搞懂数据结构从这篇文章开始~
数据结构作为编程的基础部分,我一直没有系统的梳理过,之前学的相关知识除了常用的部分,剩下的基本都还给学校了。
最近我准备重新整理一个数据结构的标签,温故知新,在梳理的过程中可能又会体会到很多之前没有想到的东西。
本文梳理的是数据结构的前言部分,也是最基础的部分。虽然基础但是仍然有很多新的东西值得分享,最终整理的目录如下:

一 数据结构中的 C(C++)语言知识
数据结构中的例题大部分都是用 C 语言编写的,要看懂例题,至少要掌握数据类型和函数这两大块的基本概念。
1.1 数据类型
1.1.1 结构型
在数据结构中除了基本的数据类型外,还用到了相对来说复杂一点的结构型。
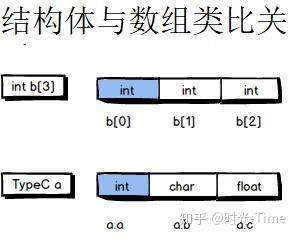
结构型一般指的是使用已有的基本类型(int 、float、double等)或自己创建的结构型重新创建的数据类型,结构型中的数据类型可以不一致。
结构型数据定义方法:
typedef struct { int a; char b; float c; }TypeC;
代码中使用 typedef 关键字定义了名为 TypeC 的结构型数据,可以看到结构型数据可以是一批不同数据类型的集合。
这里以一维数组进行下对比方便理解,数组中的类型都是一致的而结构体中的类型可以不一致:
同样的,结构型的数据也可能组成数组,类比二维数组来看:
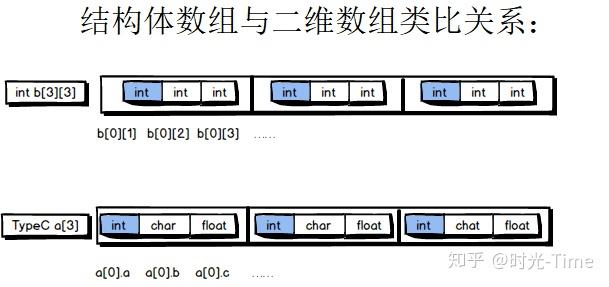
可见结构型数据存储数据更加灵活,获取数据也比较简便。
1.1.2 指针型
指针是 C 语言的灵魂,在 C语言 中可通过指针直接操作内存。对比一下 Java,Java 中是不存在指针的,Java 中只有引用,Java 中引用所指向的其实还是对象,还是需要占用内存的,所以在执行效率上 Java 是不如 C 的。
指针的定义:
int *a; double *b; TypeC *c;
定义非常简单,普通定义的标识符前加一个 * 号就表示了指针。
假设 m 是一个指针变量,并且 m 指向了一个变量 n,那么 m 中存储的就是变量 n 所在的地址,*m 是取变量 n 的内容。
&n 是取 n的地址,m = &n 就是将变量 n 的地址赋值给 m,也就是常说的 指针 m 指向 n。
//用代码表示 将变量 n 赋值给变量 x x = n 等价于 x = *m; (*m就是取变量n的内容)
1.1.3 结点型
结点型数据的构造一般都离不开指针,这里主要看链表和二叉树结点构造:
- 链表
链表结点的定义:
typedef struct Node { int data;//节点的值 struct Node *next;//指向 Node 节点的指针 }Node;
注意:凡是定义的结构型中含有指针型,并且指针型所指向的结构型与本身相同,则需要在定义的结构型的 typedef struct 后加上结点型的名字。上面的 typedef struct Node,这个Node是必须要添加的。
- 二叉树
二叉树节点的定义:
typedef strcut BTNode { int data;//保存数值 struct BTNode *lchild;//指向左子节点 struct BTNode *rchild;//指向右子节点 }BTNode
- 节点的创建
前面定义好了结点,使用结点创建方法比较推荐的是:
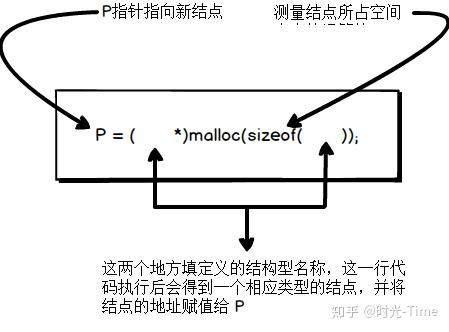
BTNode *BT; BT = ( BTNode *) malloc(sizeof(BTNode)) // 申请内存的固定方式
固定方式为结点空间申请函数:
说明:
malloc () :申请新节点所需内存的方法
sizeof:C 中的关键字,用来计算结点所占用空间大小
BT = ( BTNode *) malloc(sizeof(BTNode))
以上代码执行后,会获取 BTNode 类型的结点,并将结点所在的地址赋值给 BT。如果想获取结点中的内容赋值给 x 变量,应该使用 :
x = BT -> data;
可以看到使用结构体变量获取数据分量,可以使用 ".",而使用指向结构体变量的指针来获取分量,使用 "->"。
