手撕四大限流算法
在开发高并发系统时,有三把利器用来保护系统:缓存、降级和限流。那么何为限流呢?顾名思义,限流就是限制流量,就像你宽带包了1个G的流量,用完了就没了。通过限流,我们可以很好地控制系统的qps,从而达到保护系统的目的。本篇文章将会介绍一下常用的限流算法以及他们各自的特点。
1,计数器限流算法
计数器算法是限流算法里最简单也是最容易实现的一种算法。
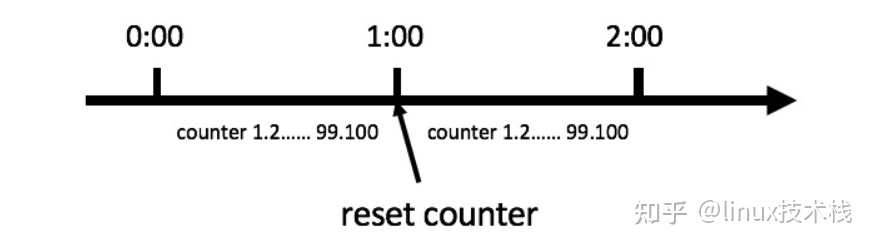
比如我们规定,对于A接口来说,我们1分钟的访问次数不能超过100个。
那么我们可以这么做:在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个 请求的间隔时间还在1分钟之内,那么说明请求数过多;
如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,具体算法的示意图如下:
2,Java实现计数器限流算法
public interface TrafficLimiter {
/**
* 限流
*/
Boolean limit();
}
/**
* 计数器限流算法
*/
public class CounterLimiter implements TrafficLimiter {
private long timestamp = System.currentTimeMillis();
//请求次数
private int reqCount;
//每秒限流的最大请求数
private int limitNum = 100;
//时间窗口时长,单位ms
private long interval = 1000L;
/**
* 返回true表示限流,false代表通过
* @return
*/
@Override
public synchronized Boolean limit() {
long now = System.currentTimeMillis();
//在当前时间窗口内
if(now < timestamp + interval){
//判断当前时间窗口请求数加1是否超过每秒限流的最大请求数
if(reqCount + 1 > limitNum){
return true;
}
reqCount++;
return false;
