
大数据开发之Kafka和Kafka Restful Proxy的入门教程
kafka概述&快速入门
Kafka架构深入&KafkaAPI
Kafka基础
Kafka-Eagle监控&Kraft模式
kafka生产调优手册
kafka源码主内容解析
一,安装单机版kafka(linux环境)
1、安装kafka,首先需要jdk
2、然后安装kafka,需要zk,作为心跳节点
zookeeper下载地址:https://downloads.apache.org/zookeeper/
kafka下载地址:https://archive.apache.org/dist/kafka/
1,安装zookeeper并启动
解压zookeeper,然后重命名
[root@VM-4-2-centos zookeeper]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
[root@VM-4-2-centos zookeeper]# mv apache-zookeeper-3.5.7-bin zookeeper
zookeeper有个很无语的地方,conf文件下有个配置文件需要重命名
[root@VM-4-2-centos zookeeper]# cd zookeeper/conf/
[root@VM-4-2-centos conf]# mv zoo_sample.cfg zoo.cfg
修改zoo.cfg配置文件的日志路径,在zoo.cfg后面加上一句(zk需要一个端口备用,默认是8080) 为了防止8080端口被占用
[root@VM-4-2-centos conf]# pwd
/opt/zookeeper/zookeeper/conf
[root@VM-4-2-centos conf]# vi zoo.cfg
admin.serverPort=8888
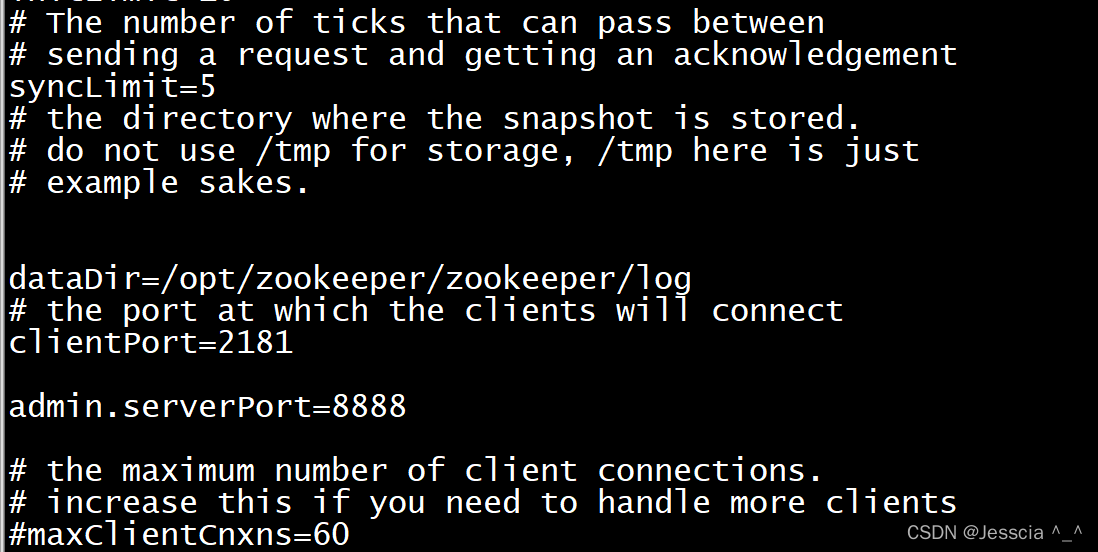
外面创建log文件夹,然后启动
[root@VM-4-2-centos conf]# cd ../ && mkdir log
[root@VM-4-2-centos zookeeper]# ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
检查一下是否启动,出现QuorumPeerMain,代表zk启动成功,如果没有的话,可以去当前的logs文件夹看日志,一般的人是不会教你这些的
[root@VM-4-2-centos zookeeper]# jps
2699880 QuorumPeerMain
1740700 Bootstrap
2700101 Jps
[root@VM-4-2-centos zookeeper]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 2699880 root 51u IPv6 108690897 0t0 TCP *:eforward (LISTEN)
1,安装kafka并启动
先解压kafka安装包,然后重命名
[root@VM-4-2-centos zookeeper]# tar -zxvf kafka_2.13-3.0.1.tgz
[root@VM-4-2-centos zookeeper]# mv kafka_2.13-3.0.1 kafka
进入配置文件目录
[root@VM-4-2-centos zookeeper]# cd kafka/config/
[root@VM-4-2-centos config]# pwd
/opt/zookeeper/kafka/config
[root@VM-4-2-centos config]# vi server.properties
需要修改两个地方,一个是advertised后面,添加你的公网ip地址,可以通过curl ifconfig.me查看;另外一个是日志位置
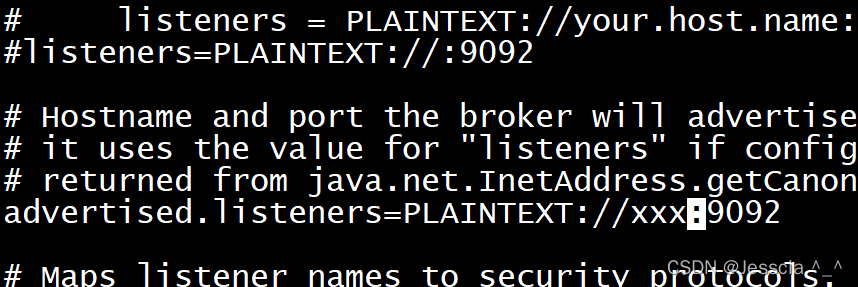

启动kafka
[root@VM-4-2-centos config]# cd ..
