
计算机原理之Linux操作系统(持续完善ING)
用java做一个最小的操作系统内核
以下文章转载自:https://www.jianshu.com/p/61c351b8d9da
用java来做操作系统内核,太搞笑了吧。如果你这么想,同时嘴上发出呵呵一笑。那么我这篇文章的目的也算达到了,评判一篇文章好坏,不就在于它是否能让读者感觉到精神的愉悦吗。如果你笑了,那表明我写了一篇好文章。呵呵!
操作系统,是计算机科学中的皇冠,它作为一个平台,几乎集结了计算机科学里面的所有知识,如硬件,算法,架构,能够写出一个操作系统的人,无一不是行业里的翘楚或大神级人物,像Linux的创始人Torvalds,Android的创始人安迪·鲁宾,苹果早期电脑系统的开发者史蒂夫-沃兹尼亚克,哪一个不是牛逼的闪闪发光,让人膜拜。
我也想牛逼,我也想闪闪发光,所以我也要做一个操作系统,嘿嘿,你笑了吧,笑了的话,就表明我写了一篇好文章_!
说到这,我的能量槽已经蓄满,立马要放大招了,小心我的必杀技
import java.io.DataOutputStream;import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException
;import java.io.InputStream;
import java.util.ArrayList;
public class OperatingSystem {
private int[] imgContent = new int[]{
0xeb,0x4e,0x90,0x48,0x45,0x4c,0x4c,
0x4f,0x49,0x50,0x4c,0x00,0x02,0x01,
0x01,0x00,0x02,0xe0,0x00,0x40,0x0b,
0xf0,0x09,0x00,0x12,0x00,0x02,0x00,
0x00,0x00,0x00,0x00,0x40,0x0b,0x00
,0x00,0x00,0x00,0x29, 0xff,0xff,0xff,0xff,
0x48,0x45,0x4c,0x4c,0x4f,0x2d,0x4f,0x53,
0x20,0x20,0x20,0x46,0x41,0x54,
0x31,0x32, 0x20,0x20,0x20,0x00,0x00,0x00
,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xb8,
0x00,0x00,0x8e,0xd0,0xbc,0x00,0x7c,0x8e,
0xd8,0x8e,0xc0,0xbe,0x74,0x7c,0x8a,0x04,0x83,
0xc6,0x01,0x3c,0x00,0x74,0x09,0xb4,0x0e,0xbb,
0x0f,0x00,0xcd,0x10,0xeb,0xee,0xf4,0xeb,0xfd };
private ArrayList<Integer> imgByteToWrite = new ArrayList<Integer>();
public OperatingSystem(String s)
{
for (int i = 0; i < imgContent.length; i++) {
imgByteToWrite.add(imgContent[i]); }
imgByteToWrite.add(0x0a);
imgByteToWrite.add(0x0a);
for (int j = 0; j < s.length(); j++) {
