

Hadoop压缩的图文教程
近期由于Hadoop集群机器硬盘资源紧张,有需求让把 Hadoop 集群上的历史数据进行下压缩,开始从网上查找的都是关于各种压缩机制的对比,很少有关于怎么压缩的教程(我没找到。。),再此特记录下本次压缩的过程,方便以后查阅,利己利人。
本文涉及的所有 jar包、脚本、native lib 见文末的相关下载 ~
我的压缩版本:
Jdk 1.7及以上
Hadoop-2.2.0 版本
压缩前环境准备:
关于压缩算法对比,网上资料很多,这里我用的是 Bzip2 的压缩方式,比较中庸,由于是Hadoop自带的压缩机制,也不需要额外下载别的东西,只需要在 Hadoop根目录下 lib/native 文件下有如下文件即可:
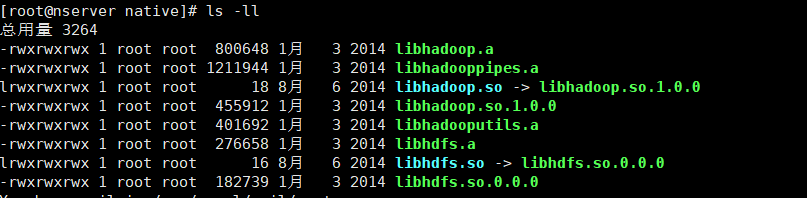
压缩之前要检查 Hadoop 集群支持的压缩算法: hadoop checknative
每台机器都要检查一下,都显示如图 true 则说明 集群支持 bzip2 压缩,
如果显示false 则需要将上图的文件下载拷贝到 Hadoop根目录下 lib/native

压缩程序介绍:
压缩程序用到的类 getFileList(获取文件路径) 、 FileHdfsCompress(压缩类)、FileHdfsDeCompress(解压缩类) ,只用到这三个类即可完成压缩/解压缩操作。
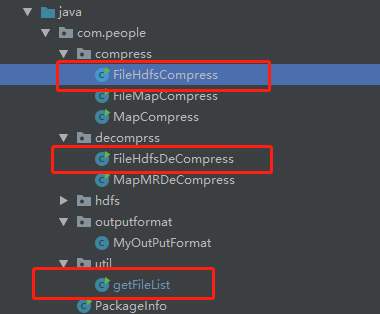
getFileList 作用:递归打印 传入文件目录下文件的根路径,包括子目录下的文件。开始想直接输出到文件中,后来打包放到集群上运行时,发现文件没有内容,可能是由于分布式运行的关系,所以就把路径打印出来,人工在放到文件中。
核心代码:
public static void listAllFiles(String path, List<String> strings) throws IOException {
FileSystem hdfs = getHdfs(path);
Path[] filesAndDirs = getFilesAndDirs(path);
for(Path p : filesAndDirs){
if(hdfs.getFileStatus(p).isFile()){
if(!p.getName().contains("SUCCESS")){
System.out.println(p);
}
}else{
listAllFiles(p.toString(),strings);
}
}
// FileUtils.writeLines(new File(FILE_LIST_OUTPUT_PATH), strings,true);
}
public static FileSystem getHdfs(String path) throws IOException {
Configuration conf = new Configuration();
return FileSystem.get(URI.create(path),conf);
}
public static Path[] getFilesAndDirs(String path) throws IOException {
FileStatus[] fs = getHdfs(path).listStatus(new Path(path));
return FileUtil.stat2Paths(fs);
}
FileHdfsCompress:压缩程序非常简单,对应程序里的 FileHdfsCompress 类,(解压缩是 FileHdfsDeCompress),采用的是Hadoop 原生API ,将Hadoop集群上原文件读入作为输入流,将压缩路径的输入流作为输出,再使用相关的压缩算法即,代码如下:
核心代码:
//指定压缩方式
Class<?> codecClass = Class.forName(COMPRESS_CLASS_NAME);
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec)ReflectionUtils.newInstance(codecClass, conf);
// FileSystem fs = FileSystem.get(conf);
FileSystem fs = FileSystem.get(URI.create(inputPath),conf);
//原文件路径 txt 用原本的输入流读入
FSDataInputStream in = fs.open(new Path(inputPath));
//创建 HDFS 上的输出流,压缩路径
//通过文件系统获取输出流
OutputStream out = fs.create(new Path(FILE_OUTPUT_PATH));
//对输出流的数据压缩
CompressionOutputStream compressOut = codec.createOutputStream(out);
//读入原文件 压缩到HDFS上 输入--普通流 输出-压缩流
IOUtils.copyBytes(in, compressOut, 4096,true);
以下是代码优化的过程,不涉及压缩程序使用,不感兴趣同学可以跳过 ~ :
在实际编码中,我其实是走了弯路的,一开始并没有想到用 Hadoop API 就能实现压缩解压缩功能,代码到此其实是经历了优化迭代的过程。
最开始时压缩的思路就是 将文件读进来,再压缩出去,一开始使用了 MapReduce 的方式,在编码过程中,由于对生成压缩文件的路径还有要求,又在 Hadoop 输出时自定义了输出类来使的输出文件的名字符合要求,不是 part-r-0000.txt ,而是时间戳.txt 的格式,至此符合原线上路径的要求。
而在实际运行过程中发现,MR 程序需要启动 Yarn,并占用Yarn 资源,由于压缩时间较长,有可能会长时间占用 集群资源不释放,后来发现 MR 程序的初衷是用来做并行计算的,而压缩仅仅是 map 任务读取一条就写一条,不涉及计算,就是内容的简单搬运。所以这里放弃了使用 MR 想着可不可以就用简单的 Hadoop API 就完成压缩功能,经过一番尝试后,发现真的可行! 使用了 Hadoop API 释放了集群资源,压缩速度也还可以,这样就把这个压缩程序当做一个后台进程跑就行了也不用考虑集群资源分配的问题。
实测压缩步骤:
1 将项目打包,上传到hadoop 集群任一节点即可,准备好相应的脚本,输入数据文件,日志文件,如下图:

