的计算语义解释:
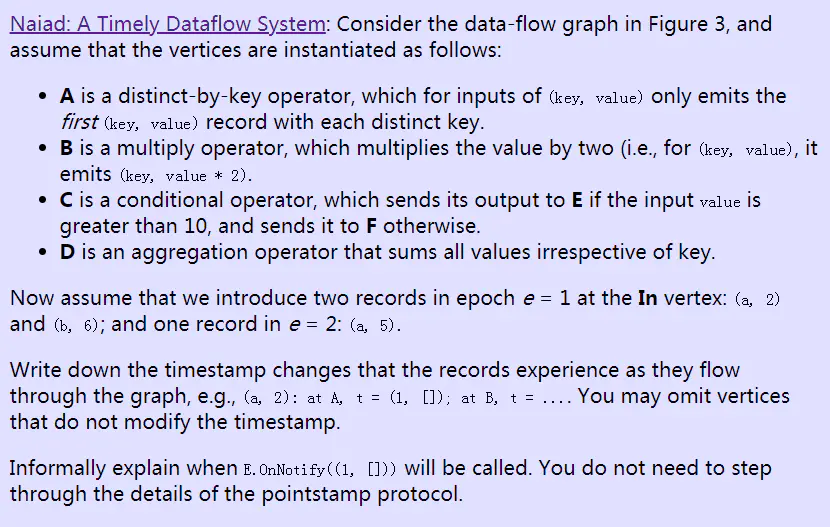
关键概念:逻辑时间戳(logical timestamp):
- e:消息的轮次。
- k:循环嵌套的深度。
- c:向量,每层循环的迭代次数。
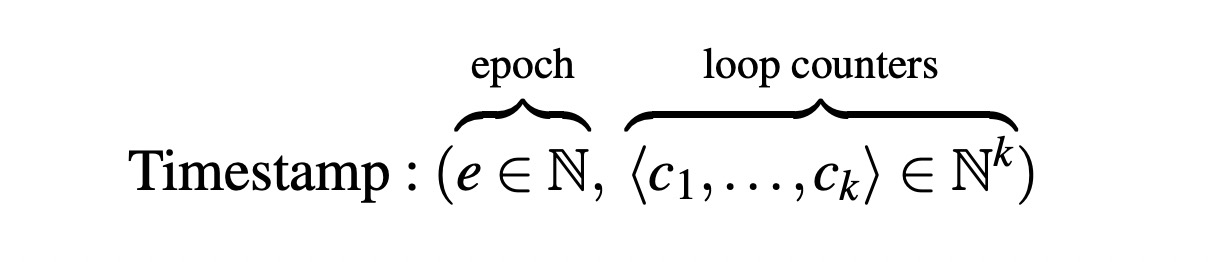
逻辑时间戳变化规则:

- 经过入口点:c增加一个维度,初始化为0,表示循环开始。
- 经过反馈点:c的最后一个维度+1,表示循环次数累计。
- 经过出口点:c的最后一个维度提出,恢复成与入口点一致。
逻辑时间戳大小比较,t1=(e1, <c1, ..., cm>),t2=(e2, <c1, ..., cn>):
- 条件1:整数比较,e1 < e2。
- 条件2:字符串比较,c1 + ... + cm < c1 + ... + cn。
2.2 节点计算
数据流的节点可以接收、发送带逻辑时间戳的消息(message),以及通知(notification)。
每个节点v实现两个回调函数:
- v.OnRecieve(Edge e, Message m, Timestamp t):接收消息。
- v.OnNotify(Timestamp t):接收通知。
并可以调用系统提供的两个函数:
- this.SendBy(Edge e, Message m, Timestamp t):发送消息。
- this.NotifyAt(Timestamp t):发送通知。
对于数据流边e=(u, v),u.SendBy将触发v.OnRecieve,u.NotifyAt将触发v.onNotify。
数据流系统保证v.OnNotify(t)一定发生在v.OnRecieve(e, m, t')之后,其中t' < t,即保证处理完所有t之前的消息后再处理通知,以让节点具备机会清理t之前的工作状态。
这种机制保证了消息处理不会发生时光回溯(backwards in time)。
如下示例代码描述了一个双出的数据流节点实现distinct、count算子的逻辑。
class DistinctCount<S,T> : Vertex<T>
{
Dictionary<T, Dictionary<S,int>> counts;
void OnRecv(Edge e, S msg, T time)
{
if (!counts.ContainsKey(time)) {
counts[time] = new Dictionary<S,int>();
this.NotifyAt(time);
}
if (!counts[time].ContainsKey(msg)) {
counts[time][msg] = 0;
this.SendBy(output1, msg, time);
}
counts[time][msg]++;
}
void OnNotify(T time)
{
foreach (var pair in counts[time])
this.SendBy(output2, pair, time);
counts.Remove(time);
}
}
2.3 实现及时数据流
数据流处理受限于未处理的事件(events:消息、通知)和数据流图的结构。
关键概念:pointstamp:
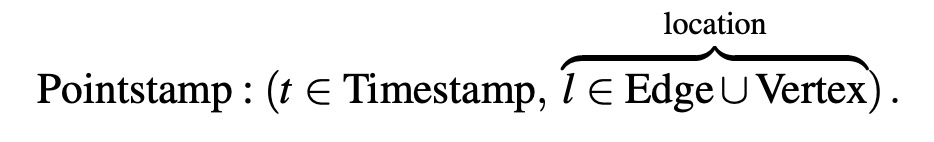
- u.SendBy(e, m, t):生成pointstamp (t, e)。
- u.NotifyAt(t):生成pointstamp (t, v)。
单线程调度器实现:
- 维护一个激活pointstamp(active pointstamp) 集合,集合大小至少为1。对于每个pointstamp,有两个计数器:
- OC(occurrence count):未完成的pointstamp数。
- PC(precursor count):上游激活的pointstamp数。
- 系统初始化时,为输入节点生成第一个pointstamp,其中t=e,OC=1,PC=0。当e完成后,继续生成t=e+1的pointstamp。
- 当激活pointstamp p时,初始化PC为上游所有激活的pointstamp数,并递增下游节点所有pointstamp的PC值。
- 当OC[p]=0时,从active集合删除p,并递减下游节点所有pointstamp的PC值。
- 当PC[p]=0时,表示上游没有激活的pointstamp影响到p,则称p是frontier,调度器会把所有通知发送给frontier。
OC的计算规则为:

