结对二
一、作业基本信息
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对作业二 |
| 结对学号 | 221801205 221801234 |
| 这个作业的目标 | 1、实现论文网站 2、体会结对编程 3、学会利用Github协作 |
二、主要内容
1、git仓库链接和代码规范链接
1)Github链接:https://github.com/gz321/PairProject
2)代码规范链接:https://github.com/gz321/PairProject/blob/main/codestyle.md
2、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 10min | 10min |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 120min | 120min |
| • Design Spec | • 生成设计文档 | 10min | 10min |
| • Design Review | • 设计复审 | 20min | 20min |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20min | 20min |
| • Design | • 具体设计 | 20min | 30min |
| • Coding | • 具体编码 | 1800min | 2100min |
| • Code Review | • 代码复审 | 30min | 20min |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120min | 60min |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30min | 15min |
| • Size Measurement | • 计算工作量 | 10min | 5min |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 120min | 60min |
| 合计 | 2150min | 2470min |
3、项目访问链接
http://39.102.39.208/crawler_war/static/html/
4、成品展示
- 首页
- 查询等待(图例为点击关键词图谱中的关键词后跳转)
- 查询
- 表内查询
- 论文详情

- 关键词图谱
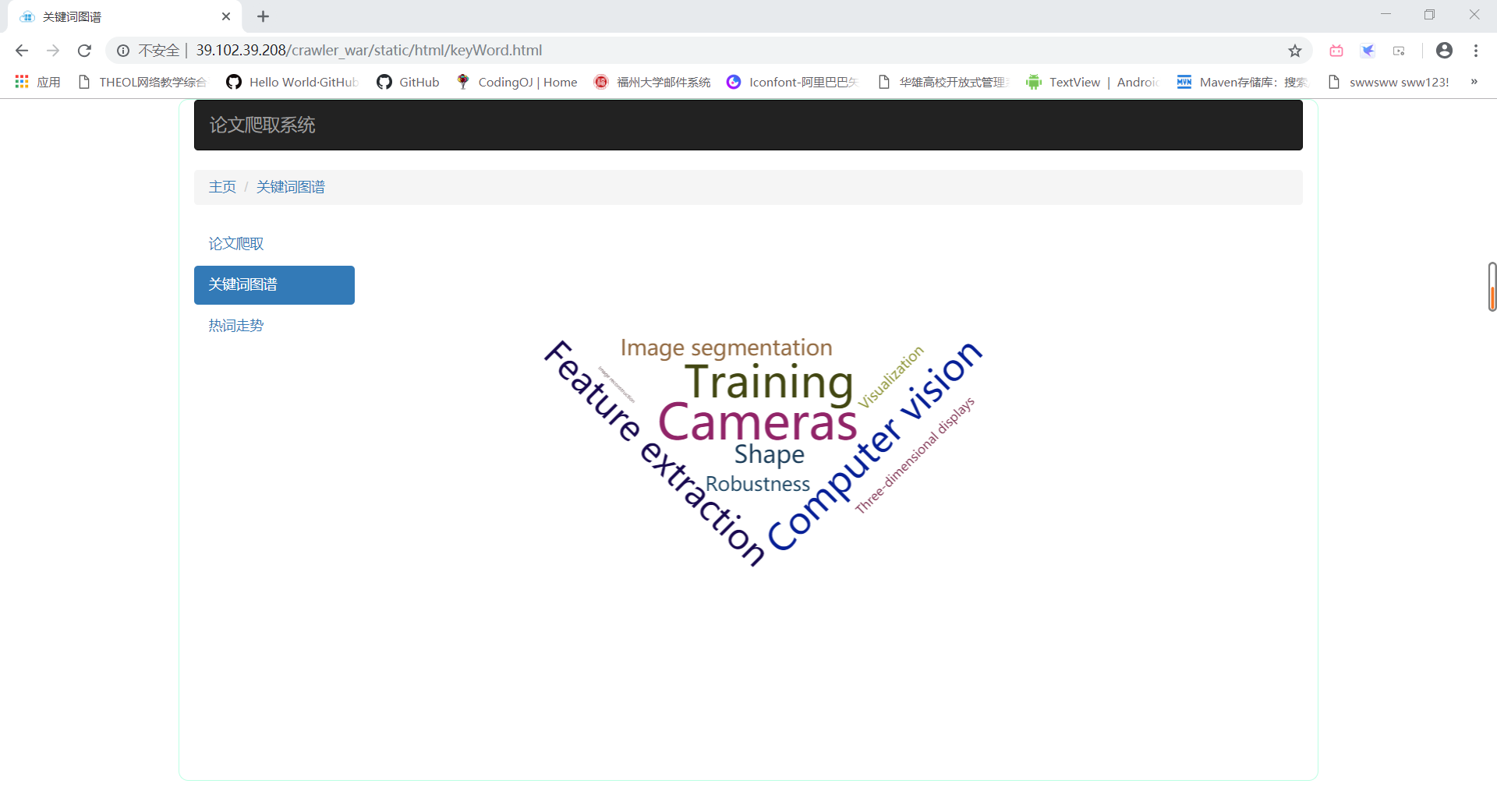
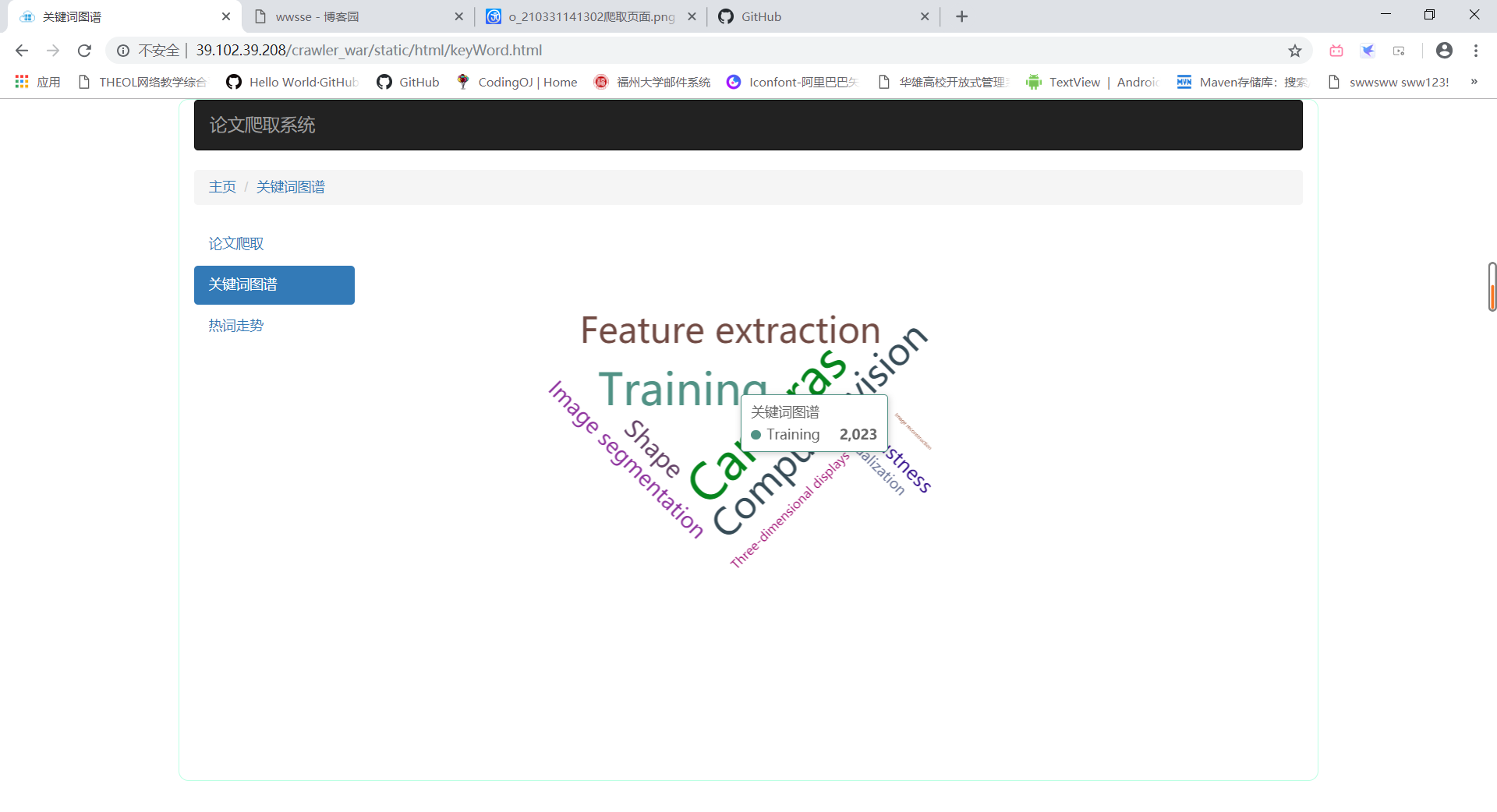
- 点击关键词跳转
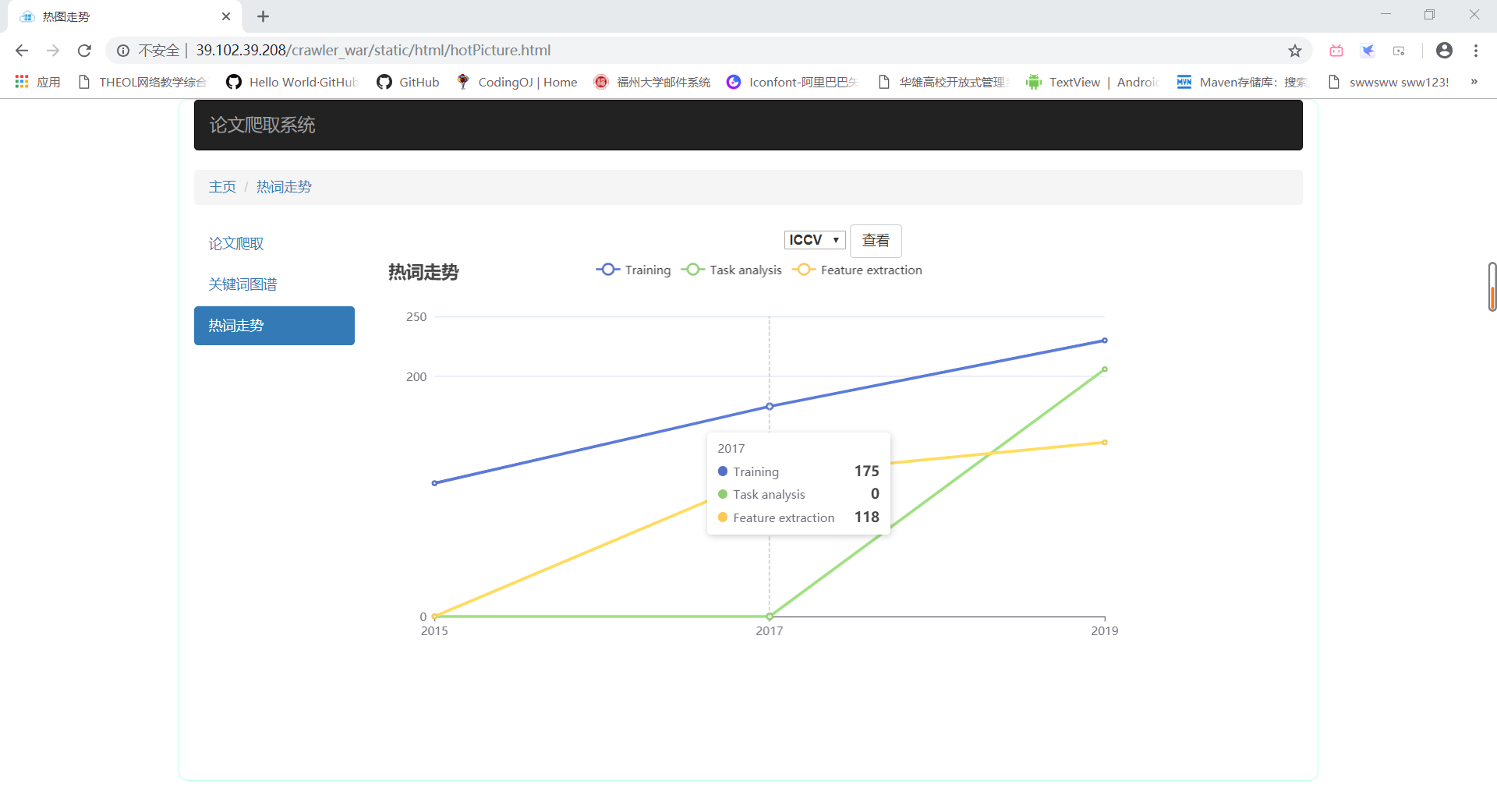
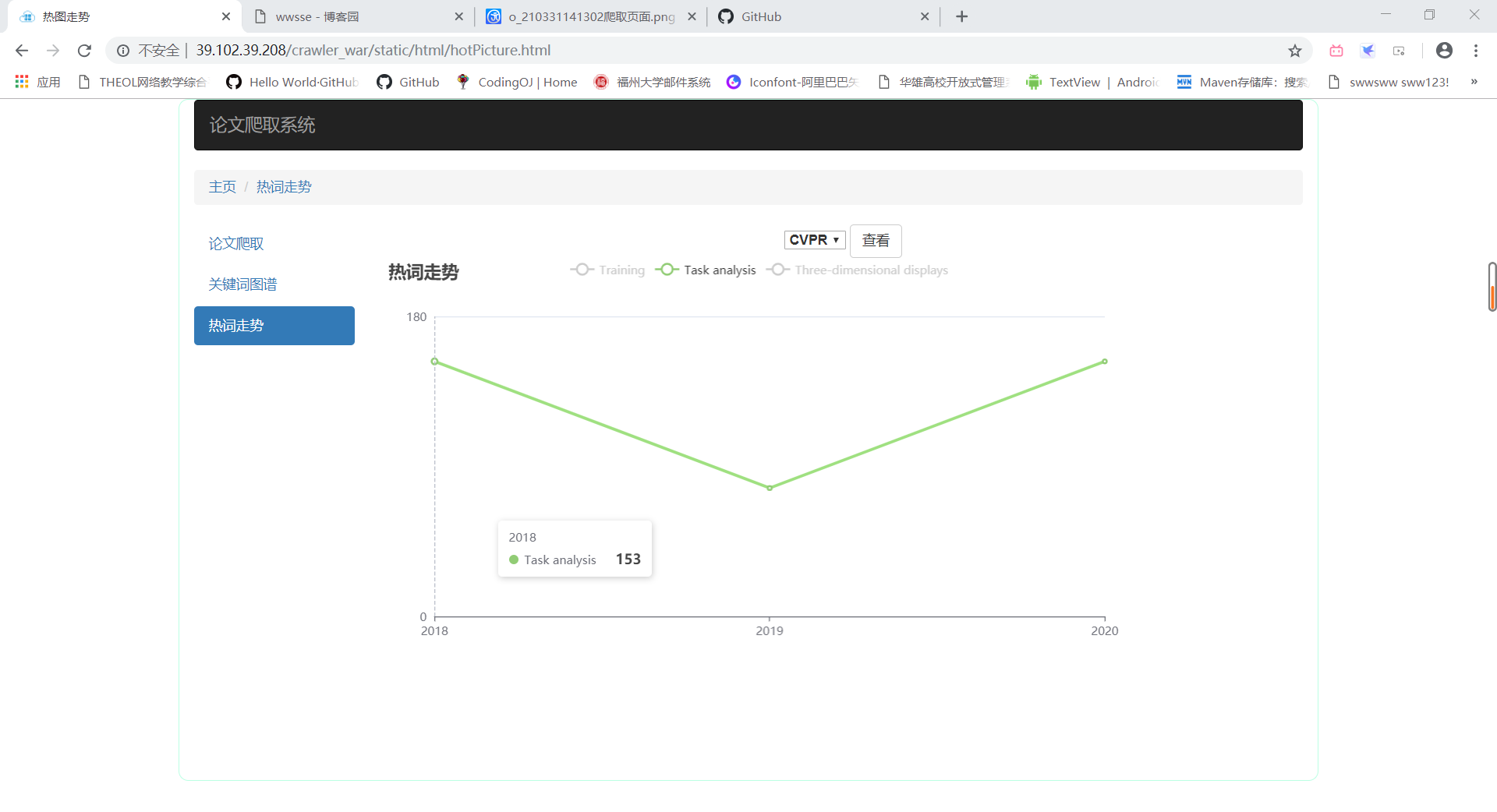
- 热词走势
- 选择会议
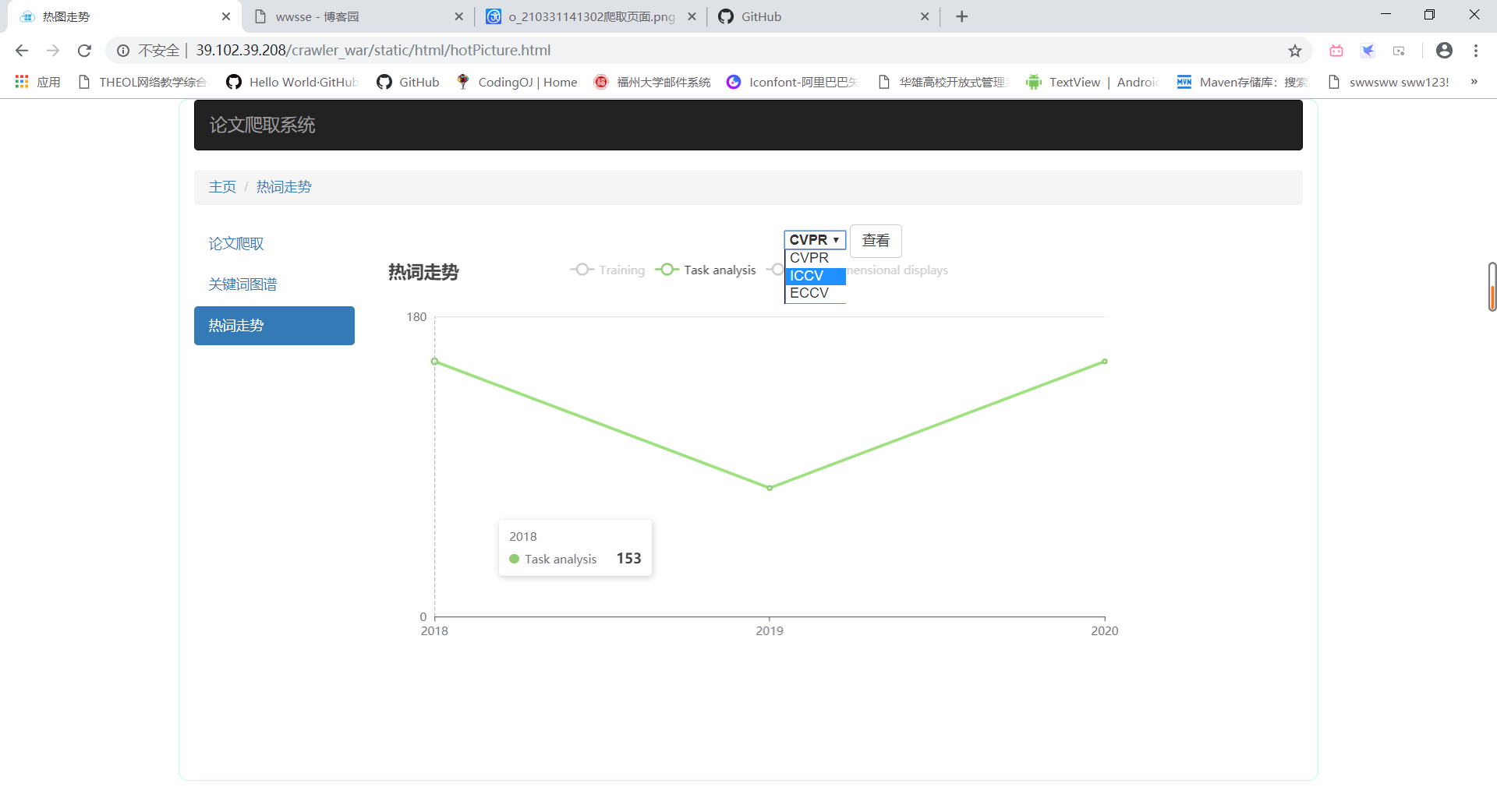
- 显示某条折线
5、结对讨论过程描述
1)讨论过程描述:
由于这次作业是上次结对原型作业的后续,因此我们对需求都有了一定了解,在重新看过一遍要求之后,我们分工好了前后端的工作。因为刚上过JavaEE的课程,因此决定用Java实现后端功能,前端则用vue框架实现。我们首先对需求进行解析,分出一个个页面功能。数据方面我们起先想要用Jsoup和Htmunit实现爬虫从论文网站上爬取,但中途受阻(难以解析js页面),于是改为使用助教提供的数据,之后就是一个个功能的实现。
2)结对讨论过程截图:


6、设计实现过程
1)实现过程描述:
后端部分:
首先设计数据库,在爬虫受阻后编写读取文件代码,解析json文件并编写util、bean和dao类,对数据库进行数据填充,然后根据功能完善dao类,最后编写与前端进行交互的servlet类,经过在团队实战时助教的建议,将数据库连接信息写到了配置文件中。
前端部分:
首先根据原型界面设计页面的基本样式,使用html与css做出大致页面,在网络图标库找必要的素材资源。使用echarts与echarts-cloud设计图表的样式。使用vue进行页面动态部分的实现与数据的渲染,使用axios进行前后端的交互。
前后端完成后部署项目,进行bug的修改,删除不必要的功能,并增加新功能
2)功能结构图:

7、代码说明
后端:
1)数据库设计了三张表:paper、keywords、name_keyword
paper(name,year,meeting,abstract,url,accesstimes):用于存储论文的主要信息。
keywords(keyword,appeartimes):用于记录关键词及其出现次数。
name_keyword(name,keyword):由于论文和关键词是多对多关系,需要一张关联表。
2)JDBCUtil类:用于获取数据库连接对象
读取配置文件信息:
try { pro.load(JDBCUtil.class.getClassLoader().getResourceAsStream("config.properties"));
