

Hive笔记6(2) ### 排序 重点
6.5 排序
6.5.1全局排序(Order by)
Order By 全局排序,一个Reducer
1,使用Oerder by 子句排序
ASC(ascend) : 升序(默认)
DESC(descend):降序
2,ORDER BY 子句在SELECT语句的结尾
3,案例实操:
(1)查询员工信息按工资升序排序
select * from emp order by sal;
(2)查询员工信息按工资降序排序
select * from emp order by sal desc
6.5.2 按照别名排序
按照员工薪水的2倍排序
select ename, sal * 2 twosal from emp order by twosal;
6.5.3 多个列排序
按照部门和工资升序排序
select ename, deptno, sal from emp order by deptno, sal;
6.5.4 每个MapReduce内部排序(Sort By)
Sort By:每个Reduce内部进行排序,对全局结果集来说不是排序
1.设置:reduce个数
set mapreduce.job.reduces = 3;
2.查看设置reduce个数
set mapreduce.job.reduces;
3.根据部门编号降序查询员工信息
select * from emp sort by empno desc;
4.将查询结果导入到文件中(按照部门编号降序排序)
insert overwrite local directory '/opt/module/datas/sortby-result'
select * from emp sort by deptno desc;
6.6.5 分区排序(Distribute By)
Distribute By:类似MR中partition,进行分区,结合sort by使用。
注意,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
对于distribute by 进行测试,一定要分配多reduce进行处理,否则无法看到distribute by 的效果。
案例实操:
(1)先按照部门编号分区,再按照员工编号降序排序。

6.5.6 Cluster By
当distribute by和sorts by 字段相同时,可以使用cluster by 方式
cluster by 除了具有distribute by 的功能外还兼职sorted by 的功能。
但是排序只能是升序排序,不能指定排序规则为ASC或DESC。
1)以下两种写法等价
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;
注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。
6.6 分桶及抽样查询
6.6.1分桶表数据存储
分区针对的是数据的存储路径;分桶针对的是数据文件。
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区,特别是之前所提到过的要确定合适的划分大小这个疑虑。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。

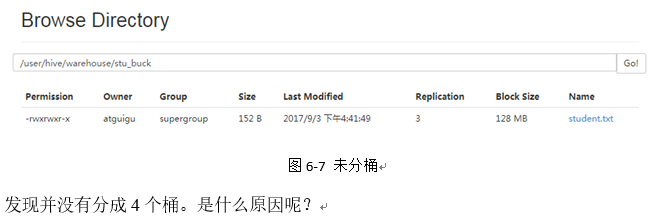
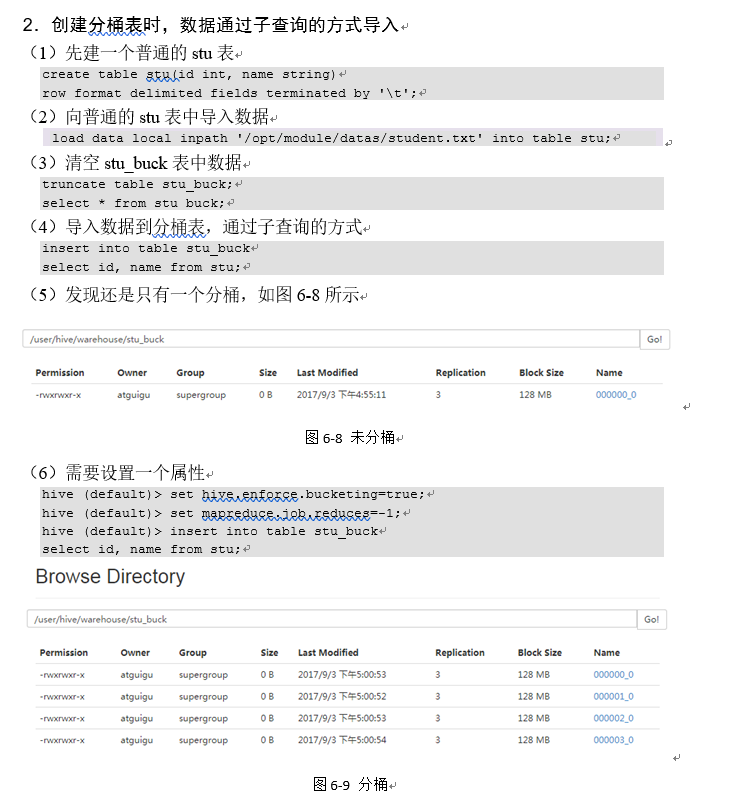

6.6.2 分桶抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果,
Hive可以通过对表进行抽样来满足这个需求。