3. 分布式实现
- Naiad集群包含多个进程,每个进程包含多个worker,worker管理数据流节点的一个分区。
- worker之间通过本地的共享内存或者远程TCP连接交换消息。
- 进程遵循分布式进度追踪协议(Progress Tracking Protocol),用于协调通知的分发。
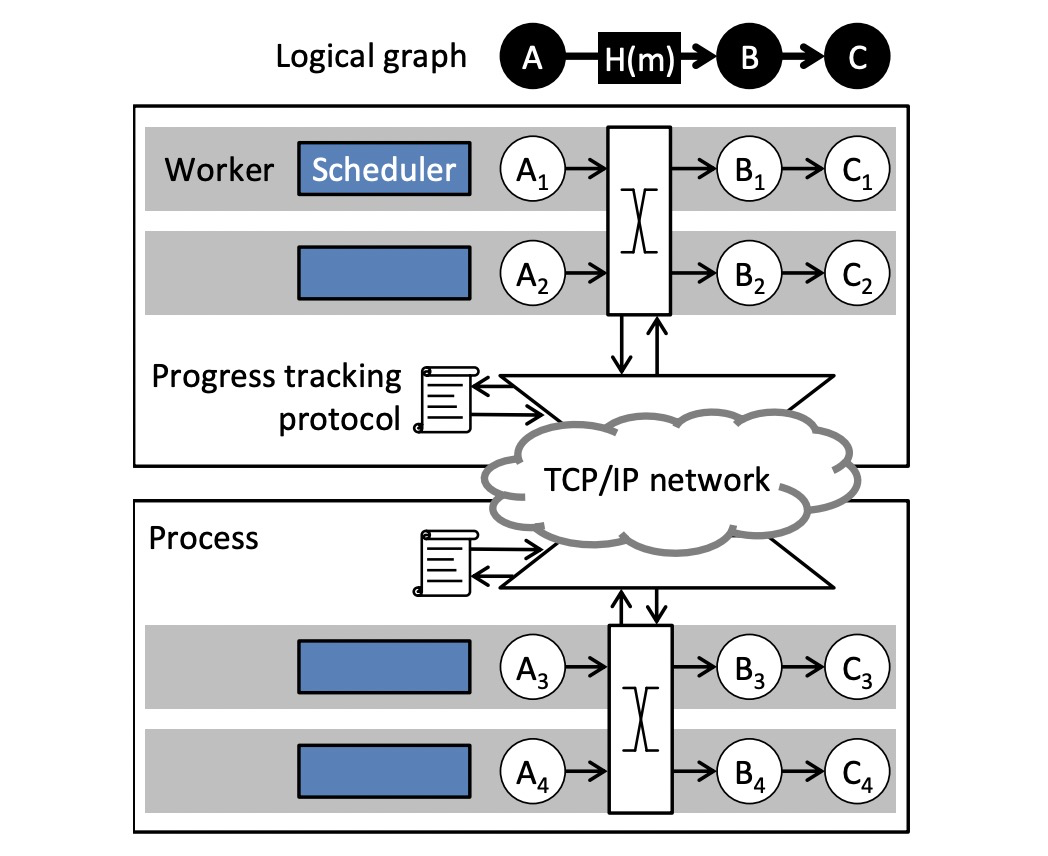
3.1 数据并行
- 逻辑数据流图:stages+connectors。
- connectors包含一个分区函数。
- 运行时逻辑数据流图被展开为物理数据流图,stage被替换为一组节点,connectors被替换为一组边。
3.2 Workers
- 分发消息优先于分发通知。
- 分发策略多样,如基于最早的pointstamp分发降低端到端延迟。
- worker使用共享队列进行通信。
- 如果分发的目标节点在同一个worker,那么SendBy会直接调用目标节点的OnRecieve。
- 如果存在环则需要强制进入队列,或者控制递归深度避免系统过载。
3.3 分布式进度追踪
- 每个worker维护各自的状态,通过广播OC进行状态共享。
- 优化手段:
- 使用映射的pointstamp实现进度跟踪,以降低并发冲突和更新规模。
- 更新广播前先进行本地聚合。
3.4 错误容忍和可用性
- Checkpoint和Restore接口。
3.5 预防抖动
- 网络。
- 数据结构竞争。
- 垃圾回收。
4. 使用Naiad写程序
5. 性能评估
6. 现实应用
- 批量迭代图计算
- 批量迭代机器学习
- 流式无环计算
- 流式迭代图分析
7. 总结
Naiad通过允许程序按需协调,支持了混合的同步+异步计算。
若本文对你有所帮助,您的 关注 和 推荐 是我分享知识的动力!




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2012-07-31 Windows文件操作基础代码
2012-07-31 Windows注册表操作基础代码