[root@VM-4-2-centos kafka]# ./bin/kafka-server-start.sh -daemon ./config/server.properties &
查看状态,启动成功
[root@VM-4-2-centos kafka]# jps
2699880 QuorumPeerMain
1740700 Bootstrap
2702798 Jps
2702533 Kafka
[root@VM-4-2-centos kafka]# lsof -i:9092
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 2702533 root 134u IPv6 108700509 0t0 TCP *:XmlIpcRegSvc (LISTEN)
二,配置kafka集群环境
TODO
三,kafka入门使用
1,server.properties核心配置详解

2,测试基本使用
#1、创建主题(topic)
./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
#为主题创建多个分区,由--partitions参数指定
./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 2 --topic test
#2、查看已创建topic
./kafka-topics.sh --list --bootstrap-server localhost:9092
#查看topic详细信息
./kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic testA
#3、创建生产者
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
#4、创建消费者
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning #从头开始消费
#5、查看消费组及信息
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list #查看当前主题下有哪些消费组
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testGroup #查看消费组中的具体信息
往生产者窗口写入消息,消费者窗口也能同步的接收到消息

消费者组指标描述:
- Currennt-offset:当前消费组的已消费偏移量
- Log-end-offset:主题对应分区消息的结束偏移量(HW)
- Lag:当前消费组未消费的消息数
3,Kafka的基本概念

副本是对分区的备份。在集群中,不同的副本会被部署在不同的broker上,查看topic详细信息如下

通过查看主题信息,其中的关键数据:
replicas:当前副本存在的broker节点;
leader:副本里的概念,leader专⻔用来接收消息。接收到消息,其他follower通过poll的方式来同步数据,每个partition都在不同的Broker上。消息发送方要把消息发给哪个broker?就看副本的leader是在个broker上面;
follower:follower负责从leader同步数据,不提供读写;
isr: 可以同步的broker节点和已同步的broker节点,存放在isr集合中;
4,Kafka中的细节
- 消息是按照发送的顺序进行存储,因此消费者在消费消息时可以指明主题中消息的偏移量(默认情况下,是从最后一个消息的下一个偏移量开始消费);
- 如果多个消费者在同⼀个消费组,那么只有⼀个消费者可以收到订阅的topic中的消息(换⾔之,同⼀个消费组中只能有⼀个消费者收到⼀个topic中的消息);
- 不同的消费组订阅同⼀个topic,那么不同的消费组中只有⼀个消费者能收到消息;
Kafka消息存放目录结构如下

__consumer_offsets是Kafka内部主题,默认创建50个分区(可以通过offsets.topic.num.partitions设置),主要用于存储消费者的偏移量,图示如下

消费者会定期将自己消费分区的offset提交给__consumer_offsets,key是consumerGroupId+topic+分区号,value就是当前offset的值,并且kafka会定期清理topic里的消息仅保留最新的那条数据,通过如下公式可以选出consumer消费的offset要提交到__consumer_offsets的哪个分区
hash(consumerGroupId) % __consumer_offsets主题的分区数

文件具体作用如下:
- 00000000000000000000.log:消息数据;
- 00000000000000000000.index:用于根据位移值快速查找消息所在文件位置;
- 00000000000000000000.timeindex:用于根据时间戳快速查找特定消息的位移值;
四,Kafka的Java客户端-生产者
引入依赖(建议版本与Kafka一致)
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.1.0</version>
</dependency>
package com.ftx.kafka.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class ProducerTest {
private final static String TOPIC_NAME = "my-topic";
public static void main(String[] args)throws ExecutionException, InterruptedException {
Properties props = new Properties();
//Kafka地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "101.201.101.206:9092");
//把发送的key从字符串序列化为字节数组
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//把发送消息value从字符串序列化为字节数组
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//缓冲区大小设置--kafka默认会创建⼀个消息缓冲区,⽤来存放要发送的消息,缓冲区是32m
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
//拉取设置--kafka本地线程会去缓冲区中⼀次拉16k的数据,发送到broker
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//如果线程拉不到16k的数据,间隔10ms也会将已拉到的数据发到broker