}else{
//开启新的时间窗口
timestamp = now;
//重置计数器
reqCount = 1;
return false;
}
}
}
用法如下(以下算法的用法相同)
public class Test {
TrafficLimiter limiter = new CounterLimiter();
/**
* 模拟controller接口
*/
public void testLimiter(){
if(limiter.limit()){
System.out.println("被限流了。。。");
return;
}
System.out.println("执行业务逻辑。。。");
}
}
这个算法虽然简单,但是有一个十分致命的问题,那就是临界问题,我们看下图
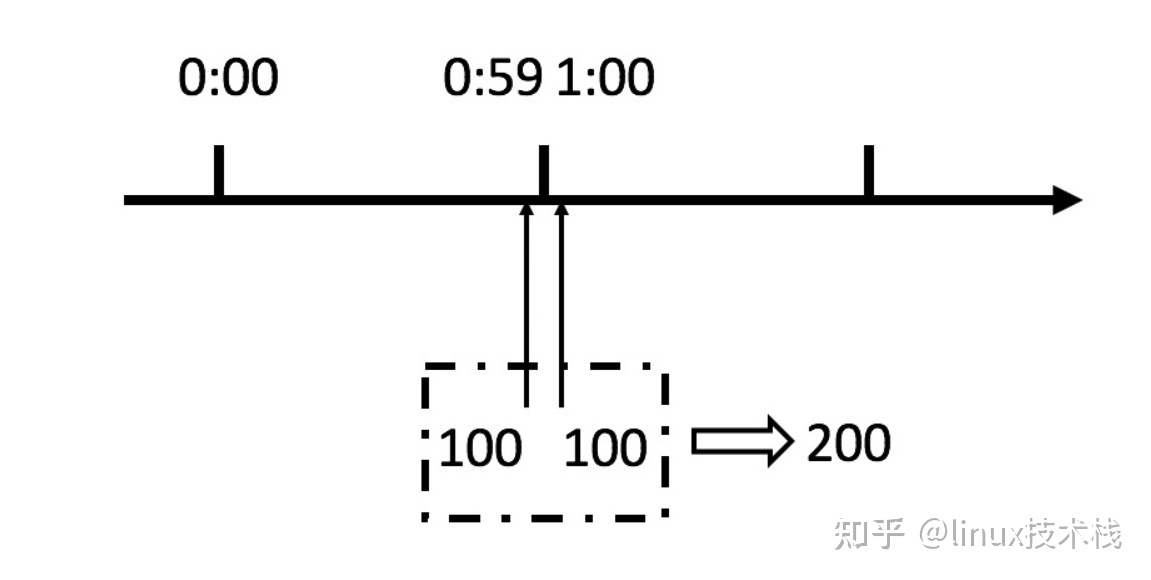
从上图中我们可以看到,假设有一个恶意用户,他在0:59时,瞬间发送了100个请求,并且1:00又瞬间发送了100个请求,那么其实这个用户在 1秒里面,瞬间发送了200个请求。
我们刚才规定的是1分钟最多100个请求,也就是每秒钟最多1.7个请求,用户通过在时间窗口的重置节点处突发请求, 可以瞬间超过我们的速率限制。用户有可能通过算法的这个漏洞,瞬间压垮我们的应用。
聪明的朋友可能已经看出来了,刚才的问题其实是因为我们统计的精度太低。那么如何很好地处理这个问题呢?或者说,如何将临界问题的影响降低呢?我们可以看下面的滑动窗口算法
3,滑动时间窗口限流算法
滑动窗口,又称rolling window。为了解决这个问题,我们引入了滑动窗口算法。如果学过TCP网络协议的话,那么一定对滑动窗口这个名词不会陌生。下面这张图,很好地解释了滑动窗口算法
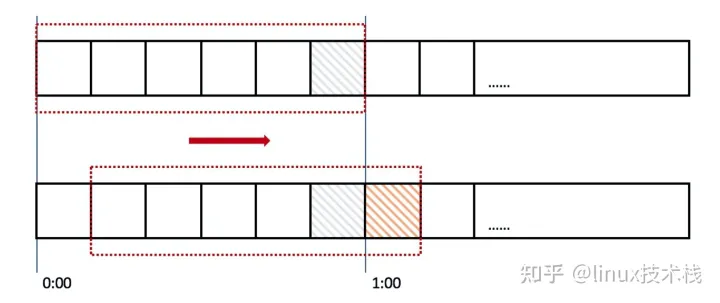
在上图中,整个红色的矩形框表示一个时间窗口,在我们的例子中,一个时间窗口就是一分钟。
然后我们将时间窗口进行划分,比如图中,我们就将滑动窗口划成了6格,所以每格代表的是10秒钟。每过10秒钟,我们的时间窗口就会往右滑动一格。
每一个格子都有自己独立的计数器counter,比如当一个请求 在0:35秒的时候到达,那么0:30~0:39对应的counter就会加1。
那么滑动窗口怎么解决刚才的临界问题的呢?