} catch (IOException e) {
e.printStackTrace();
}
driver = pro.getProperty("driver");
loginName = pro.getProperty("loginName");
password = pro.getProperty("password");
url = pro.getProperty("url");
建立数据库连接池:池中连接数大于0,则返回池中连接,否则新建连接
if (pool.size() > 0) {
return pool.removeFirst();
} else {
Connection con = null;
try {
con = DriverManager.getConnection(url, loginName, password);
} catch (SQLException e) {
e.printStackTrace();
}
return con;
}
3)Servlet类:用于处理前端请求,并回复,请求和回复用json封装。
取得请求:
String reqString = request.getReader().readLine();
回复:
response.getWriter().write(resString);
其中:
KeywordAndCount类:返回给前端出现次数前十的关键词及其出现次数(用于关键词图谱显示)
MeetingWordTrend类:返回给前端三大会议在最后一年里出现次数前三的关键词在三年里的出现次数(用于热词走势的显示)
PaperListByKeyword类:前端提供关键词,返回前端包含该关键词的论文(用于点击关键词图谱,返回论文列表)
PaperListByTitle类:前端提供论文标题,返回前端包含该标题内容的论文(用于论文查询,支持模糊查询)
PaperListDetailByTitle类:前端提供论文完整标题,返回前端该论文的完整信息(用于查看文章详细信息功能)
4)message类:用于处理论文的json文件,将信息存储到数据库
因为json文件前后有空格,所以用trim()处理,会议:ICCV和CVPR的json文件最后含有“;”号,无法被JSONObject.parseObject()函数解析,因此用substring取出最后一个“;”。
json = json.trim();
json = json.substring(0, json.length()-1);