imgByteToWrite.add((int)s.charAt(j)); }
imgByteToWrite.add(0x0a);
int len = 0x1fe;
int curSize = imgByteToWrite.size();
for (int k = 0; k < len - curSize; k++) {
imgByteToWrite.add(0); } //0x1fe-0x1f: 0x55, 0xaa //0x200-0x203: f0 ff ff
imgByteToWrite.add(0x55);
imgByteToWrite.add(0xaa);
imgByteToWrite.add(0xf0);
imgByteToWrite.add(0xff);
imgByteToWrite.add(0xff);
len = 0x168000;
curSize = imgByteToWrite.size();
for (int l = 0; l < len - curSize; l++) {
imgByteToWrite.add(0); }
}
public void makeFllopy() {
try { DataOutputStream out = new DataOutputStream(new FileOutputStream("system.img"));
for (int i = 0; i < imgByteToWrite.size(); i++) {
out.writeByte(imgByteToWrite.get(i).byteValue()); }
}
catch (Exception e) { // TODO Auto-generated catch block
e.printStackTrace(); }
}
public static void main(String[] args) {
OperatingSystem op = new OperatingSystem("hello, this is my first line of my operating system code"); op.makeFllopy();
}
}
上面的代码执行后,在工程目录下会生成一个system.img文件。接着利用virtualbox创建一个虚拟机,设置它为磁盘启动,并在配置中,将代码生成的system.img当做虚拟磁盘插入虚拟机
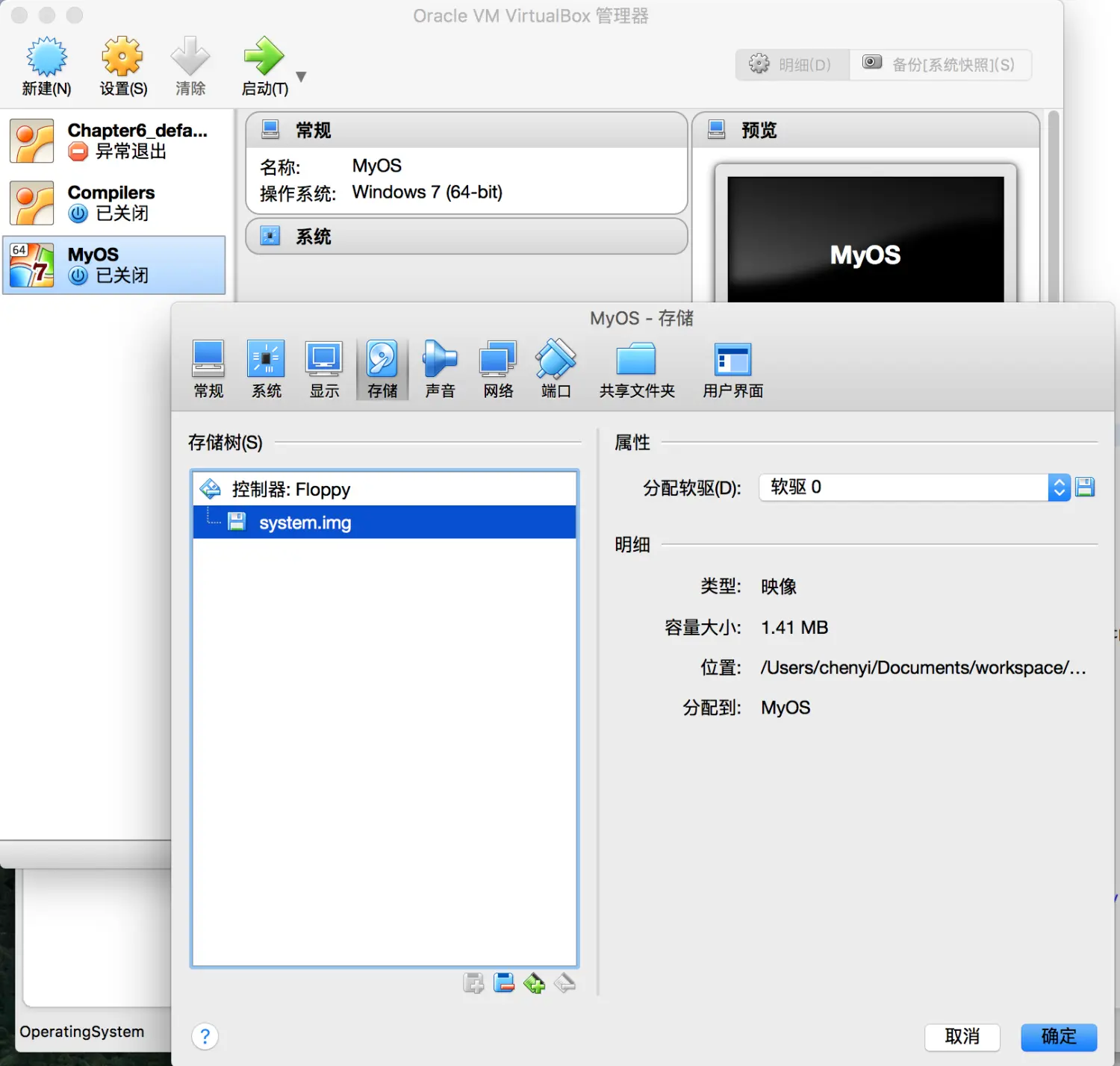
然后点击启动,结果如下
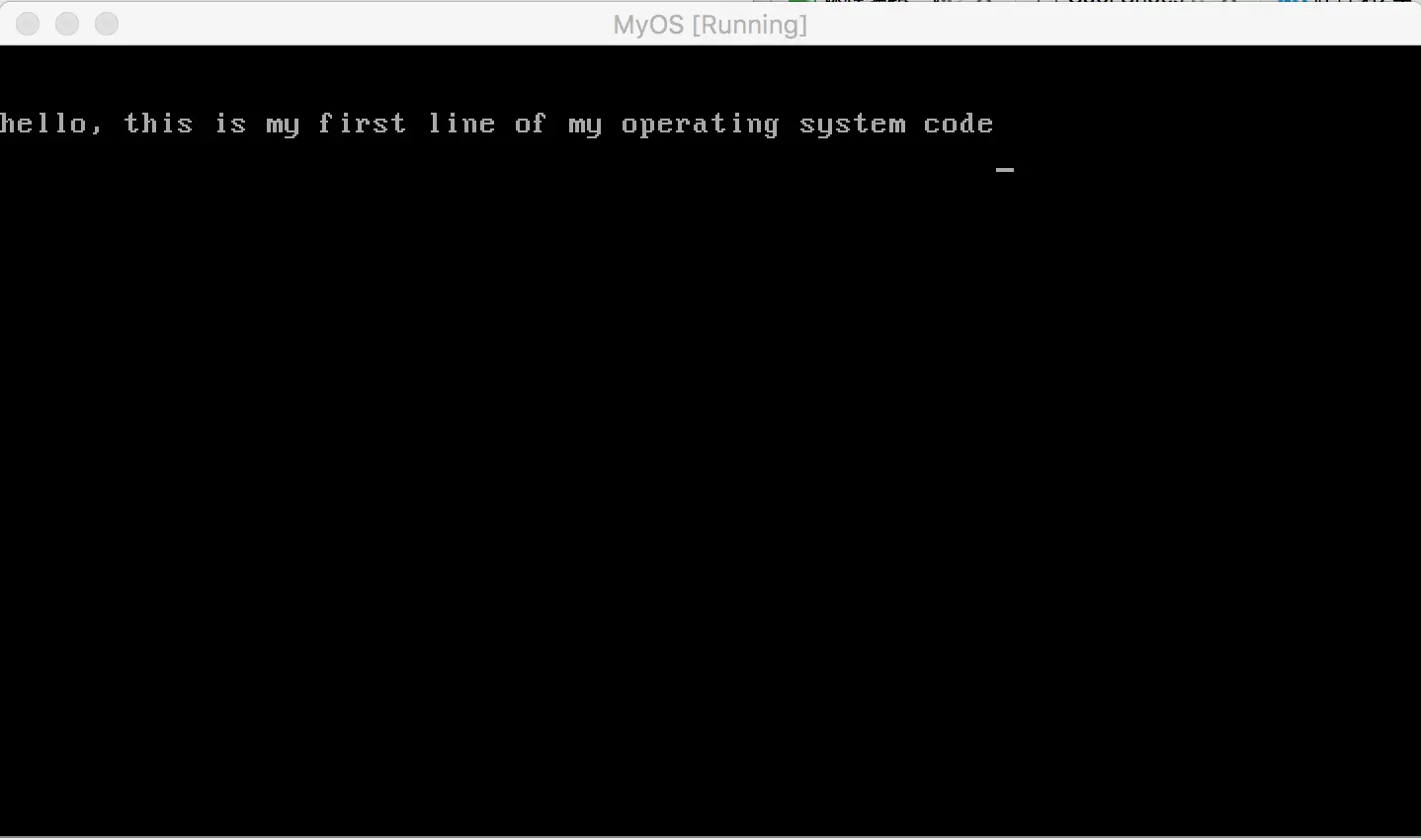
Java代码中,main函数里的字符串出现在了虚拟机屏幕里,然后虚拟机就卡死了。机器上电后就加载了我们的代码,这不就是一个操作系统的雏形吗?
从硬件角度理解进程与线程
以下文章转载自:https://www.jianshu.com/p/f79b877c9611
进程与线程是现代计算机系统的重要概念,下面摘录两者的定义:
进程:是执行中一段程序,即一旦程序被载入到内存中并准备执行,它就是一个进程。进程是表示资源分配的的基本概念,又是调度运行的基本单位,是系统中的并发执行的单位。
线程:单个进程中执行中每个任务就是一个线程。线程是进程中执行运算的最小单位。
对于两个的定义相比大家已经耳熟能详,然而能讲出两个两者的定义,就真的已经深入理解了进程(线程)是如何工作的吗?本文从硬件、操作系统两个角度来深入理解一下进程(线程),进程(线程)究竟是什么东西?他们究竟是怎么被操作系统调度的,需要哪些软硬件的协同工作?