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
//ack参数配置,适用于同步发送情况,下面细讲
//props.put(ProducerConfig.ACKS_CONFIG, "1");
//重试次数
props.put(ProducerConfig.RETRIES_CONFIG, 3);
//重试间隔设置,发送失败会重试,默认重试间隔100ms
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
Producer<String, String> producer = new KafkaProducer<>(props);
//发送主题与内容
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(TOPIC_NAME, "123");
//发送到指定分区
//ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME,0, "1","123");
//未指定分区,则会通过业务key的hash运算,算出消息往哪个分区上发
// ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME,"2","123");
//同步发消息,在收到kafka的ack告知发送成功之前一直处于阻塞状态
//RecordMetadata metadata = producer.send(producerRecord).get();
//=====阻塞=======
//System.out.println("同步方式发送消息结果:" + "topic-" + metadata.topic() + "|partition-" + metadata.partition() + "|offset-" + metadata.offset());
//异步发消息
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("发送消息失败:" +
exception.getStackTrace());
}
if (metadata != null) {
System.out.println("异步方式发送消息结果:" + "topic-" +metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" + metadata.offset());
}
}
});
//因为是异步发,避免main线程立马结束,故休眠1s
Thread.sleep(1000);
}
}
//同步方式发送消息结果:topic-my-topic|partition-0|offset-1
//异步方式发送消息结果:topic-testA|partition-0|offset-14
new ProducerRecord()有多个构造方法,如果有指定分区,那么消息就会被发送到指定分区。如果未指定分区,则会通过key的hash运算,算出消息往哪个分区上发。如果既没有key也没有指定分区(或者key为null),那么消息将会随机发送到一个分区;
关于生产者的ack参数配置
在同步发送的前提下,⽣产者在获得集群返回的ack之前会⼀直阻塞。那么集群什么时候返回ack呢?
此时ack有3个配置
- ack = 0:kafka-cluster不需要任何的broker收到消息,就⽴即返回ack给⽣产者,最容易丢消息的,效率是最⾼的;
- ack = 1(默认): 多副本之间的leader已经收到消息,并把消息写⼊到本地的log中,才会返回ack给⽣产者,性能和安全性均衡;
- ack = -1/all:依赖配置min.insync.replicas(默认为1,推荐配置⼤于等于2),例如min.insync.replicas=2此时就需要leader和⼀个follower同步完后,才会返回ack给⽣产者,这种⽅式最安全,但性能最差;
五,Kafka的Java客户端-消费者
package com.ftx.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerTest {
private final static String TOPIC_NAME = "my-topic";
private final static String CONSUMER_GROUP_NAME = "console-consumer-9076";
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"101.201.101.206:9092");
// 消费分组名
props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME);
//配置序列化
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//创建一个消费者的客户端
KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(props);
// 消费者订阅主题列表
consumer.subscribe(Arrays.asList(TOPIC_NAME));
//指定分区消费
// consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
//从头消费
//consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME,0)));
//指定offset消费
//consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);
//poll() API 是拉取消息的⻓轮询
ConsumerRecords<String, String> records =consumer.poll(Duration.ofMillis( 1000 ));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("收到消息:partition = %d,offset = %d, key =%s, value = %s%n", record.partition(),record.offset(), record.key(), record.value());
}
}
}
1,关于消费者⾃动提交和⼿动提交offset
消费者⽆论是⾃动提交还是⼿动提交,都需要把所属的消费组+消费的某个主题+消费的某个分区及消费的偏移量,这样的信息提交到集群的_consumer_offsets主题⾥⾯;
- ⾃动提交:消费者poll消息下来以后就会⾃动提交offset
// 是否⾃动提交offset,默认就是true
