寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|S |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 重读构建之法 学会GitHub简单使用 学习单元测试 完成词频统计编程 |
| 参考文献 | 《构建之法》 ... |
part1:阅读《构建之法》并提问
Q1 不同用户需求矛盾时如何处理?
什么是Bug呢?简单地说,软件的行为和用户的期望值不一样,就叫Bug。是否是Bug,取决
于用户、开发者的不同角度。
对于一个程序某个功能,有的人认为是bug,影响个人使用,有的人认为这个功能不错。如何取舍呢,根据用户比例吗?
个人认为一是根据用户比例,二是根据实现完善该功能所需要的时间成本,难度,三是根据未来的发展趋势进行取舍
Q2 敏捷流程发生人员变动怎么办?
在冲刺阶段,外部人士不能直接打扰团队成员。一切交流只能通过Scrum大师( Scrum
Master)来完成。这一措施较好地平衡了“交流”和“集中注意力”的矛盾。有任何需求的改
变都留待冲刺结束后再讨论。
一个团队自然会碰到离职,请假等,敏捷流程要求“冲刺”,但人员变动影响原来任务的分配,其次,缺人手后新人加入也会带来问题,给其他人带来压力,这种情况下如何“冲刺”呢?
个人认为敏捷开发一开始应该比预期人数多安排一个至两个,团队领导也要注意队员的沟通问题,缓解压力
Q3 每次软件版本更迭都需要需求分析吗?
软件团队需要找到软件的利益相关者,了解和挖掘他们对软件的需求,引导他们表达出
真实的需求。不同的项目需要不同的手段,这一步骤也被叫做“需求捕捉”,形容真正的
需求稍纵即逝,需要靠火眼金睛和敏捷的身手来发现并抓住它们。
随着软件的不断发展,用户量不断增加,当这个软件越来越大后,用户好像离不开这个软件(竞争者都被干掉了)。软件的发展似乎不再需要用户提什么需求,而是软件想给用户什么功能,用户只能“自己承受”。 需求分析随着软件发展成熟后还有必要吗?现在许多app功能越来越多,偏离了最初的目的,如何看待这种情况?
个人认为需求分析应随着版本更迭进行修改,迎合用户需求将会是软件更加稳定,忽略用户长期看来会对一个成熟的软件产生严重影响
Q4 PM与团队平等相处是幻想还是可以实现?
首先,我们认为好的产品设计是在平等讨论(甚至争论)的基础上产生和完善的,如
果讨论的一方同时又是另一方的老板,则无法进行平等和无拘束的讨论。其次,PM的产品是规格说明书(Spec), PM要凭自己的能力,把用户的需求展现
成其他成员能够理解和执行的语言,从而贏得同伴的信任和尊敬。
在产品设计过程中可能会发生许多分歧,谁也说服不了谁,这样是不是反而影响效率?表格中一个团队可能有多个PM,这些PM发生分歧又该如何解决?如果出现一个PM有了决定权,那么是不是就无法平等讨论?
个人认为PM应该把握重要的部分,有决定权,但是其他部分要和团队进行讨论,增加队员的存在感
Q5 测试人员在什么时候进行测试?
书本上说测试人员进行测试几个模块之间的联系,具体时间如何确定呢?开发人员利用单元测试进行测试基础功能,如果测试人员也要进行测试,开发人员能否不再进行单元测试,把工作都丢给测试人员。如果测试人员等到开发后期进行测试,则可能导致整个程序改动。如何确定测试人员开始测试的时期呢?