CPU顺序运行
为了能够理解线程,我们先来看看程序是如何在CPU上执行的。CPU内部主要包含三个部分:
- 控制单元(Control Unit),主要给指令译码,并发出执行指令的操作。比如指令是一条加法,那么控制器发送指令给ALU完成加法操作,如果是一条load指令,那么会发送信号给DMP(data memory pipeline)模块将memory中的数据load到CPU中寄存器。
- 算数逻辑单元(ALU),负责计算类指令执行,比如两个数相加、相减等。
- 寄存器组,比如PC寄存器,PC寄存器存储当前CPU执行指令的地址,CPU处理完当前指令后PC值指向下一条指令,地址加4。其他寄存器也有一些特别的作用,不再赘述。
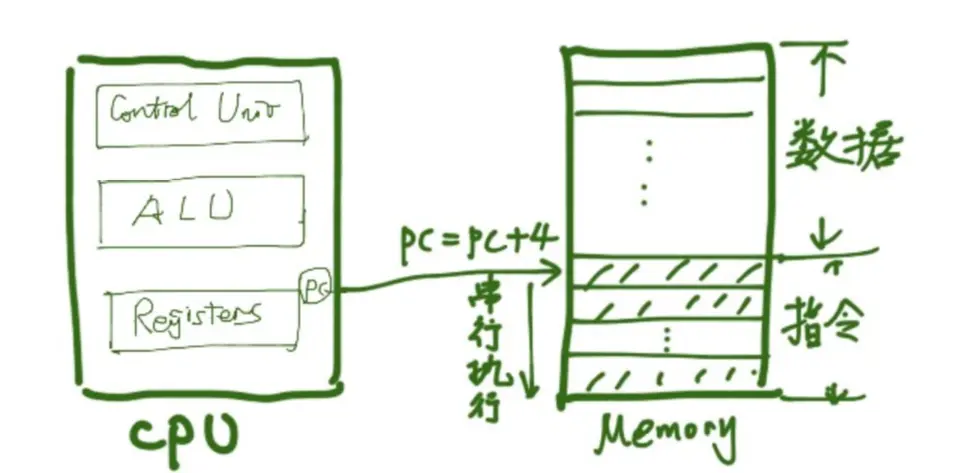
按照冯诺依曼架构系统设计,程序应该按照一定的顺序串行执行。CPU就是通过PC指针不断累加,实现程序的串行执行。正常情况下PC指针的值每个cycle会自动加4,由于每个指令占4个字节,那么CPU在执行完当前指令后,就会自动执行下一个指令。
打破CPU顺序运行
正常情况下从给系统加电, PC就不断累加,CPU按照串行顺序一致执行下去。有两个情况PC的值会发生“突变”:
- 程序主动跳转,比如汇编goto指令,c语言的longjmp函数等。本质上就是主动去修改PC的值,直接跳转到需要执行的指令,而不是位置临近的“下一条指令”。
- 系统发生中断,比如CPU的某一条引脚的电瓶为高表示发生了“突变”,系统比如对这个中断做出反应。中断发出者除了发送高电平到CPU相关引脚,还需要提供一个中断向量号,通知CPU发生了什么类型的中断。CPU根据中断向量号,找到相应的中断处理程序并处理中断。
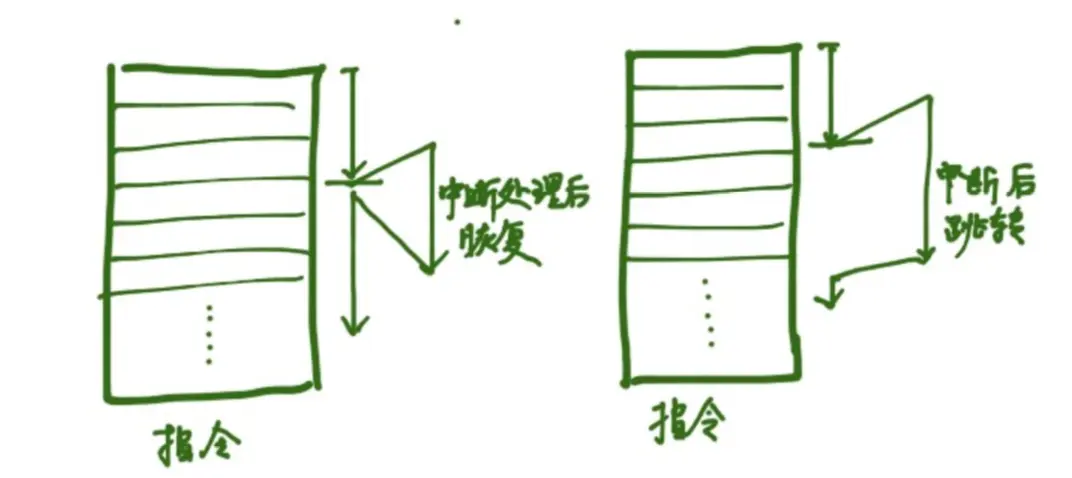
CPU多线程执行
既然CPU默认是按照程序串行执行,那么怎么去实现多线程并发执行呢?核心思想是:只要保存下当前程序执行现场,包括PC值、各寄存器值,那么不管CPU现在执行其他什么程序,都能恢复到上次程序执行的现场,并按照之前的执行顺序继续执行,就当什么事情也没有发送过一样。
需要做到单核CPU并发,需要涉及到几点:
- 线程执行状态的保存,简单理解就是CPU中各寄存器值的保存,比如保存PC值我们可以知道这个线程执行到哪个指令了
- 多线程之间的切换,保存下当前线程的状态,恢复之前暂停的线程的状态并继续执行
