

实时计算引擎 Flink - 基础篇
Flink 做为第三代实时计算引擎以其独特的优势已经被广泛使用,它的实时计算能力确实值得称赞,本文先从基础架构与资源管理方面对其图文梳理,后续会逐渐深入了解并做部分实际应用。
1 基础架构
无论是从集群模式还是内部角色划分来看Flink 与 Spark 都比较类似,Spark 我们比较熟悉,可以对照 Spark 进行同步学习:
1.1 集群模式
Flink 的集群模式也是分为 Local 、Standalone、Yarn 这三种。Flink 集群搭建非常简单,只需要下载安装包解压即可。
Yarn 模式不用做任何配置,只需要导入一个依赖包 :
flink-shaded-hadoop-2-uber-2.7.5-10.0.jar
即可运行在Yarn上,比 Spark On Yarn 还要简单,堪称零配置。
当然实际中比较常用的还是 Yarn 模式。而在调试过程中 Local 模式比较常用, Flink Local 模式还自带了 WebUI,只要引入以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.11</artifactId>
<version>1.9.0</version>
</dependency>
啥也不用配置就能看见 Flink 的管理页面了,简直太方便了:
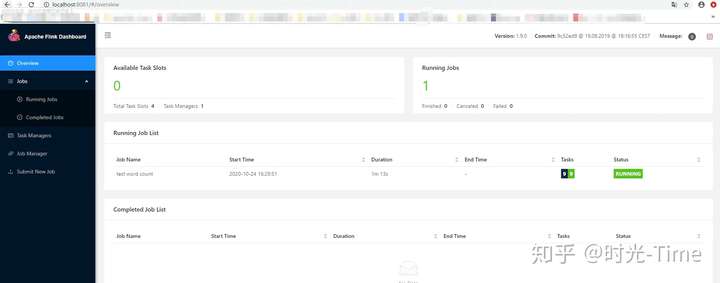
1.2 角色划分
Flink 跟 Spark 类似也是主从架构,分为 JobManager (JM) 和 TaskManager (TM)。
JM 对应 Spark 的 Master 角色,作为资源的统一分配的管理者;
TM 对应 Spark 的 Slave 角色,作为具体任务执行和对应任务在每个节点上的资源管理,TM 上会执行具体的任务。
2 资源管理
资源管理我们着重看下 Flink On Yarn 的资源调度方式,与其他运行在 Yarn 上的任务类似,简单流程图:
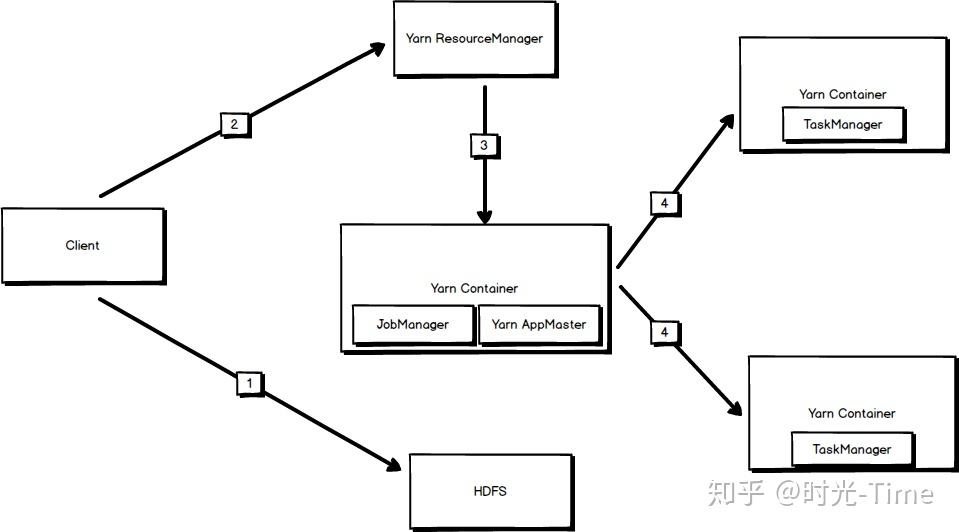
当执行 Flink On Yarn 任务时:
1 执行客户端 首先将执行所需要的 jar 包 和配置文件提交到 HDFS
2 提交完成后,客户端向 ResourceManager 申请任务资源并且申请 启动 AppMaster
3 Yarn Container 中启动AppMaster,并且启动 Flink 主节点 JobManager
4 JobManager 申请启动 TaskManager 执行具体任务
5 TM 执行具体任务,并向 JobManager 汇报进度
最后任务执行结束后申请注销资源。
2.1 Flink On Yarn 推荐方式
Flink On Yarn 模式有两种:
1 首先在 Yarn 上申请一套 Flink 集群资源,当有Flink 任务执行时运行在此套集群中,任务结束后,申请的Flink 集群仍然存在。(不推荐使用)
2 当提交 Flink 任务时才去 Yarn 上申请集群资源并运行任务,任务运行结束后,资源释放。(推荐使用)