个人认为开发人员进行单元测试时只是测试了基础功能,而不同功能之间构成的模块则需要测试人员进行。测试不应该在开发后期进行,而是分阶段在一个模块完成后进行测试
附加题
Linus Benedict Torvald
Linus Benedict Torvald生长在赫尔辛基,是一位瑞典裔芬兰人。
目前,Linus定居美国加利福尼亚州,为一个非Linux公司工作。Linus喜欢喝啤酒,更喜欢一个栩栩如生的小企鹅(Linux的标志),和他聪明伶俐的宝贝女儿。
Linus最大的成就不是他编写了Linux的内核,而是将它公布于众。1991年,作为一位计算机系学生,Linus开发了一种小型的类似UNIX的操作系统,并公布了它的源代码,他还在Internet上寻找程序员共同开发该系统,并最终定名为Linux。
事情的起源是这样的:为了学习使用著名计算机科学家Andrew S.Tanenbaun开发的Minix(一套功能简单、易懂的UNIX操作系统,可以运行在8086上,后来也支持80386,在一些PC机平台上非常流行),Linux购买了一台486微机,但是他发现了Minix的功能还很不完善,于是他决心自己写一个保护模式下的操作系统,这就是Linux的原形。最初的Linux是用汇编语言编写的,主要用来处理80386保护模式。1991年10月5日,Linus发布了Linux的第一个“正式”版本,即0.02版。
part2:WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 120 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 40 | 50 |
| · Coding | · 具体编码 | 100 | 120 |
| · Code Review | · 代码复审 | 30 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 150 | 180 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 600 | 640 |
解题思路描述
- 统计文件的字符数(对应输出第一行):
- 统计文件的单词总数(对应输出第二行),单词:至少以4个
- 统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个
-
首先先看题目需求,分析题目。根据需求大概需要4个方法,分别对应4点需求,这次先初步写好函数,不考虑接收的数据合法化问题
-
把4个函数写完进行封装,新建一个CountCore类封装这4个方法,并且添加私有变量map用来记录单词的个数
-
在WordCore类写相关的输入输出函数
-
新建Data类用来临时存放所需数据,避免频繁计算文件
-
对输入输出进行单元测试
-
性能优化,优化排序算法,单词查找算法
代码规范制定链接
设计与实现过程
简单介绍
CountCore.java用于计算所需数据
public int getWordCount(String key);
public int getCharCount() ;
public int getWordsCount();
public int getValidLines();
public String[] getPopularWord();
WordCount.java调用CountCore.java,负责输入输出,文件输出和命令行输出
public static void print(CountCore cc) ;
public static void write(CountCore cc, String outPath);
具体介绍查看README.md --> 功能简介
关键代码
- 获取单词总个数
需求:
单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
每次读入文件中一行数据,用正则表达式[^a-zA-Z0-9]进行行分割,并采用正则表达式[A-Za-z]{4,}[A-Za-z0-9]进行单词的识别
之后调用map.merge(tp.toLowerCase(), 1, Integer::sum);记录单词数,map key为单词名称,value为个数
举例
spring apple$Year#1234abc
第一次分割后{spring,apple,Year,1234abc}
识别后
public int getWordsCount() {
int cnt = 0;
String pattern = "[A-Za-z]{4,}[A-Za-z0-9]*";
Matcher m = null;
String s = null;
try (BufferedReader reader =
new BufferedReader(new InputStreamReader(new FileInputStream(inPath)))) {
Pattern r = Pattern.compile(pattern);
while ((s = reader.readLine()) != null) {
String[] s1 = s.split("[^a-zA-Z0-9]");
for (String tp : s1) {
m = r.matcher(tp);
if (m.matches()) {
cnt++;
map.merge(tp.toLowerCase(), 1, Integer::sum);
}
}
}
return cnt;
} catch (IOException ie) {
ie.printStackTrace();
}
return 0;
}
- 获取有效行数
每次读入文件中一行数据,调用trim()删除首位空格,判断是否等于""
public int getValidLines() {
String s;
int cnt = 0;
try (BufferedReader reader =