5)dao类:对数据库进行增加和查询操作。
6)bean类:数据对象类,一张数据表对应一个bean。
前端:
每一个页面对应一个html一个css和一个js文件,html基本使用bootstarp样式,js使用vue.js,axios.js,echart.js
- 关键代码
论文列表实现
使用v-for v-model指令,vue通过后端返回的json数组进行数据的渲染
使用两张图片,一张蓝色,一张灰色做出按钮的效果
使用@click给图片添加点击事件
<table class="table">
<thead>
<tr>
<th>
<span>题名</span>
</th>
<th>
<span>会议名称</span>
</th>
<th>
<span>发表时间</span>
</th>
<th>
<span>关键词</span>
</th>
<th>
<span>查看</span>
</th>
<th>
<span>删除</span>
</th>
</tr>
</thead>
<tbody class="listContent">
<tr class="clone1" v-for="todo,index in tp">
<td class="title">{{todo.name}}</td>
<td class="meeting">{{todo.meeting}}</td>
<td class="date">{{todo.year}}</td>
<td class="keyWord">{{todo.keywords}}</td>
<td class="see" v-show="true">
<img alt="" src="../img/see.png" onmouseover="this.src='../img/see_.png'"
onmouseout="this.src='../img/see.png'" @click="send(todo.name)" /></td>
<td class="delete_btn" v-show="true">
<img alt="" src="../img/delete.png" onmouseover="this.src='../img/delete_.png'"
onmouseout="this.src='../img/delete.png'" @click="deleteD(index)"/>
</td>
</tr>
</tbody>
</table>
前端发送请求
采用axios进行异步发送请求