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// ⾃动提交offset的间隔时间
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
- ⼿动提交:把⾃动提交的配置改成false
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
⼿动提交⼜分成了两种:
1、⼿动同步提交:在消费完消息后调⽤同步提交的⽅法,当集群返回ack前⼀直阻塞,返回ack后表示提交成功,执⾏之后的逻辑
//所有的消息已消费完
if (records.count() > 0) {//有消息
// ⼿动同步提交offset,当前线程会阻塞直到offset提交成功
// ⼀般使⽤同步提交,因为提交之后⼀般也没有什么逻辑代码了
consumer.commitSync();//=======阻塞=== 提交成功
}
2、⼿动异步提交:在消息消费完后提交,不需要等到集群ack,直接执⾏之后的逻辑,可以设置⼀个回调⽅法,供集群调⽤
if (records.count() > 0) {//有消息
// ⼿动异步提交offset,当前线程提交offset不会阻塞,可以继续处理后⾯的程序逻辑
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception exception) {
if (exception != null) {
System.err.println("Commit failed for " + map);
System.err.println("Commit failed exception: " +
exception.getStackTrace());
}
}
});
}
2,⻓轮询poll消息
默认情况下,消费者⼀次会poll500条消息
//⼀次poll最⼤拉取消息的条数,可以根据消费速度的快慢来设置
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
//如果两次poll的时间如果超出了30s的时间间隔,kafka会认为其消费能⼒过弱,将其踢出消费组。将分区分配给其他消费者
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);
ConsumerRecords<String, String> records =consumer.poll(Duration.ofMillis(1000));
...后续逻辑
代码中设置了⻓轮询的时间是1000毫秒,意味着:
- 如果⼀次poll到500条,就直接往下执行;如果这⼀次没有poll到500条且时间在1秒内,那么⻓轮询继续poll,要么到500
条,要么到1s ,如果多次poll都没达到500条,且1秒时间到了,那么也往下执行‘ - 如果两次poll的间隔超过30s,集群会认为该消费者的消费能⼒过弱,该消费者被踢出消费组,触发rebalance机制,rebalance机制会造成性能开销。
3,消费者的健康状态检查
消费者每隔1s向kafka集群发送⼼跳,集群发现如果有超过10s没有续约的消费者,将被踢出消费组,触发该消费组的rebalance机制,将该分区交给消费组⾥的其他消费者进⾏消费;
//consumer给broker发送⼼跳的间隔时间
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000);
//kafka如果超过10秒没有收到消费者的⼼跳,则会把消费者踢出消费组,进⾏rebalance,把分区分配给其他消费者。
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000);
4,指定时间消费
根据时间,去所有的partition中确定该时间对应的offset,然后去所有的partition中找到该offset之后的消息开始消费
/**
*指定消费30分钟前-now 所创建的消息
*/
public static void consumerBefore30Min(KafkaConsumer<String, String> consumer){
List<PartitionInfo> topicPartitions =
consumer.partitionsFor(TOPIC_NAME);
//从1⼩时前开始消费
long fetchDataTime = System.currentTimeMillis() - 1000 * 60 * 30;
Map<TopicPartition, Long> map = new HashMap<>();
for (PartitionInfo par : topicPartitions) {
map.put(new TopicPartition(TOPIC_NAME, par.partition()),
fetchDataTime);
}
Map<TopicPartition, OffsetAndTimestamp> parMap =
consumer.offsetsForTimes(map);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry :
parMap.entrySet()) {
TopicPartition key = entry.getKey();
OffsetAndTimestamp value = entry.getValue();
if (key == null || value == null) {
continue;
}
Long offset = value.offset();
System.out.println("partition-" + key.partition() +
"|offset-" + offset);
System.out.println();
//根据消费⾥的timestamp确定offset
if (value != null) {
consumer.assign(Arrays.asList(key));
consumer.seek(key, offset);
}
}
}
5,新消费组的消费offset规则
新消费组中的消费者在启动以后,默认会从当前分区的最后⼀条消息的offset+1开始消费(消费新消息)。可以通过以下的设置,让新的消费者第⼀次从头开始消费。之后开始消费新消息(最后消费的位置的偏移量+1)
- Latest:默认配置,消费新消息
- earliest:第⼀次从头开始消费。之后开始消费新消息
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
六,Springboot中使⽤Kafka
1,引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2,编写配置文件
server:
port: 8081
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092
producer:
retries: 3
batch-size: 16384
buffer-memory: 33554432
acks: 1
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default-group
enable-auto-commit: false
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
max-poll-records: 500
listener:
# 当每⼀条记录被消费者监听器(ListenerConsumer)处理之后提交
# RECORD
# 当每⼀批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
# BATCH
# 当每⼀批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间⼤于TIME时提交
# TIME
# 当每⼀批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量⼤于等于COUNT时提交
# COUNT
# TIME | COUNT 有⼀个条件满⾜时提交
# COUNT_TIME
# 当每⼀批poll()的数据被消费者监听器(ListenerConsumer)处理之后, ⼿动调⽤Acknowledgment.acknowledge()后提交
# MANUAL
# ⼿动调⽤Acknowledgment.acknowledge()后⽴即提交,⼀般使⽤这种
# MANUAL_IMMEDIATE
ack-mode: MANUAL_IMMEDIATE
3,编写消息⽣产者
@RestController
@RequestMapping("/msg")
public class MyKafkaController {
private final static String TOPIC_NAME = "testA";
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
@RequestMapping("/send")
public String sendMessage(){
kafkaTemplate.send(TOPIC_NAME,0,"key","this is a message!");
return "send success!";
}
}
4,编写消费者
@Component
public class MyConsumer {
@KafkaListener(topics = "testA")
/* @KafkaListener(groupId = "testGroup", topicPartitions = {
@TopicPartition(topic = "topic1", partitions = {"0", "1"}),
@TopicPartition(topic = "topic2", partitions = "0",
partitionOffsets = @PartitionOffset(partition = "1",
initialOffset = "100"))
},concurrency = "3")//concurrency就是同组下的消费者个数,就是并发消费数,建议⼩于等于分区总数*/
public void listenGroup(ConsumerRecord<String, String> record,
Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
//⼿动提交offset
ack.acknowledge();
}
}
启动项目,执行http://localhost:8081/msg/send,控制台打印
this is a message!
ConsumerRecord(topic = testA, partition = 0, leaderEpoch = 0, offset = 17, CreateTime = 1644403908306, serialized key size = 3, serialized value size = 18, headers = RecordHeaders(headers = [], isReadOnly = false), key = key, value = this is a message!)
七,Kafka集群中的controller、rebalance、HW
1,controller
每个broker启动时会向zk创建⼀个临时序号节点,获得的序号最⼩的那个broker将会作为集群中的controller,负责这么⼏件事:
当集群中有⼀个副本的leader挂掉,需要在集群中选举出⼀个新的leader,选举的规则是从isr集合中最左边获得。
当集群中有broker新增或减少,controller会同步信息给其他broker
当集群中有分区新增或减少,controller会同步信息给其他broker
2,rebalance(重平衡)机制
前提是:消费者没有指明分区消费。当消费组里消费者和分区的关系发生变化,那么就会触发rebalance机制,这个机制会重新调整消费者消费哪个分区。

在触发rebalance机制之前,消费者消费哪个分区有三种策略:
- range:通过公示来计算某个消费者消费哪个分区
- 轮询:大家轮着消费
- sticky:在触发了rebalance后,在消费者消费的原分区不变的基础上进行调整。
- range与轮询会将现有的消费关系全部去除并且重新分配,对性能肯定会有所影响!
八,HW(High WaterMark 高水位)和LEO
LEO是某个副本最后消息的消息位置(log-end-offset)
HW是已完成同步的位置。消息在写⼊broker时,且每个broker完成这条消息的同步后,hw才会变化。在这之前消费者是消费不到这条消息的。在同步完成之后,HW更新之后,消费者才能消费到这条消息,这样的⽬的是防⽌消息的丢失;

九,Kafka相关问题优化
1,如何防⽌消息丢失?
⽣产者:
使⽤同步发送 ;
把ack设成1或者all,并且设置同步的分区数>=2;
消费者:把⾃动提交改成⼿动提交;
2,如何防⽌重复消费?
如果⽣产者发送完消息后,因为⽹络抖动,没有收到ack,但实际上broker已经收到了。此时⽣产者会进⾏重试,于是broker就会收到多条相同的消息,⽽造成消费者的重复消费;
解决方案:
⽣产者关闭重试,会造成丢消息(不建议)
消费者解决⾮幂等性消费问题
3,如何做到消息的顺序消费?
⽣产者:保证消息按顺序消费,且消息不丢失——使⽤同步的发送,ack设置成⾮0的值。
消费者:主题只能设置⼀个分区,消费组中只能有⼀个消费者;
4,如何解决消息积压问题?