new BufferedReader(new InputStreamReader(new FileInputStream(inPath)))) {
while ((s = reader.readLine()) != null) {
if (!"".equals(s.trim())) {
cnt++;
}
}
return cnt;
} catch (IOException ie) {
ie.printStackTrace();
}
return 0;
}
- 获取字符数
每次读入文件中一个,判断是否小于128(ASCII范围0~127),若小于则计数器+1
public int getCharCount() {
int tp;
int cnt = 0;
try (BufferedReader reader =
new BufferedReader(new InputStreamReader(new FileInputStream(inPath)))) {
while ((tp = reader.read()) != -1) {
if (tp < 128) {
cnt++;
}
}
return cnt;
} catch (IOException ie) {
ie.printStackTrace();
}
return 0;
}
- 排序选择单词频度最高的10个
重复值多,采用三向切分快速排序
void quick_sort(String[] list, int l, int r) {
if(l>=r) return;
int i = l, j = r;
int k = i+1;
int x=map.get(list[l]);
if(k<j){
while (k<=j) {
if (map.get(list[k]) < x){
String tp = list[j];
list[j] = list[k];
list[k] = tp;
j--;
}
else if (map.get(list[k]) > x){
String tp = list[i];
list[i] = list[k];
list[k] = tp;
k++;
i++;
}else{
k++;
}
}
if(r-l>20){
quick_sort(list, l, i - 1);
}else{
quick_sort(list, l, i - 1);
quick_sort(list, j + 1, r);
}
}
}
性能改进
排序
当测试用例很多的时候冒泡/插入比较慢,10000000个字符时(200000多个单词)冒泡需要9分多
使用快速排序后,出现栈溢出,性能不好
发现单词中重复的比较少,即大多数单词都出现了1-3次,于是先采用三向切分快速排序,然后在按次数分块,每块再采用快速排序,花费时间0.15s
例如
apple 2
banana 2
pear 1
asdf 1
zxcv 1
zxvbn 1
先用三向切分排序次数,分成两块{apple,banana},{pear,asdf,zxcv,zxvbn}
块内再按字典序列使用快速排序
public String[] getPopularWord() {
String[] list = map.keySet().toArray(new String[0]);
if(list.length==0){
return list;
}
//第一次排序
quickSort(list, 0, list.length - 1);
int cnt=0;
int x=0;
int integer = map.get(list[0]);
for(int i=0;i<list.length;i++){
if(map.get(list[i])!=integer) {
quickSort_1(list, x, i - 1);
cnt += i-x;
x=i;
integer = map.get(list[i]);
}
if(cnt>10)
break;
}
//第二次排序
quickSort_1(list,x,list.length-1);
return list;
}
单词查找
一开始使用正则表达式,100000000个字符需要6.9s
while ((s = reader.readLine()) != null) {
s1 = s.split("[^a-zA-Z0-9]");
for (String tp : s1) {
m = r.matcher(tp);
if (m.matches()) {
cnt++;
map.merge(tp.toLowerCase(), 1, Integer::sum);
}
}
}
然后发现分割开的字符串很短,不需要每个都去匹配,加上s.length()和tp.length()>=4判断,此时需要5.8s
while ((s = reader.readLine()) != null) {
s = s.trim();
if(s.length()<4){
continue;
}
s1 = s.split("[^a-zA-Z0-9]");
for (String tp : s1) {
m = r.matcher(tp);
if (tp.length()>=4&&m.matches()) {
cnt++;
map.merge(tp.toLowerCase(), 1, Integer::sum);
}
}
}
单元测试
代码
WordCountTest
有print,write,main方法
三种方法测试分支一样
- 正确
- 传入null
- 传入无效的文件
- 传入不存在的文件
- 传入空文件
- 传入空的CountCore对象
@Test
public void print() {
//正确情况
WordCount.print(new CountCore("src/main/java/com/company/test.txt"));
//传入null
WordCount.print(new CountCore(null));
//传入无效的文件