6.7 其他常用查询函数
6.7.1空字段赋值
1,函数说明:
NVL:给值为NULL的数据赋值,它的格式是NVL(string1, replace——with)。
它的功能是如果string1为NULL,则NVL函数返回replace_with的值,否则返回string1的值,如果两个参数为NULL,则返回NULL

6.7.2 CASE WHEN
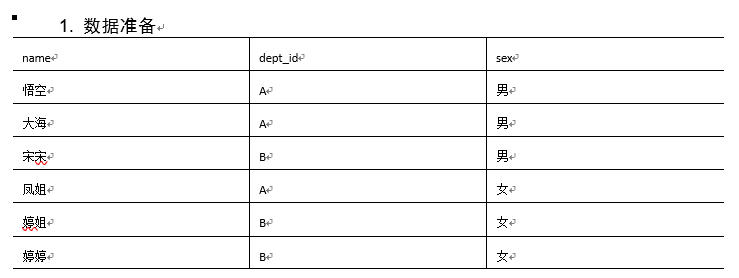

5.按需求查询数据
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from
emp_sex
group by
dept_id;
6.7.2行转列
1.相关函数说明
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
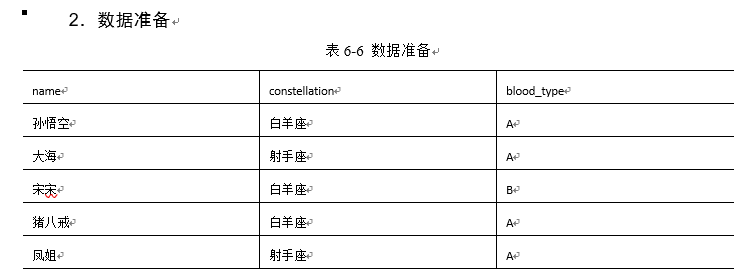

6.按需求查询数据
select
t1.base,
concat_ws('|', collect_set(t1.name)) name
from
(select
name,
concat(constellation, ",", blood_type) base
from
person_info) t1
group by
t1.base;
6.7.3 列转行
1.函数说明:
EXPLODE(COL) 将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW
用法: LATERAL VIEW udtf(expression) tableAlias as columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。

6,按需求查询数据
select movie, categroy_name
from movie_info lateral view explode(categroy) table_tmp as categroy_name;
6.7.4 窗口函数
1,相关函数说明:
OVER() :指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
LAG(col,n):往前第n行数据
LEAD(col,n):往后第n行数据
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。

5,创建hive表并导入数据
create table business(
name string,
orderdate string,
cost int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath "/opt/module/datas/business.txt" into table business;
6, 按需求查询数据
(1)查询在2017年4月份购买过的顾客及总人数
select name,count(*) over()
from business
where substring(orderdate, 1, 7) = '2017-04'
group by name;
(2)查询顾客的购买明细及月购买总额
sleect name, orderdate,cost, sum(cost) over(partition by month(orderdate)) from business;
(3)上述的场景,要将cost按照日期进行累加
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from business;
(4)查看顾客上次的购买时间
select name,orderdate,cost,
lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1, lag(orderdate,2) over (partition by name order by orderdate) as time2
from business;
(5)查询前20%时间的订单信息
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;
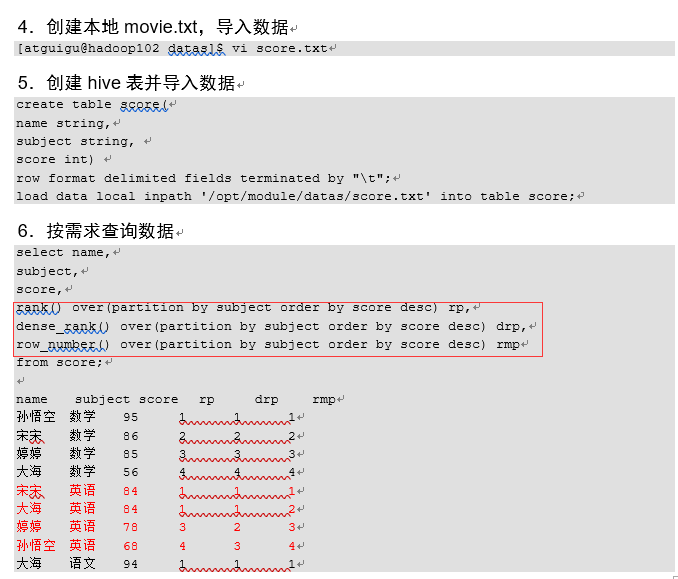
6.7.5 Rank
1.函数说明
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix