Hive笔记4
DDL数据定义
创建数据库
1)创建一个数据库,数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db。

2)避免要创建的数据库已经存在错误,增加if not exists判断。(标准写法)
create database if not exists db_hive;

3)创建一个数据库,指定数据库在HDFS上存放的位置
create database db_hive2 location '/db_hive2.db';
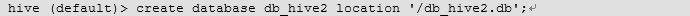
4.2查询数据库
4.2.1 显示数据库
- 1.显示数据库
show databases
-2. 显示数据库详细信息,extended
create database extended db_hive;
4.3.3 切换当前数据库use
use db_hive;
修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES 设置键-值对属性值,来描述这个数据库的属性信息。数据库的其他数据信息都是不可更改的,包括数据库名和数据库所在的目录位置
alter database db_hive set dbproperties('createtime' = '20170830');
在Hive中查询修改结果
desc database extended db_hive;
删除数据库
1.删除数据库
drop database db_hive2;
2.如果删除的数据库不存在,最好采用if exists 判断数据库是否存在
drop database if exists db_hive2;
3.如果数据库不为空,可以采用cascade命令,强制删除
drop database db_hive cascade;
4.5 创建表
1.建表语句
create [EXTERNAL] TABLE [IF NOT EXISTS] TABLE_NAME
[(COL_NAME DATA_TYPE [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ....)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
2.字段解释说明
-
(1) CREATE TABLE 创建一个指定名字的表, 如果相同名字的表已经存在,则抛出异常;
用户可以用IF NOT EXISTS 选项来忽略这个异常。 -
(2)EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
-
(3)COMMENT: 为表和列添加注释
-
(4) PARTITIONED BY :创建分区表
-
(5) CLUSTERED BY : 创建分桶表
-
(6) SORTED BY :排序
-
(7) ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。
-(8)STORED AS指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
- (9) LOCATION : 指定表在HDFS上的存储位置
- (10) LIKE允许用户复制现有的表结构,但是不复制数据
4.5.1 管理表
1,理论
默认创建的表都是所谓的管理表,有时也称为内部表。这种表,Hive会(或多或少的)控制数据的生命周期。Hive默认情况下会将这些表的数据存储在配置项所定义的目录的子目录中。当我们删除一个管理表时,Hive也会删除这个表中的数据。管理表不适合和其他工具共享数据。
2.案例实操
(1)普通创建表
create table if not exists student2(
id int, name string
)
row format delimited fields terminated by '\t'
sorted as textfile
location '/user/hive/warehouse/student2';
外部表
1.理论
因为表是外部表,所以Hive并非认为其完全拥有这份数据
删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
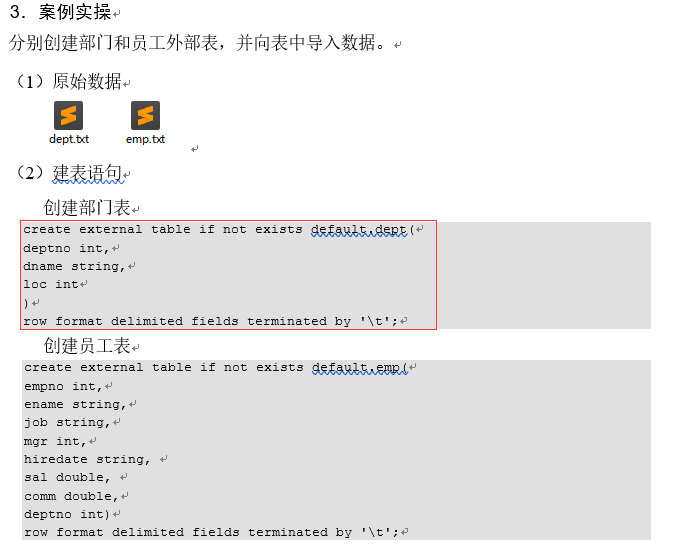
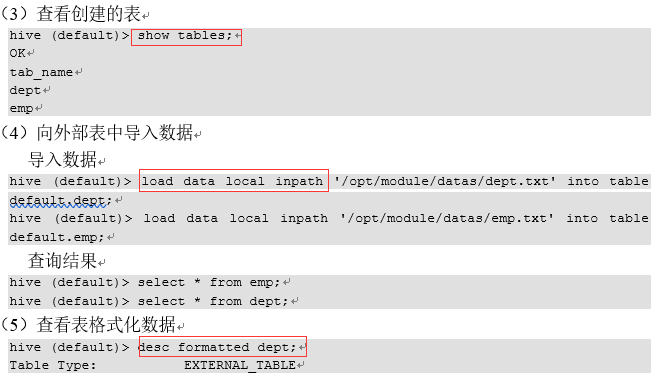
2.管理表和外部表的使用场景
每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。

4.6分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需求分割小的数据集。在查询的时候通过where子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
4.6.1 分区表的基本操作
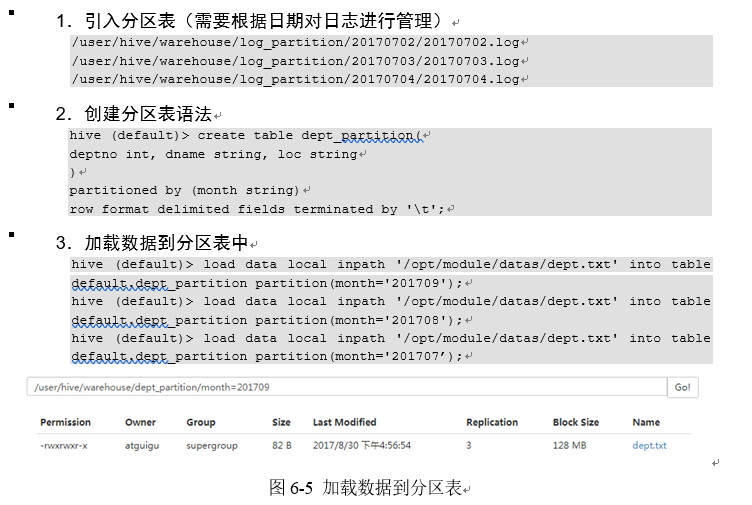
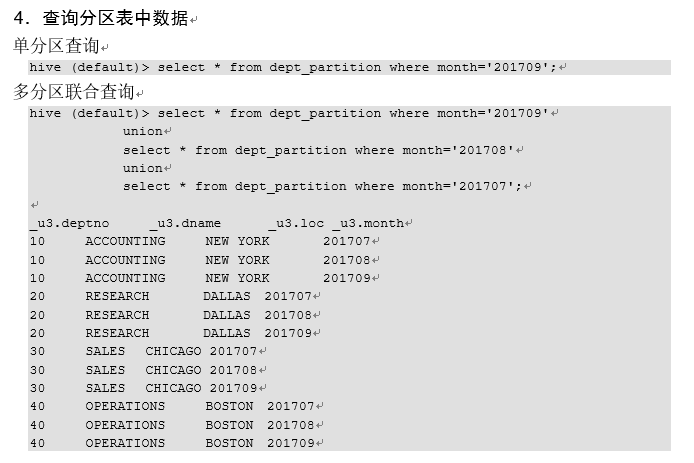
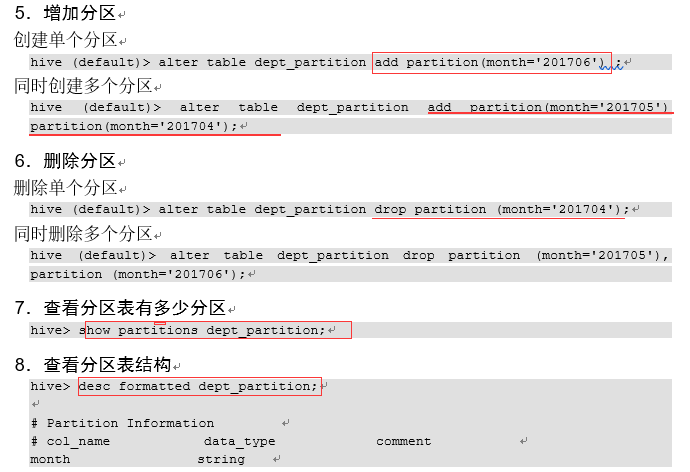
4.6.2 分区表注意事项
1.创建二级分区表
create table dept_partition2(deptno int, dname string , loc string )
partitioned by (month string , day string)
row format delimited filelds terminated by '\t';
2.正常的加载数据
(1)加载数据到二级分区表中
load data local inpath '/opt/module/datas/dept.txt' into table
default.dept_partition2 partition(month='201909',day= '13');
(2)查询分区数据
select * from dept_partition2 where month='201709' abd day = 13';
3.把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式:

4.7 修改表
4.7.1 重命名表
1语法: alter table table_name rename to new_table_name
2.实操案例:
alter table dept_partition2 rename to dept_partition3;
4.7.2 增加、修改和删除表分区

4.8 删除表
drop table dept_partition;