- 需要有一个调度者决定恢复执行哪个线程,可以根据线程的优先级,也可以随机选择,不同操作系统实现算法不一
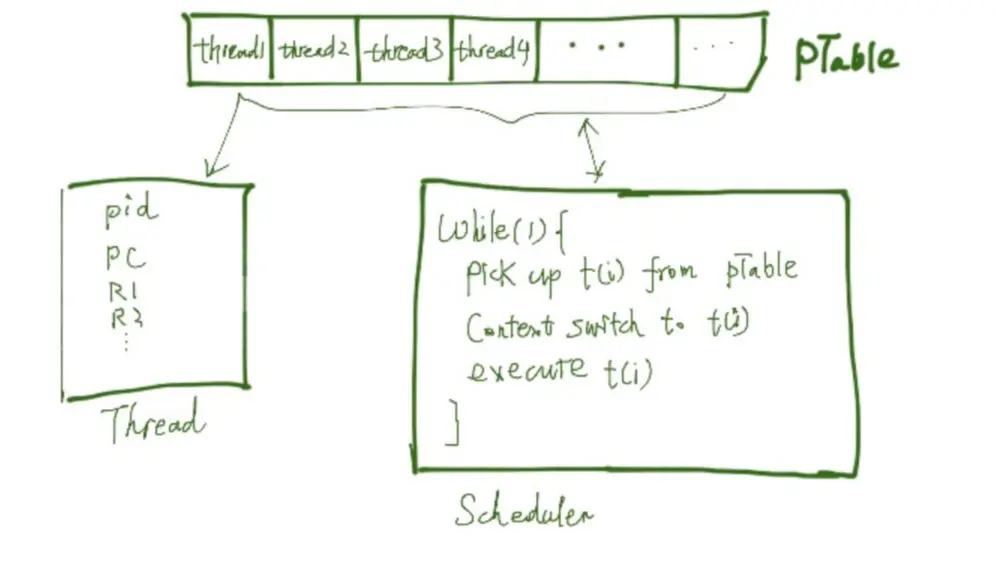
我们可以定义个数组pTable,把每个线程的执行状态存在里面,就有办法从保存的信息中恢复上次执行的状态,并继续串行执行。说白了,线程也是一个对象结构,里面包含的就是这个线程的唯一标示、当前线程的执行状态等内容。线程间的切换,就是线程上下文的保存与恢复。保存下当前线程的状态,恢复之前暂停的线程的状态并继续执行。调度程序负责恢复执行哪个线程,并一直循环下去。
那么问题来了,加入当前CPU已经在执行某一个线程,如何能够定期切换到调度程序scheduler呢?这时候就需要硬件的支持了,通过硬件的定时器与中断功能,需要实现一个定时中断程序。比如每隔1ms触发一个硬件中断,强迫CPU回到调度程序中去。中断的本质,就是打破PC寄存器累加的节奏,直接让CPU去处理中断相应程序,而不是一直按照既定顺序一致串行执行下去。
我们可以在中断处理程序中,让当前线程主动让出(yeild)CPU控制权,让CPU恢复执行scheduler调度程序。当然当前线程让出CPU控制权,也是一个上下文切换,需要保存当前线程执行状态,并回复scheduler线程状态。从这个角度上讲,操作系统的调度程序其实就是一个普通的线程罢了。当然实现调度程序定时切换的方式有很多中,这里为了便于理解,采用了一种比较简单的方案。
用户态与内核态之间切换详解
以下文章转载自:https://cloud.tencent.com/developer/article/2131401
用户空间和内核空间
用户程序有用户态和内核态两种状态。用户态就是执行在用户空间中,不能直接执行系统调用。必须先切换到内核态,也就是系统调用的相关数据信息必须存储在内核空间中,然后执行系统调用。
操作硬盘等资源属于敏感操作,为了内核安全,用户线程不能直接调用。而是采用了操作系统内核提供了系统调用接口,用户线程通过系统调用来实现文件读写。所以直接与硬盘打交道的是操作系统内核。
操作系统将线程分为了内核态和用户态,当用户线程调用了系统调用的时候,需要将线程从用户态切换到内核态。
无论是操作系统内核程序还是用户程序在运行的时候都需要申请内存来保存运行状态,调用方法信息、程序代码、数据等信息。
操作系统将内存分为内核空间和用户空间。
内核空间中主要负责 操作系统内核线程以及用户程序系统调用。
用户空间主要负责用户程序的非系统调用。
内核空间比用户空间拥有更高的操作级别,只有在内核空间中才可以调用操作硬件等核心资源。
操作系统将内存按1:3的比例分为了内核空间和用户空间,用户态的运行栈信息保存在用户空间中,内核态的运行栈信息保存在内核空间中。运行栈中保存了当前线程的运行信息,比如执行到了哪些方法,局部变量等。
当发生用户态和内核态之间的切换的时候,运行栈的信息发生了变化,对应的CPU中的寄存器信息也要发生变换。但是用户线程完成系统调用的时候,还是要切换回用户态,继续执行代码的。所以要将发生系统调用之前的用户栈的信息保存起来,也就是将寄存器中的数据保存到线程所属的某块内存区域。这就涉及到了数据的拷贝,同时用户态切换到内核态还需要安全验证等操作。所以用户态和内核态之间的切换是十分耗费资源的。
用户态切换到内核态
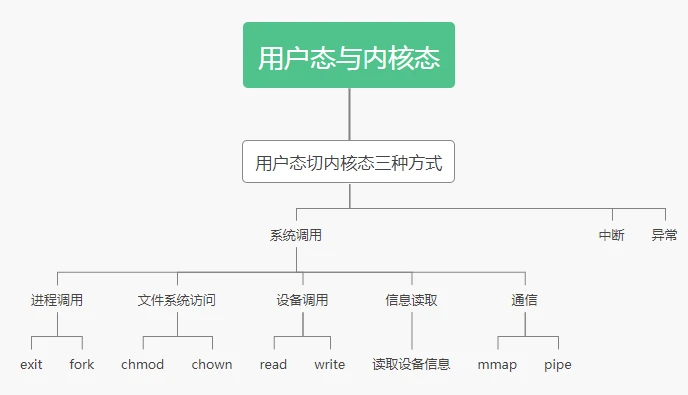
CPU中有一个标志字段,标志着线程的运行状态。用户态和内核态对应着不同的值,用户态为3,内核态为0.
每个线程都对应着一个用户栈和内核栈,分别用来执行用户方法和内核方法。 用户方法就是普通的操作。 内核方法就是访问磁盘、内存分配、网卡、声卡等敏感操作。
当用户尝试调用内核方法的时候,就会发生用户态切换到内核态的转变。
切换流程: 1、每个线程都对应这一个TCB,TCB中有一个TSS字段,存储着线程对应的内核栈的地址,也就是内核栈的栈顶指针。

2、因为从用户态切换到内核态时,首先用户态可以直接读写寄存器,用户态操作CPU,将寄存器的状态保存到对应的内存中,然后调用对应的系统函数,传入对应的用户栈的PC地址和寄存器信息,方便后续内核方法调用完毕后,恢复用户方法执行的现场。
3、将CPU的字段改为内核态,将内核段对应的代码地址写入到PC寄存器中,然后开始执行内核方法,相应的方法栈帧时保存在内核栈中。
4、当内核方法执行完毕后,会将CPU的字段改为用户态,然后利用之前写入的信息来恢复用户栈的执行。
从上述流程可以看出用户态切换到内核态的时候,会牵扯到用户态现场信息的保存以及恢复,还要进行一系列的安全检查,比较耗费资源。
Linux文件描述符的底层原理
以下文章转载自:https://blog.csdn.net/weixin_33465519/article/details/124740646
进程是什么
首先,抽象地来说,我们的计算机就是这个东西
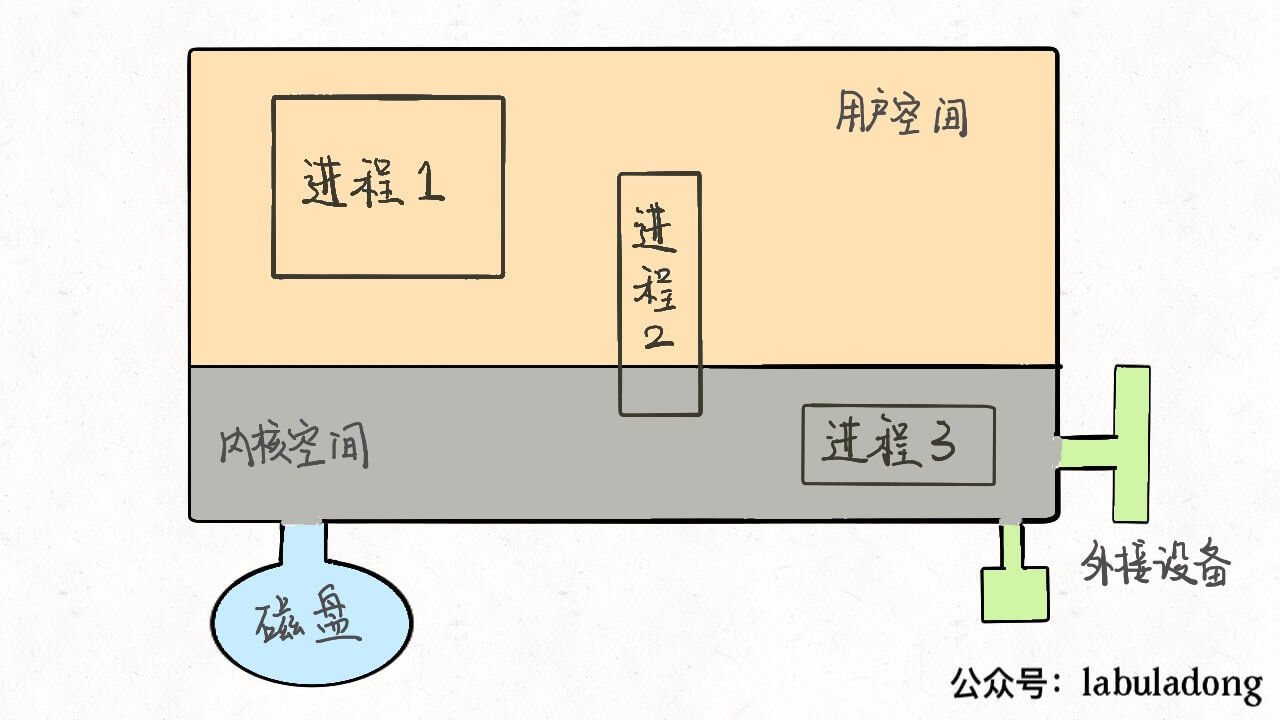
这个大的矩形表示计算机的内存空间,其中的小矩形代表进程,左下角的圆形表示磁盘,右下角的图形表示一些输入输出设备,比如鼠标键盘显示器等等。另外,注意到内存空间被划分为了两块,上半部分表示用户空间,下半部分表示内核空间。
用户空间装着用户进程需要使用的资源,比如你在程序代码里开一个数组,这个数组肯定存在用户空间;内核空间存放内核进程需要加载的系统资源,这一些资源一般是不允许用户访问的。但是注意有的用户进程会共享一些内核空间的资源,比如一些动态链接库等等。
我们用 C 语言写一个 hello 程序,编译后得到一个可执行文件,在命令行运行就可以打印出一句 hello world,然后程序退出。在操作系统层面,就是新建了一个进程,这个进程将我们编译出来的可执行文件读入内存空间,然后执行,最后退出。
你编译好的那个可执行程序只是一个文件,不是进程,可执行文件必须要载入内存,包装成一个进程才能真正跑起来。进程是要依靠操作系统创建的,每个进程都有它的固有属性,比如进程号(PID)、进程状态、打开的文件等等,进程创建好之后,读入你的程序,你的程序才被系统执行。
那么,操作系统是如何创建进程的呢?对于操作系统,进程就是一个数据结构,我们直接来看 Linux 的源码:
struct task_struct {
// 进程状态
long state;
// 虚拟内存结构体
struct mm_struct *mm;
// 进程号
pid_t pid;
// 指向父进程的指针
struct task_struct __rcu *parent;
// 子进程列表
struct list_head children;
// 存放文件系统信息的指针
struct fs_struct *fs;
// 一个数组,包含该进程打开的文件指针
struct files_struct *files;
};
task_struct就是 Linux 内核对于一个进程的描述,也可以称为「进程描述符」。源码比较复杂,我这里就截取了一小部分比较常见的。
其中比较有意思的是mm指针和files指针。mm指向的是进程的虚拟内存,也就是载入资源和可执行文件的地方;files指针指向一个数组,这个数组里装着所有该进程打开的文件的指针。