var that= this;
/**
* 访问路径 后端端口路径
* data 向后端发送的数据
* type 设置置HTTP报文请求头等信息
*/
axios.post(url,data,type).then(function (response) {
//接收response数据,自动转换为json对象,放入list中
that.list = response.data;
}).catch(function (error) {
//异常处理
console.log(error);
});
页面跳转
前端比较简单,只采用简单方式进行跳转
window.location.href = url + "?" + "params" + "=" + params;
window.open(url + "params" + "=" + params);
爬虫
由于两个人不熟悉web,没学过爬虫,时间比较急,所以只是写了ICCV和CVPR两个网站的爬取,使用WebCollector框架
public class AutoNewsCrawler extends BreadthCrawler {
private int id=0;
String s;
int year;
String meeting;
String seed1;
String seed2;
private ArrayList<Paper> papers;//临时存取爬出的数据
/**
* 构造函数
* @param crawlPath crawl
* @param autoParse true
* @param year 爬取文献的年份
* @param meeting 爬取的会议名称
* @param cnt 爬取论文数量
*/
public AutoNewsCrawler(String crawlPath, boolean autoParse,int year,String meeting,int cnt) {
super(crawlPath, autoParse);
this.year=year;
this.meeting="ICCV";
this.seed2="https://dblp.uni-trier.de/db/conf/cvpr/cvpr"+year+".html";
this.seed1="https://dblp.uni-trier.de/db/conf/iccv/iccv"+year+".html";
papers = new ArrayList<>();
if("ICCV".equals(meeting))