我们可以看上图,0:59到达的100个请求会落在灰色的格子中,而1:00到达的请求会落在橘黄色的格 子中。
当时间到达1:00时,我们的窗口会往右移动一格,那么此时时间窗口内的总请求数量一共是200个,超过了限定的100个,所以此时能够检测出来触 发了限流。
我再来回顾一下刚才的计数器算法,我们可以发现,计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,所以只有1格。
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
滑动窗口限流解决了固定窗口临界值的问题,可以保证任意时间窗口内都不会超过限流阀值。
相对于固定窗口,滑动窗口除了需要引入计数器外,还需要额外记录时间窗口内每个请求到达的时间点。
以时间窗口为1秒为例,规则如下:
- 记录每次请求的时间;
- 统计每次请求的时间向前推1秒这个时间窗口内的请求数,且1秒前的数据可以删除;
- 统计的请求数小于阀值则记录该请求的时间,并允许通过,反之则拒绝该请求;
虽然看起来很OK,但是滑动窗口也无法解决短时间之内集中流量的冲击。
例如每秒限制1000个请求,但是有可能存在前5毫秒的时候,阀值就被打满的情况,理想情况下每10毫秒来100个请求,那么系统对流量的处理就会更加平滑。
但在真实场景中是很难控制请求的频率的。所以为了解决时间窗口类算法的痛点,又出现了漏桶算法。
4,Java实现滑动窗口限流算法
import java.util.LinkedList;
/**
* 滑动时间窗口限流算法
*/
public class SlidingTimeWindowLimiter implements TrafficLimiter{
//服务在最近1秒内的访问次数,可以放在redis中,实现分布式系统的访问计数
private int reqCount;
//使用LinkedList来记录滑动窗口的10个格子
private LinkedList<Integer> slots = new LinkedList<>();
//每秒限流的最大请求数
private int limitNum = 100;
//滑动时间窗口里的每个格子的时间长度,单位ms
private long windowLength = 100L;
//滑动时间窗口的格子数量
private int windowNum = 10;
/**
* 返回true表示限流,false代表通过
* @return
*/
@Override
public synchronized Boolean limit() {
if((reqCount + 1) > limitNum){
return true;
}
slots.set(slots.size() - 1,slots.peekLast() + 1);
reqCount++;
return false;
}
public SlidingTimeWindowLimiter(){
slots.addLast(0);
new Thread(()->{
while (true){
try {
Thread.sleep(windowLength);
} catch (InterruptedException e) {
e.printStackTrace();
}
slots.addLast(0);