WordCount.print(new CountCore("sdas.xx"));
//传入不存在的文件
WordCount.print(new CountCore("tesst.txt"));
//传入空文件
WordCount.print(new CountCore("src/main/java/com/company/empty.txt"));
//传入空的CountCore对象
WordCount.print(null);
}
CountCore
使用随机字符填充文件,然后进行测试
//初始化文件
countCore = new CountCore("src/main/java/com/company/test.txt");
random = new Random();
count = 10000000;
b = new char[count];
for (int k = 0; k < count; k++) {
b[k] = chars[random.nextInt(CNT)];
}
try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("src/main/java/com/company/test.txt")))) {
String s = new String(b);
writer.write(s);
} catch (IOException ie) {
ie.printStackTrace();
}
getCharCount()
根据初始化时已知的添加的字符数和具体的方法进行比较Assert.assertEquals(count, countCore.getCharCount());
getValidLines()
根据文件有效行数和具体方法比较Assert.assertEquals(c,countCore.getValidLines());
//计算有效行数c
for(int i = 0;i<100;i++){
int c = 0;
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("src/main/java/com/company/test.txt")))) {
String str;
while((str = reader.readLine())!=null){
if(!"".equals(str.trim())){
c++;
}
}
} catch (IOException ie) {
ie.printStackTrace();
}
//进行比较
Assert.assertEquals(c,countCore.getValidLines());
}
其他测试则是直接调用countCore.method(),与文件实际进行比较
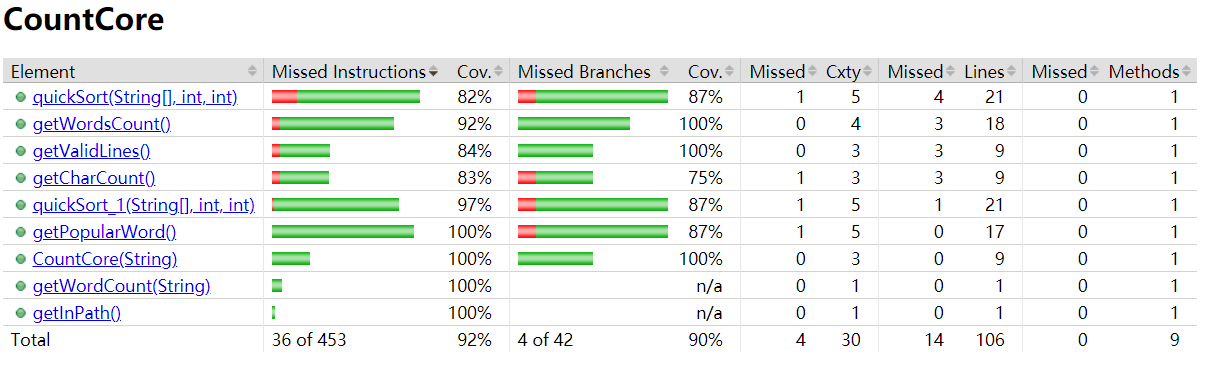
覆盖率截图
CountCore
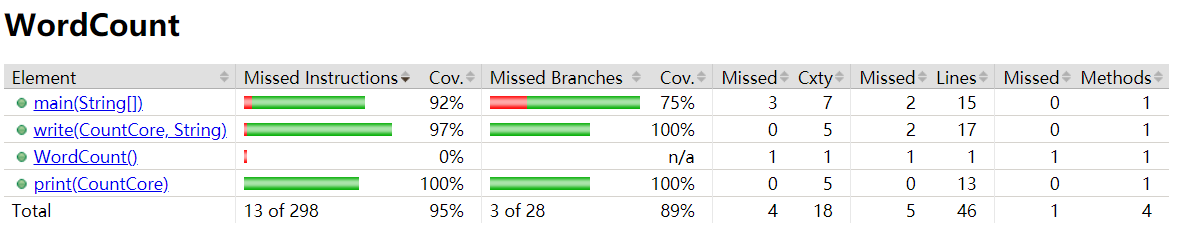
WordCount
如何提高覆盖率
- 测试方法的参数尽可能多,选择合适的参数使方法的每个分支都可以运行到
- 使用随机参数重复多次,可以提高覆盖率
异常处理说明
CountCore接收一个String参数作为文件名,可能发生的异常文件名无效,文件不存在
涉及到文件读取的方法:getValidLines();getWordsCount();getCharCount();
//计数器
int cnt = 0;
try (BufferedReader reader =
new BufferedReader(new InputStreamReader(new FileInputStream(inPath)))) {
//正确逻辑...
return cnt;
} catch (Exception ie) {
//异常逻辑
//IOException;NullPointerException
System.out.println("file is't exist");
}
return 0;
获取前10个频度最高的单词时,由于文件可能为空,在方法一开始就检测单词序列是否为空
public String[] getPopularWord() {
String[] list = map.keySet().toArray(new String[0]);
if(list.length==0){
return list;
}
//剩余代码
}
单元测试样例
//正确情况
WordCount.print(new CountCore("src/main/java/com/company/test.txt"));
//传入null
WordCount.print(new CountCore(null));
//传入无效的文件
WordCount.print(new CountCore("sdas.xx"));
//传入不存在的文件
WordCount.print(new CountCore("tesst.txt"));
//传入空文件
WordCount.print(new CountCore("src/main/java/com/company/empty.txt"));
//传入空的CountCore对象
WordCount.print(null);
心路历程与收获
- 这次作业,我学习了github的简单使用,单元测试的简单使用。以前一直忽略单元测试,这次感受到单元测试的强大,不再像之前对着几百行的代码纠错,经常“迷失”,而是一个一个函数测试,清楚明白。
- 这次作业回顾了以前学过的排序算法,通过对比很明显看出快速排序的效率
- 这次作业,从需求分析再到具体编码,明白了需求分析的重要性,通过设计文档,使思路更清晰
- 这次项目虽然小,但是完整,让我清楚体会到对于一个项目,具体要先做什么,再做什么,以及怎么做
- 估算PSP的时间,差距最大的则是测试部分,测试不是简简单单运行一遍的事情,而是要仔细考虑每一个可能的分支,使得代码更加健壮