this.addSeed(seed1);
else this.addSeed(seed2);
this.addRegex("https://doi.org/[0-9]*.[0-9]*/"+meeting+".[0-9]*.[0-9]*");
getConf().setConnectTimeout(3000);
setThreads(50);
getConf().setTopN(100);
}
@Override
public void visit(Page page, CrawlDatums next) {
String url = page.url();
System.out.println(url);
if (page.matchUrl("https://doi.org/[0-9]*.[0-9]*/" + meeting + ".[0-9]*.[0-9]*")) {
try (BufferedReader reader = new BufferedReader(new StringReader(page.html()))) {
while ((s = reader.readLine()) != null) {
s = s.trim();
if (s.length() != 0 && s.contains("xplGlobal.document.metadata")) {
papers.add(new Paper(s, year, meeting, url));
}
}
} catch (Exception e) {
e.printStackTrace();
}
id++;
if (id > 300) {
this.stop();
}
}
}
/**
* 爬虫运行方法
* @param year 爬取年份
* @param meeting 爬取会议
* @param cnt 爬取论文数量
* @return 数据列表
* @throws Exception
*/
public static ArrayList<Paper> run(int year,String meeting,int cnt) throws Exception{
AutoNewsCrawler crawler = new AutoNewsCrawler("crawl", true,year,meeting,0);
crawler.start(3);
return crawler.papers;
}
//测试
public static void main(String[] args) throws Exception {