if(slots.size() > windowNum){
reqCount = reqCount - slots.peekFirst();
slots.removeFirst();
System.out.println("滑动格子:" + reqCount);
}
}
}).start();
}
}
5,漏桶限流算法
漏桶算法的基本思想是,流量持续进入漏桶中,底部则定速处理请求,如果流量进入的速率高于底部请求被处理的速率,且当桶中的流量超过桶的大小时,流量就会被溢出。具体如下图所示
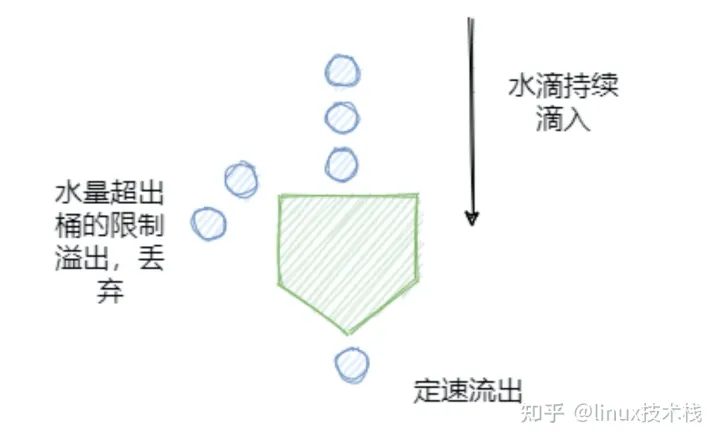
漏桶算法的特点是宽进严出,无论请求的速率有多大,底部的处理速度都匀速进行。这种算法的特点有点类似于消息队列的处理机制,一般来说漏桶算法也是由队列来实现的。
但漏桶算法的这种特点,实际上即是它的优点也是缺点。
有时候面对突发流量,我们往往会希望在保持系统稳定的同时,能更快地处理用户请求以提升用户体验,而不是按部就班的佛系工作。
在这种情况下又出现了令牌桶这样的限流算法,它在应对突发流量时,可以比漏桶算法更加激进。
6,Java实现漏桶限流算法
/**
* 漏桶算法
*/
public class LeakyBucketLimiter implements TrafficLimiter{
private long timestamp = System.currentTimeMillis();
//桶的容量
private long capacity = 100;
//水漏出的速度(每秒系统能处理的请求数)
private long rate = 10;
//当前水量(当前累计请求数)
private long water = 20;
/**
* 返回true表示限流,false代表通过
* @return
*/
@Override
public Boolean limit() {
long now = System.currentTimeMillis();
//先执行漏水,计算剩余水量(计算剩余请求数)
water = Math.max(0,water - ((now - timestamp) / 1000) * rate);
timestamp = now;
if((water + 1) < capacity){
//水还未满,加水
water++;
return false;
}else{
//水满,拒绝加水
return true;
}
}
}
7,令牌桶限流算法
令牌桶与漏桶的原理类似,只是漏桶是底部匀速处理,而令牌桶则是定速的向桶里塞入令牌,然后请求只有拿到了令牌才会被服务器处理。
具体规则如下:
- 定速的向桶中放入令牌;
- 令牌数量超过桶的限制,则丢弃;
- 请求来了先向桶中索取令牌,索取成功则通过被处理,否则拒绝;
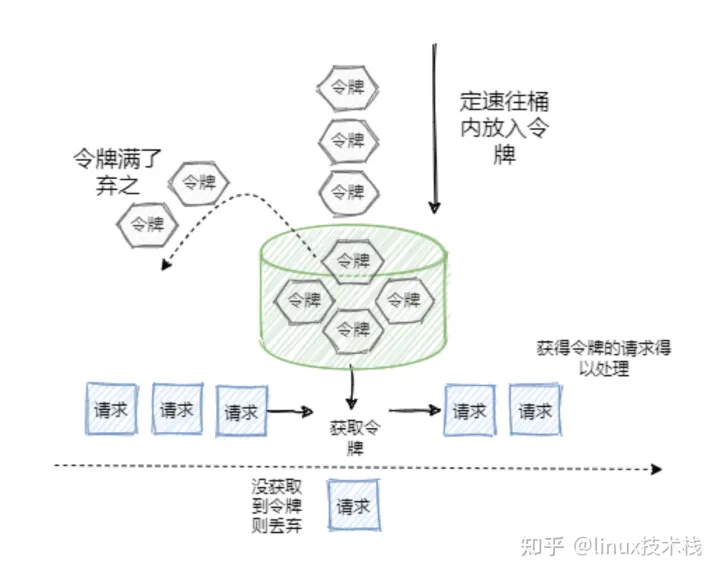
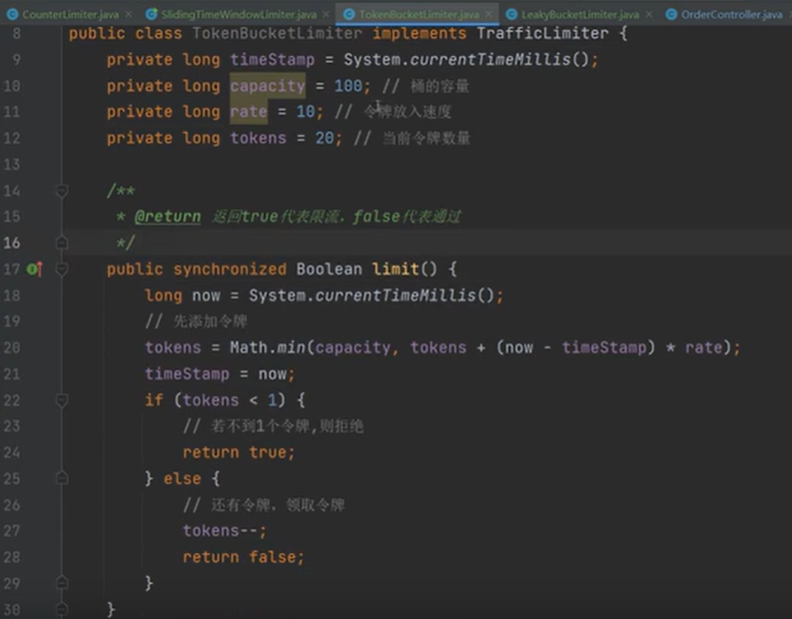
可以看出令牌桶在应对突发流量时,不会想漏桶那样匀速的处理,而是在短时间内请求可以同时取走桶中的令牌,并及时的被服务器处理。所以在应对突发流量的场景下,令牌桶表现更强。
8,限流算法总结
经过上述的描述,好像漏桶、令牌桶比时间窗口类算法好多了,那么时间窗口类算法是不是就没啥用了呢?