2.2 并行度&Solt&Task
要想深入理解 Flink ,并行度、Solt、Task之间的关系必须整理清楚。
- 并行度,顾名思义就是任务并行的程度。
对于 Spark 而言,并行度可能不太好确定,Spark 并行度指的是各个 stage 的 Task 的数量,Task 的数量则需要分区数来确定,而分区数又要用到分区规则。
Flink 的并行度则是每个算子中自带的方法,比如 map、sum等算子,我们可以手动执行并行度。当然 Spark 也可以通过参数 spark.defalut.parallelism 来指定并行度。
Flink 并行度的设置方式有 4 种,分别是 算子层次、执行环境层次、客户端层次、系统层次,越往后优先级越低,一般算子层次用的比较多。
- Solt
Solt 其实就是 Cpu 核数,在 Flink 中 ,TM 会为集群提供 Solt ,一般情况下 Solt数就是每个 TM 节点的 cpu 核数。
- Task
Task 是实际执行任务的线程,这个和 Spark 中的 Task 概念类似。
三者的关系如图所示:
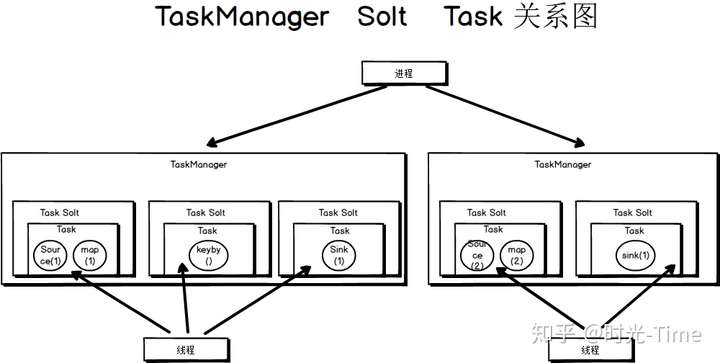
- 一个 TaskManager 可以有多个 Solt
- 一个 Solt 只有一个 Task
- 一个Task 可以有多个算子
- Operator Chain
从图中我们可以看出,一个 Task 中其实是可以运行多个算子的,这是怎么回事呢?
这其实是 Flink 帮我们做的优化工作,当几个算子的并行度一致时,Flink 会将这几个算子合并为一个 Task 去执行,这种现象就叫做 Operator Chain 。
我们可以看到 Operator Chain 的前提就是算子的并行度一致,那么当并行度都一致时 Task 中数据传输方式是一对一的,所以就可以合并处理了。
Flink 中 Task 数据传输的方式:
a.一对一传输(forward strategy )
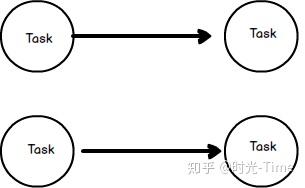
- 一个 Task 的输出只发送给一个 Task作为输入
- 如果两个 Task 都在一个 JVM 中的话,那么就可以避免网络开销
b. shuffle方式传输(key based strategy)
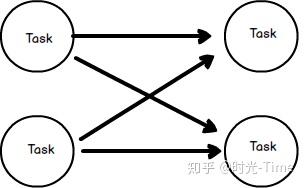
- 数据需要按照某个属性(我们称为 key)进行分组(或者说分区)
- 相同 key 的数据需要传输给同一个 Task,在一个 Task中进行处理
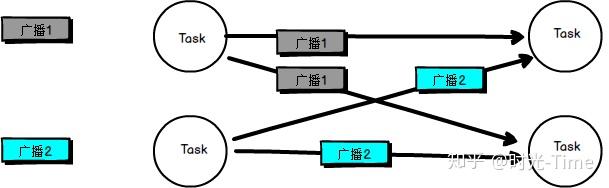
c. 广播方式传输(broadcast strategy)
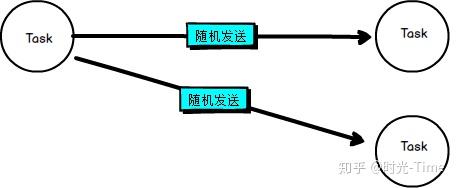
d.随机传输 (random strategy)
以上我们了解了 Flink 的基础架构与资源管理方面的知识,后面更我们会深入的解析 Flink 状态、窗口等机制,可以看到 Flink 确实做了很多优化,相信 Flink 会越来越流行。