文件描述符是什么
先说files,它是一个文件指针数组。一般来说,一个进程会从files[0]读取输入,将输出写入files[1],将错误信息写入files[2]。
举个例子,以我们的角度 C 语言的printf函数是向命令行打印字符,但是从进程的角度来看,就是向files[1]写入数据;同理,scanf函数就是进程试图从files[0]这个文件中读取数据。
每个进程被创建时,files的前三位被填入默认值,分别指向标准输入流、标准输出流、标准错误流。我们常说的「文件描述符」就是指这个文件指针数组的索引,所以程序的文件描述符默认情况下 0 是输入,1 是输出,2 是错误。
我们可以重新画一幅图:
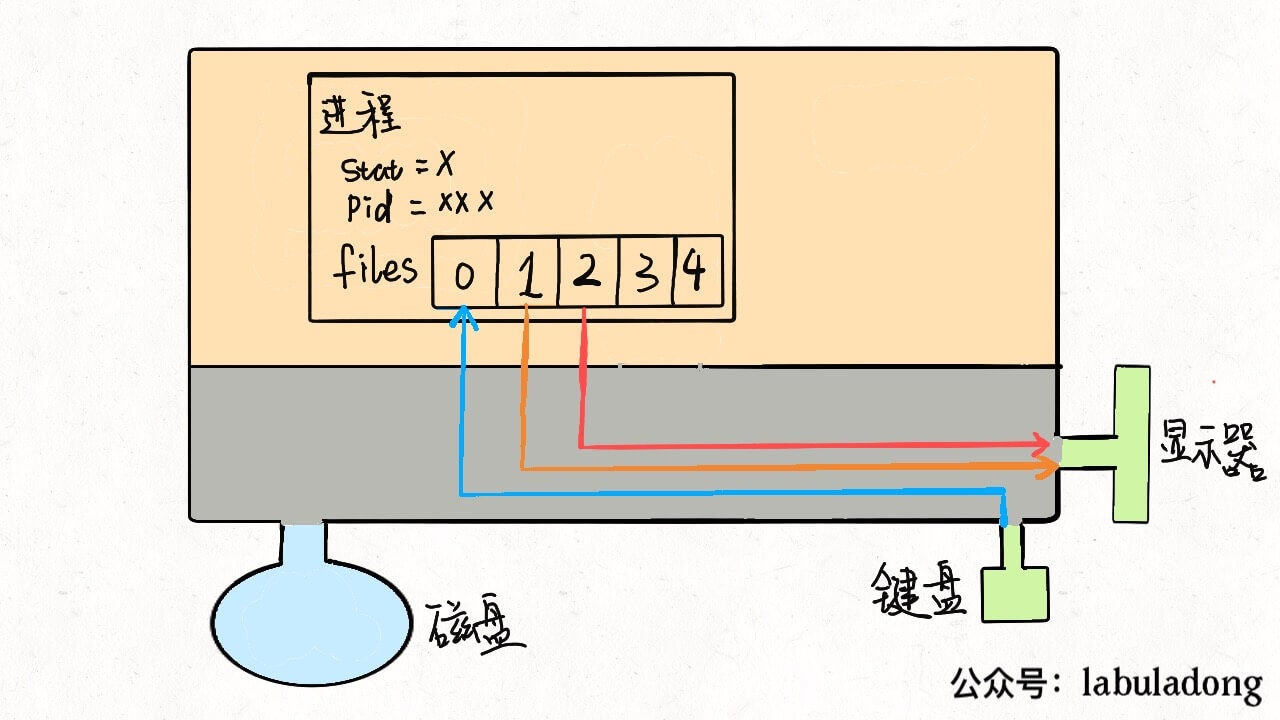
对于一般的计算机,输入流是键盘,输出流是显示器,错误流也是显示器,所以现在这个进程和内核连了三根线。因为硬件都是由内核管理的,我们的进程需要通过「系统调用」让内核进程访问硬件资源。
PS:不要忘了,Linux 中一切都被抽象成文件,设备也是文件,可以进行读和写。
如果我们写的程序需要其他资源,比如打开一个文件进行读写,这也很简单,进行系统调用,让内核把文件打开,这个文件就会被放到files的第 4 个位置:
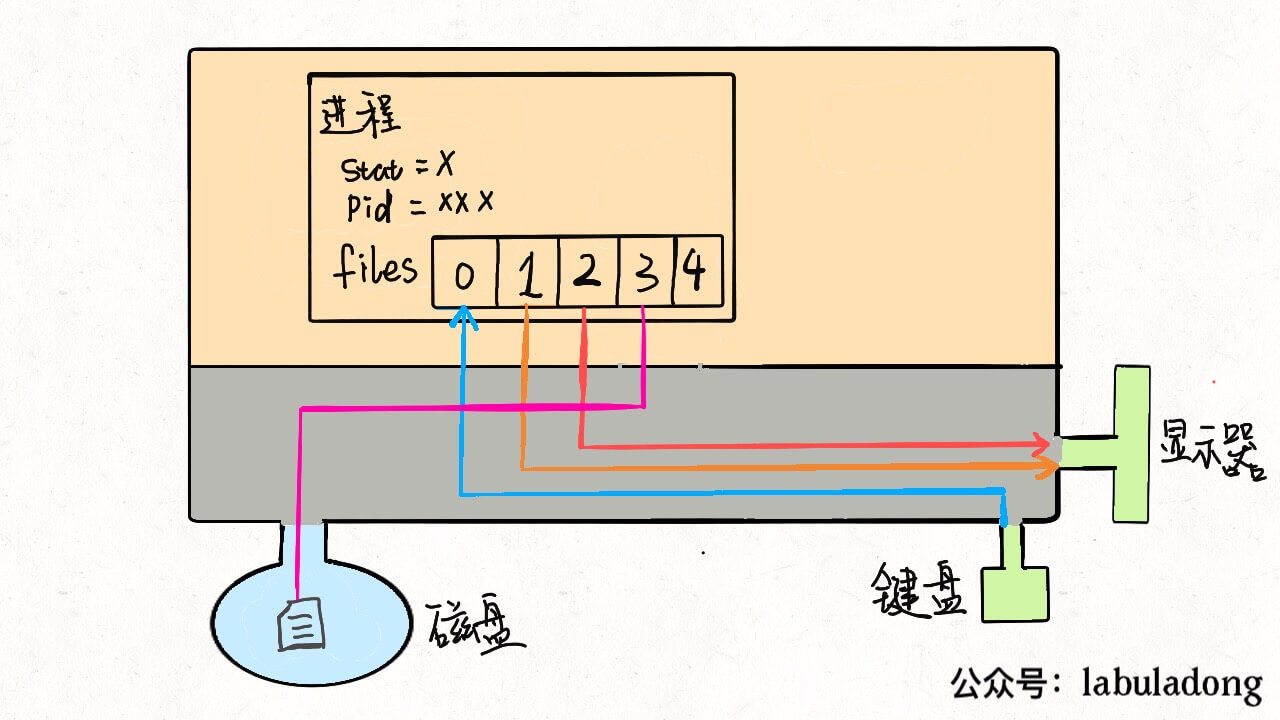
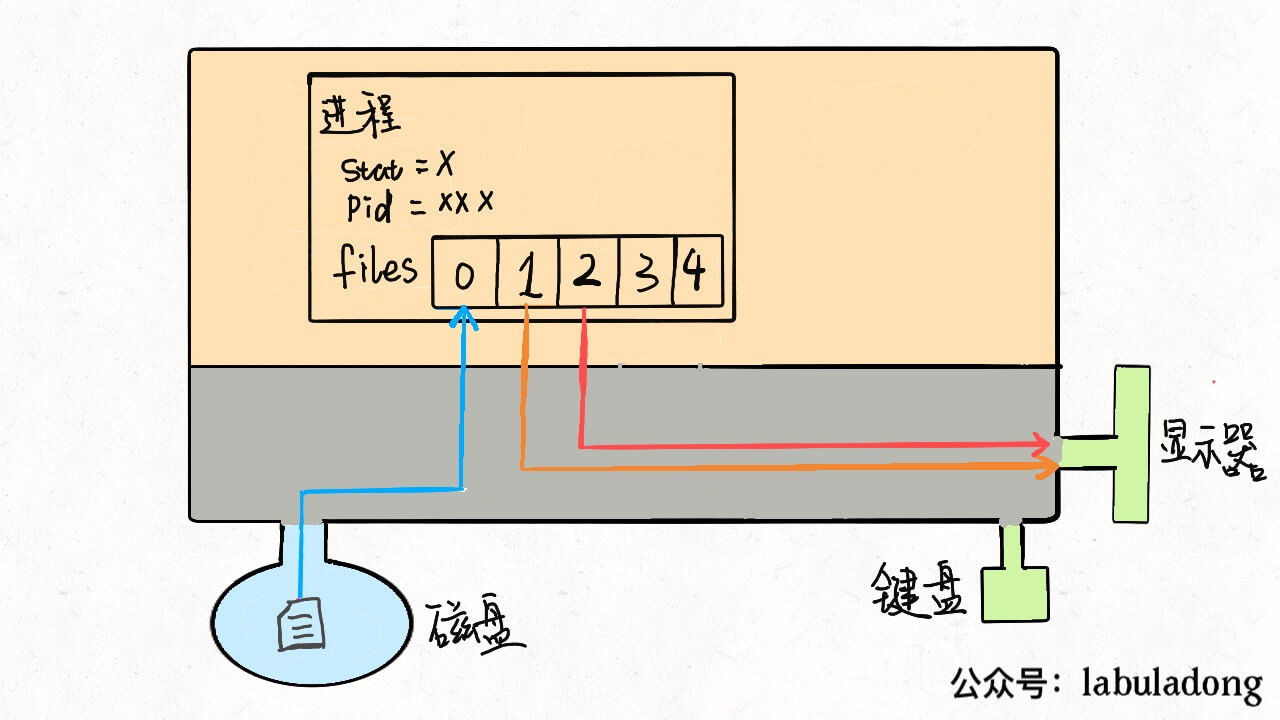
明白了这个原理,输入重定向就很好理解了,程序想读取数据的时候就会去files[0]读取,所以我们只要把files[0]指向一个文件,那么程序就会从这个文件中读取数据,而不是从键盘:
$ command < file.txt
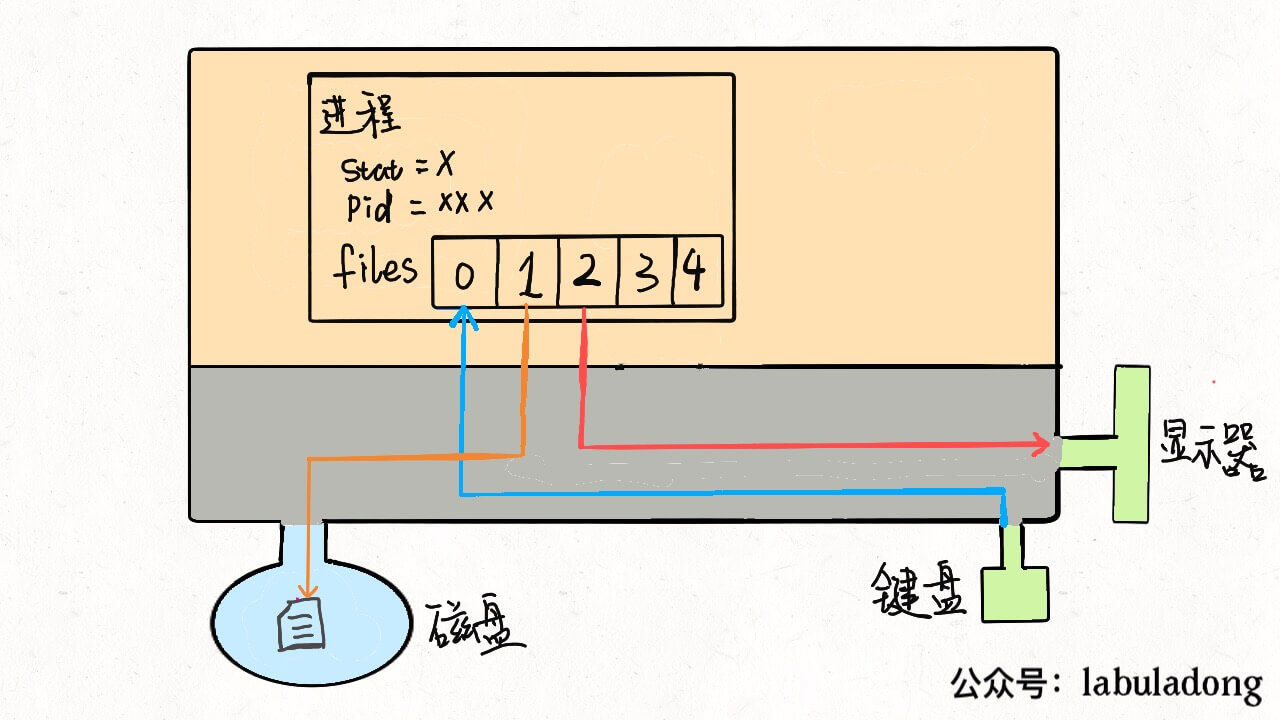
同理,输出重定向就是把files[1]指向一个文件,那么程序的输出就不会写入到显示器,而是写入到这个文件中:
$ command > file.txt
错误重定向也是一样的,就不再赘述。
管道符其实也是异曲同工,把一个进程的输出流和另一个进程的输入流接起一条「管道」,数据就在其中传递,不得不说这种设计思想真的很优美:
$ cmd1 | cmd2 | cmd3
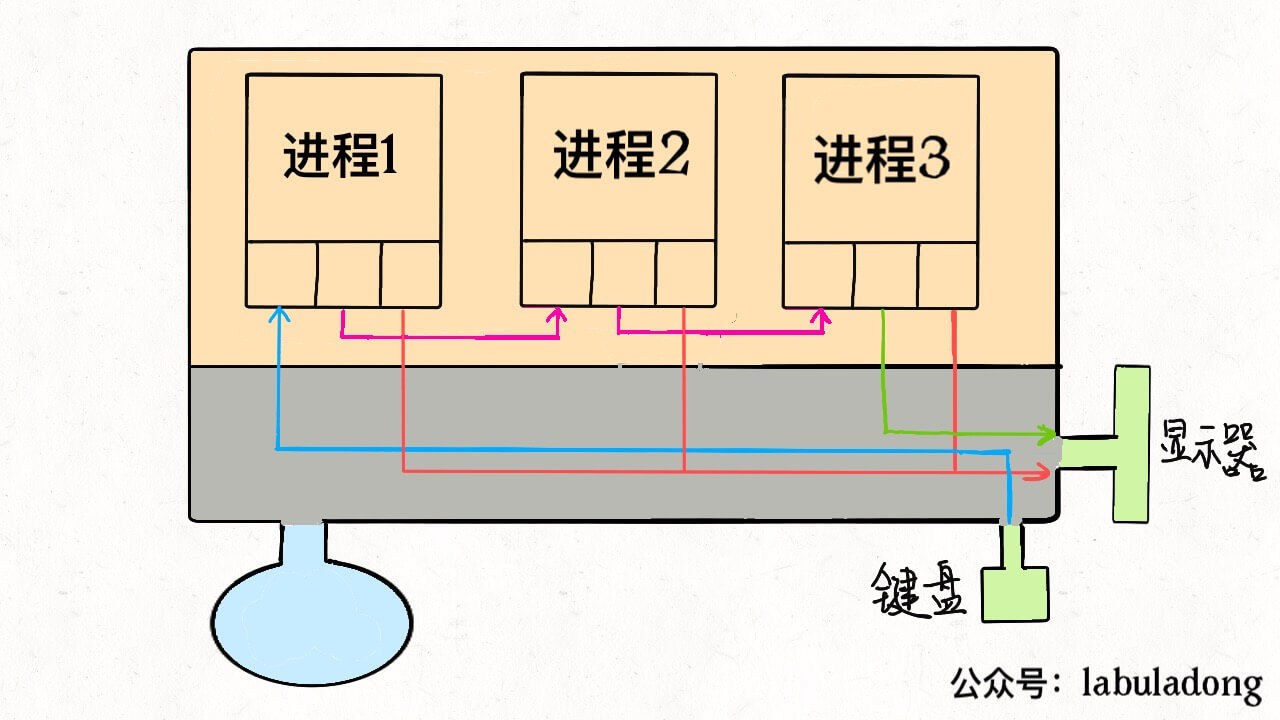