System.out.println(JSONObject.toJSONString(run(2015, "ICCV", 10)));
}
}
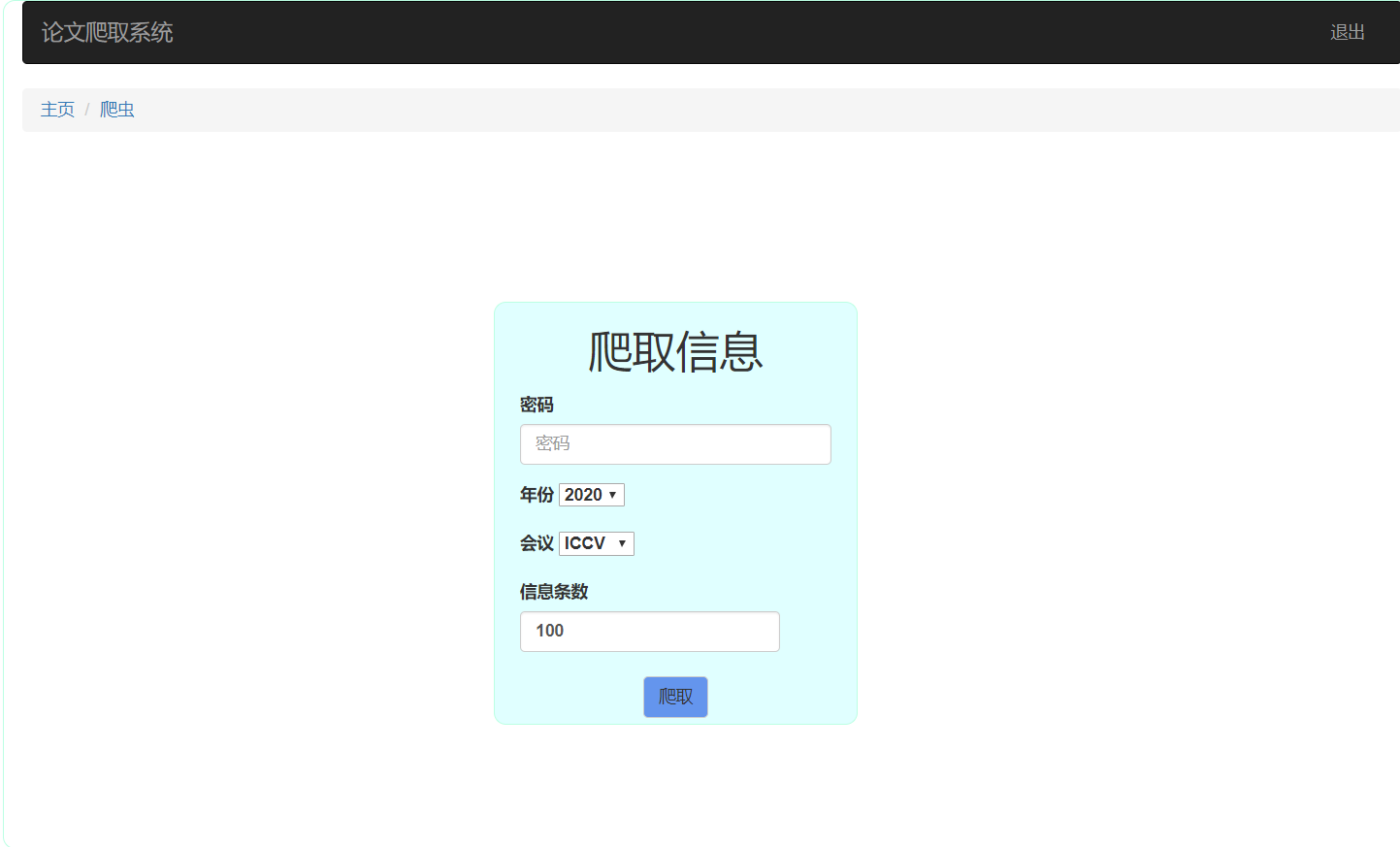
由于servlet上不能运行爬虫(现在还没找到原因)下面的页面与servlet的功能在服务器不能体现
前端页面
seek.html
后端代码
计划采用将爬到的数据存入文件,通过文件下载的方式获取
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String reqString = req.getReader().readLine();
JSONObject reqJson = JSONObject.parseObject(reqString);
String s = null;
String meeting = (String) reqJson.get("meeting");
String pwd = (String) reqJson.get("pwd");
int count = (int) reqJson.get("count");
int year = (int) reqJson.get("year");
if(pwd.equals("123456"))
try {
s = JSONObject.toJSONString(AutoNewsCrawler.run(year, meeting, count));
String filename = "paper.txt";
resp.setHeader("content-disposition", "attachment;filename=" + filename);
resp.setContentType("application/octet-stream");
FileOutputStream out1 = new FileOutputStream(this.getServletContext().getRealPath("static/temp/paper.txt"));
out1.write(s.getBytes());
FileInputStream in = new FileInputStream(this.getServletContext().getRealPath("static/temp/paper.txt"));
int len = 0;
byte buffer[] = new byte[1024];