那如果就想用 "." 来获取data中的值应该这样写:
x = (*BT).data // 等价于 x= BT-> data
由第二部分指针的内容可以了解到 *BT 其实就是取的它所指向的变量的值,也就是所指向的变量,既然是变量取值那自然是要用 ".", 而 BT 则是表示指针,指针取值要自然要用 "->"。
1.1.4 typedef 和 #define
这两个词一般都是用来给变量起名字用的。
typedef 其实是C 语言中的关键字,意思就是给变量起别名。
#define 其实和 #include 一样,算是预处理指令,预处理又叫预编译,是编译前的步骤,用 #define 一般给标识符定义常量:
#define maxValue 100; // 定义了常量 maxValue 为 100
1.2 函数
函数这部分就比较复杂了,不过在使用函数时要明确最基本的问题,传入函数的参数是否会变化、参数是传值还是传指针(地址)。
1.2.1 传入函数的参数是否会变化
函数传入类型如果传值的话,参数是一般不会改变的,因为传值 函数的形参跟实参实际上是两个变量,相互之间不会影响,比如:
int x = 0; void insert(int y) { y++; // 调用函数后原有的 x 值不会变化 }
但是当传入的不是数值而是地址时:
int x = 0; void insert(int &y) { y++; // 调用函数后原有的 x 值会变化,相当于传入变量的地址 }
当传入的参数是指针类型,并且指针类型需要改变时:
int x = 0; void insert(int *&y) { y++; // 调用函数后 指针 y 值会变化 }
1.2.2 传值还是传引用还是传指针
函数的参数的确定是需要经过考量的,不能一概而论,至于参数类型传值还是传引用还是传指针,需要具体问题具体分析:
比如,我要操作数据,这个时候传引用比较合适:
//数据操作传入值或地址 void insert (dateList &l, int) { //插入操作 }
要操作链表数据, 传指针比较合适:
//链表操作传入整个链表不太合适,可以传入链表的头指针 int searchAndDelete(LNode *C,int x){ //链表操作 }
二 时间复杂度和空间复杂度
2.1 时间复杂度
时间复杂度是将算法的基本操作次数作为度量。
因此识别算法中哪些为基本操作,并计算出基本操作次数,最后计算出时间复杂度。
2.2 空间复杂度
空间复杂度是指算法在运行时所需存储空间的度量。需要根据不同类型数据结构进行不同的判断。
关于时间复杂度和空间复杂度,之前我也有一篇详细的介绍 :)
三 数据结构和算法的基本概念
3.1 数据结构的基本概念
数据结构包含3方面的内容:逻辑结构、存储结构和对数据的运算。
- 逻辑结构
逻辑结构是指数据间的逻辑关系,与数据的存储结构无关,同一种逻辑结构可能有多种存储结构。
逻辑结构分为 线性结构 与 非线性结构。
线性结构是指数据元素之间存在着 “一对一”的线性关系,如数组、单链表等。
非线性结构的结点中存在着一对多的关系,又可以分为树形结构与图形结构。
- 存储结构
一般在数据结构中有4种常用的存储方法:顺序存储、链式存储、索引存储、散列存储。
顺序存储:逻辑上相邻的结点存储在物理上相邻的存储单元中,结点间的逻辑关系由存储单元的邻接关系来体现。
链式存储:逻辑上相邻的结点不要求物理存储也相邻,结点间的逻辑关系由附加的指针字段表示。
索引存储:索引存储在存储时除建立存储结点信息外,还要建立附加的索引表来标识结点位置。
散列表存储(Hash存储):根据结点的关键字通过散列函数计算出结点的存储地址。
3.2 算法的基本概念
计算机的算法指的是解决问题的步骤序列,可以理解为由基本运算和规定的运算顺序所构成的完整的解题步骤。
算法的特性:有穷性、确定性、输入、输出、可行性。
关于算法这里也有一些简单的例子:
坦白的说数据结构和算法本文仅仅是提了个简单的概念,在后面各个章节的分享中会逐步深入。
数据结构和算法是程序的灵魂,无论架构框架怎么变,这些灵魂的东西是不会变的,所以理解它们也就显得尤为重要。
![]()
-- The End --

 浙公网安备 33010602011771号
浙公网安备 33010602011771号