2 使用获取文件路径脚本,打印路径:
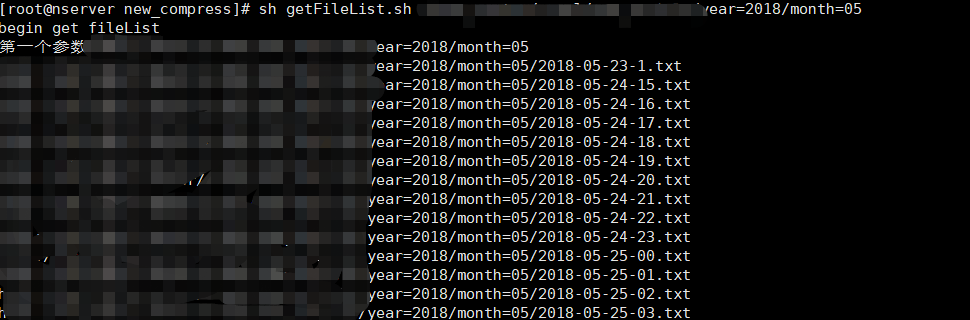
getFileLish.sh 脚本内容如下,就是简单调用,传入参数为 hadoop集群上 HDFS 上目录路径:
#!/bin/sh echo "begin get fileList" echo "第一个参数$1" if [ ! -n "$1" ]; then echo "check param!" fi #original file hadoop jar hadoop-compress-1.0.jar com.people.util.getFileList $1
3 将 打印的路径 粘贴到 compress.txt 中,第 2 步中会把目录的文件路径包括子目录路径都打印出来,将其粘贴进 compress.txt 中即可,注意 文件名可随意定。
4 使用压缩脚本即可,sh compress.sh /data/new_compress/compress.txt ,加粗的部分是脚本的参数意思是 第3步中文件的路径,注意:这里只能是绝对路径,不然可能报找不到文件的异常。

compress.sh 脚本内容如下,就是简单调用,传入参数为 第3步中文件的绝对路径:
#!/bin/sh echo "begin compress" echo "第一个参数$1" if [ ! -n "$1" ]; then echo "check param!" fi hadoop jar hadoop-compress-1.0.jar com.people.compress.FileHdfsCompress $1 >> /data/new_compress/compress.log 2>&1 &
5 查看压缩日志,发现后台程序已经开始压缩了!,tail -f compress.log

6 如果感觉压缩速度不够,可以多台机器执行脚本,也可以一台机器执行多个任务,因为这个脚本任务是一个后台进程,不会占用集群 Yarn 资源。
相关下载:
程序源码下载: git@github.com:fanpengyi/hadoop-compress.git
Hadoop 压缩相关需要的 脚本、jar包、lib 下载: 关注公众号 “大数据江湖”,后台回复 “hadoop压缩”,即可下载

长按即可关注
--- The End ---