- 其实并不是,虽然漏桶、令牌桶对比时间窗口类算法对流量的整形效果更好,但是它们也有各自的缺点,
- 例如令牌桶,假如系统上线时没有预热,那么可能会出现由于此时桶中还没有令牌,而导致请求被误杀的情况;
- 而漏桶中由于请求是暂存在桶中的,所以请求什么时候能被处理,则是有延时的,这并不符合互联网业务低延时的要求。
所以令牌桶、漏桶算法更适合阻塞式限流的场景,即后台任务类的限流。
而基于时间窗口的限流则更适合互联网实施业务限流的场景,即能处理快速处理,不能处理及时响应调用方,避免请求出现过长的等待时间。
9,微服务限流组件
如果你有兴趣实际上也是可以自己实现一个限流组件的,只不过这种轮子已经早有人造好了。
目前市面上比较流行的限流组件主要有:Google Guava提供的限流工具类“RateLimiter”、阿里开源的Sentinel。
其中Google Guava提供的限流工具类“RateLimiter”,是基于令牌桶实现的,并且扩展了算法,支持了预热功能。
而阿里的Sentinel中的匀速限流策略,就是采用了漏桶算法。
10,单机限流和分布式限流
本质上单机限流和分布式限流的区别其实就在于 “阈值” 存放的位置。
单机限流就上面所说的算法直接在单台服务器上实现就好了,而往往我们的服务是集群部署的。因此需要多台机器协同提供限流功能。
像上述的计数器或者时间窗口的算法,可以将计数器存放至 Tair 或 Redis 等分布式 K-V 存储中。
例如滑动窗口的每个请求的时间记录可以利用 Redis 的 zset 存储,利用ZREMRANGEBYSCORE 删除时间窗口之外的数据,再用 ZCARD计数。
像令牌桶也可以将令牌数量放到 Redis 中。
不过这样的方式等于每一个请求我们都需要去Redis判断一下能不能通过,在性能上有一定的损耗,所以有个优化点就是 「批量」。例如每次取令牌不是一个一取,而是取一批,不够了再去取一批。这样可以减少对 Redis 的请求。
不过要注意一点,批量获取会导致一定范围内的限流误差。比如你取了 10 个此时不用,等下一秒再用,那同一时刻集群机器总处理量可能会超过阈值。
其实「批量」这个优化点太常见了,不论是 MySQL 的批量刷盘,还是 Kafka 消息的批量发送还是分布式 ID 的高性能发号,都包含了「批量」的思想。
当然分布式限流还有一种思想是平分,假设之前单机限流 500,现在集群部署了 5 台,那就让每台继续限流 500 呗,即在总的入口做总的限流限制,然后每台机子再自己实现限流。
11,限流的难点
可以看到每个限流都有个阈值,这个阈值如何定是个难点。
定大了服务器可能顶不住,定小了就“误杀”了,没有资源利用最大化,对用户体验不好。
我能想到的就是限流上线之后先预估个大概的阈值,然后不执行真正的限流操作,而是采取日志记录方式,对日志进行分析查看限流的效果,然后调整阈值,推算出集群总的处理能力,和每台机子的处理能力(方便扩缩容)。
然后将线上的流量进行重放,测试真正的限流效果,最终阈值确定,然后上线。
我之前还看过一篇耗子叔的文章,讲述了在自动化伸缩的情况下,我们要动态地调整限流的阈值很难,于是基于TCP拥塞控制的思想,
根据请求响应在一个时间段的响应时间P90或者P99值来确定此时服务器的健康状况,来进行动态限流。
在他的 Ease Gateway 产品中实现了这套算法,有兴趣的同学可以自行搜索。
其实真实的业务场景很复杂,需要限流的条件和资源很多,每个资源限流要求还不一样。所以我上面就是嘴强王者。
12,限流组件
一般而言我们不需要自己实现限流算法来达到限流的目的,不管是接入层限流还是细粒度的接口限流其实都有现成的轮子使用,其实现也是用了上述我们所说的限流算法。
比如Google Guava 提供的限流工具类 RateLimiter,是基于令牌桶实现的,并且扩展了算法,支持预热功能。
阿里开源的限流框架Sentinel 中的匀速排队限流策略,就采用了漏桶算法。
Nginx 中的限流模块 limit_req_zone,采用了漏桶算法,还有 OpenResty 中的 resty.limit.req库等等。
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!