到这里,你可能也看出「Linux 中一切皆文件」设计思路的高明了,不管是设备、另一个进程、socket 套接字还是真正的文件,全部都可以读写,统一装进一个简单的files数组,进程通过简单的文件描述符访问相应资源,具体细节交于操作系统,有效解耦,优美高效。
线程是什么
首先要明确的是,多进程和多线程都是并发,都可以提高处理器的利用效率,所以现在的关键是,多线程和多进程有啥区别。
为什么说 Linux 中线程和进程基本没有区别呢,因为从 Linux 内核的角度来看,并没有把线程和进程区别对待。
我们知道系统调用fork()可以新建一个子进程,函数pthread()可以新建一个线程。但无论线程还是进程,都是用task_struct结构表示的,唯一的区别就是共享的数据区域不同。
换句话说,线程看起来跟进程没有区别,只是线程的某些数据区域和其父进程是共享的,而子进程是拷贝副本,而不是共享。就比如说,mm结构和files结构在线程中都是共享的,我画两张图你就明白了:
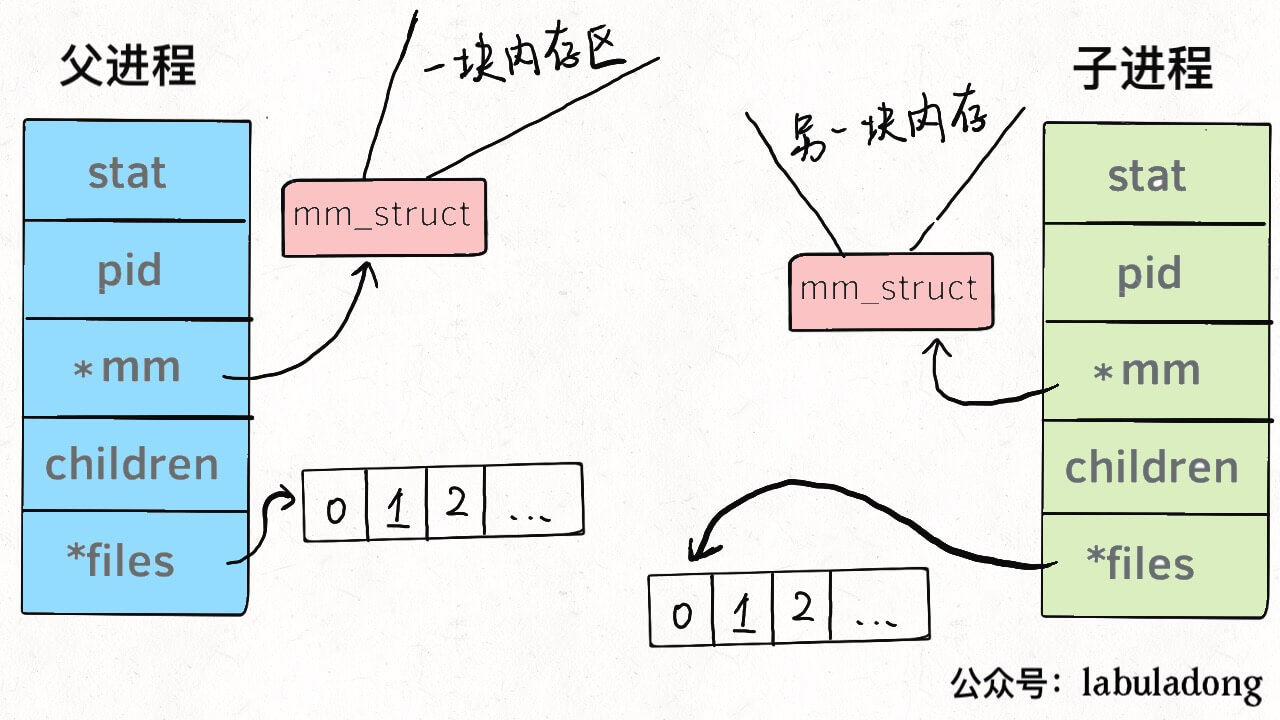
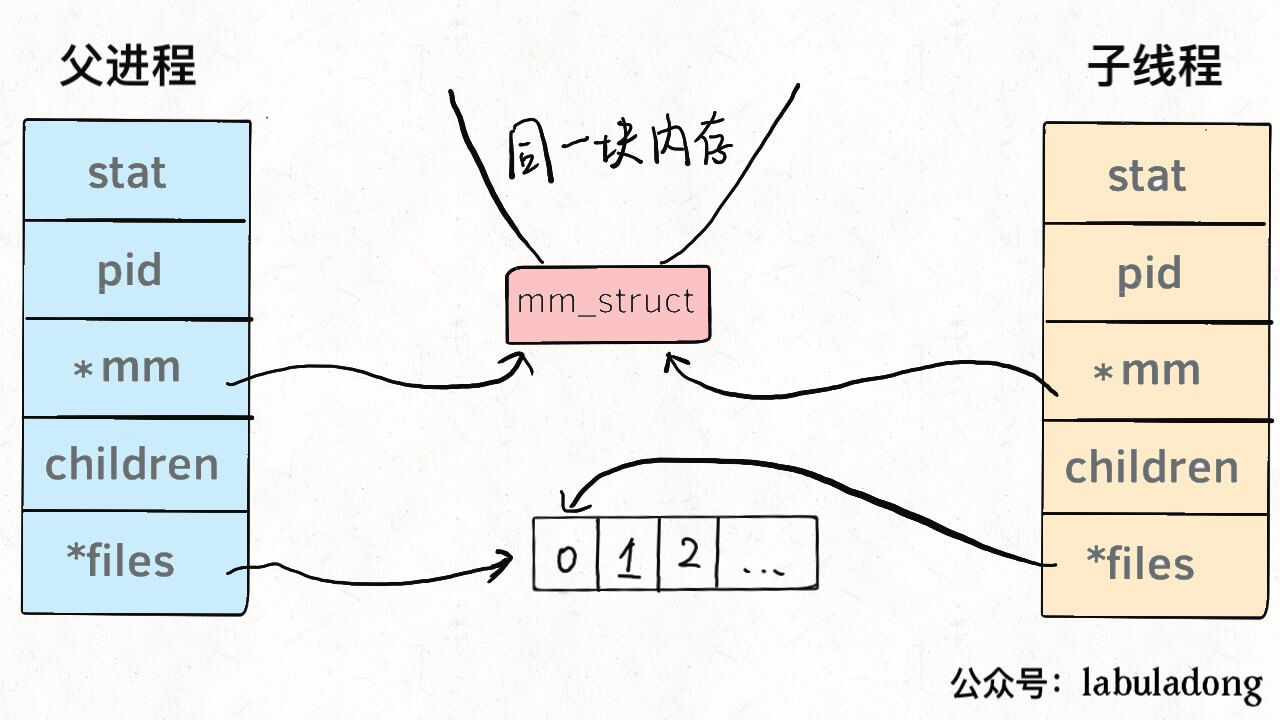
所以说,我们的多线程程序要利用锁机制,避免多个线程同时往同一区域写入数据,否则可能造成数据错乱。
那么你可能问,既然进程和线程差不多,而且多进程数据不共享,即不存在数据错乱的问题,为什么多线程的使用比多进程普遍得多呢?
因为现实中数据共享的并发更普遍呀,比如十个人同时从一个账户取十元,我们希望的是这个共享账户的余额正确减少一百元,而不是希望每人获得一个账户的拷贝,每个拷贝账户减少十元。
当然,必须要说明的是,只有 Linux 系统将线程看做共享数据的进程,不对其做特殊看待,其他的很多操作系统是对线程和进程区别对待的,线程有其特有的数据结构,我个人认为不如 Linux 的这种设计简洁,增加了系统的复杂度。
在 Linux 中新建线程和进程的效率都是很高的,对于新建进程时内存区域拷贝的问题,Linux 采用了 copy-on-write 的策略优化,也就是并不真正复制父进程的内存空间,而是等到需要写操作时才去复制。所以 Linux 中新建进程和新建线程都是很迅速的。
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~