OutputStream out = resp.getOutputStream();
while ((len = in.read(buffer)) > 0) {
out.write(buffer, 0, len);
//System.out.println(len);
}
in.close();
} catch (Exception e) {
System.out.println("end...");
e.printStackTrace();
}
}
更多相关代码访问GitHub
8、心路历程和收获
1)221801205:
心路历程:
刚开始爬虫功能是由我编写的,起初看到b站上有关于javaweb利用jsoup爬虫的视频教程,跟着学了一会,便开始编码了,但是读取到原文网站后,发现网站的信息是使用js动态生成的(后来搭档做爬虫时告诉我不用解析js只看html就可以读取到想要的信息),通过百度知道了Htmlunit可以解析js页面,但是一直无法成功,网上也没有完整的教程,想到可能是网站本身的反爬机制,考虑到可能无法爬取,就放弃了爬虫。再来是关于javaweb,这学期刚开的课,此前还没有独立开发过web应用(上学期学的yii框架,只跟着视频做了一遍,没有掌握),通过这次的作业将所学应用于实践,也算有所收获。
收获:
实践了javaweb,了解了一些爬虫的知识,学会部署服务器,明白自己还有许多做的不够的地方。
2)221801234:
心路历程:这次结对作业一开始担心做不出来,因为我没写过前端代码,队友也没写过后端代码,花了很多时间进行学习,不过总算是坚持下来了。虽然我们做的十分简单(简陋),不过也是这段时间学习web知识后的一次实战,我还是挺开心的。甚至产生错觉:感觉审美提升了耶
收获:这次作业算是小,但是也算是较为完整的web项目。既熟悉了前端的样式,学习了bootstrap样式的使用,也了解了前后端交互,感受到了web的独特魅力,不需要下载软件,只要一个url就可以访问。这次结对虽然很累,但是收获颇丰。痛并快乐着!
9、评价结对队友
1)221801205:
234的实践经验比较多,因为他做后端的经验较多,所以这次由我担任后端,然后他去学习了vue框架做前端,在后端编程里我有许多做的不好的地方,他都会补上,比如请求和响应信息的编码问题,他编写了filter编码和解码,我有不懂的问题也可以请教他,是一位可靠的搭档。
2)221801234:
205认真严谨,在做交互测试的时候后端没有大问题;平时积极讨论,给我提出了很多的前端页面的建议,使页面更简洁方便;积极学习新技术,同时解决了部署,配置等等的难题