消息的消费者的消费速度远赶不上⽣产者的⽣产消息的速度,导致kafka中有⼤量的数据没有被消费;
解决方案:
使⽤多线程进行消费;
新增pod;
优化业务代码,提高执行效率;
批量消费
5,Kafka Eagle
Kafka Eagle监控系统是一款用来监控Kafka集群的工具,支持管理多个Kafka集群、管理Kafka主题(包含查看、删除、创建等)、消费者组合消费者实例监控、消息阻塞告警、Kafka集群健康状态查看等;
十,Kafka的相关遗留问题
1,创建消费者时,没有消费组怎么办?消费组需要创建吗还是自动创建?
2,针对同一个topic,在linux终端启动一个消费者,在springboot中启动一个消费者,可以同时消费消息,现象正常吗?如何解释?
十一,Kafka Rest Proxy的下载安装
Kafka Rest Proxy也就是Confluent,可以通过Restful接口而不是本机Kafka协议或客户端的情况下,生成和使用消息,而且还可以查看集群状态以及执行管理操作。
官方资料:https://docs.confluent.io/platform/current/kafka-rest/index.html
下载地址:https://packages.confluent.io/archive/7.1/?_ga=2.61317804.1206481572.1652001211-607342354.1652001211
上传到Linux进行解压
参考资料:https://blog.csdn.net/zld_555/article/details/90401510
1,修改配置文件
修改配置文件etc/kafka-rest/kafka-rest.properties
id=kafka-rest-test-server
#schema.registry.url=http://localhost:8081
zookeeper.connect=localhost:2181
bootstrap.servers=PLAINTEXT://localhost:9092
2,启动rest代理
nohup /usr/local/kafka_study/confluent-7.1.1/bin/kafka-rest-start /usr/local/kafka_study/confluent-7.1.1/etc/kafka-rest/kafka-rest.properties >> /usr/local/kafka_study/confluent_log/kafka-rest.log 2>&1 &
默认端口是8082(具体在哪配置的端口暂时没有找到,通过进程查到的8082端口)
3,开始使用ApiPost发送请求
更多请求响应示例请查看官网:API 参考|汇流平台 3.1.1 (confluent.io)
(1)查看kafka中的topic主题列表
请求信息
Get请求
http://101.201.101.206:8082/topics
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
Content-Type:application/vnd.kafka.v2+json
响应信息
[
"test",
"my-topic",
"testA"
]
(2)查询kafka中的topic主题详情
请求信息
Get请求
http://101.201.101.206:8082/topics/testA
http://101.201.101.206:8082/topics/{主题名称}
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
Content-Type:application/vnd.kafka.v2+json
响应信息
{
"name": "testA", (主题的名称)
"configs": { (每个主题的配置)
"compression.type": "producer",
"leader.replication.throttled.replicas": "",
"message.downconversion.enable": "true",
"min.insync.replicas": "1",
"segment.jitter.ms": "0",
"cleanup.policy": "delete",
"flush.ms": "9223372036854775807",
"follower.replication.throttled.replicas": "",
"segment.bytes": "1073741824",
"retention.ms": "604800000",
"flush.messages": "9223372036854775807",
"message.format.version": "3.0-IV1",
"max.compaction.lag.ms": "9223372036854775807",
"file.delete.delay.ms": "60000",
"max.message.bytes": "1048588",
"min.compaction.lag.ms": "0",
"message.timestamp.type": "CreateTime",
"preallocate": "false",
"min.cleanable.dirty.ratio": "0.5",
"index.interval.bytes": "4096",
"unclean.leader.election.enable": "false",
"retention.bytes": "-1",
"delete.retention.ms": "86400000",
"segment.ms": "604800000",
"message.timestamp.difference.max.ms": "9223372036854775807",
"segment.index.bytes": "10485760"
},
"partitions": [ (分区列表)
{
"partition": 0, (此分区的ID)
"leader": 0, (此分区的领导者的代理ID)
"replicas": [ (副本列表)
{
"broker": 0, (副本的代理ID)
"leader": true, (如果此副本是分区的领导者,则为 true)
"in_sync": true (如果此副本当前与领导者同步,则为 true)
}
]
}
]
}
(3)向指定topic发送消息(生产)
生成指向主题的消息,可以选择为消息指定键或分区。如果未提供分区,则将根据键的哈希选择一个分区。如果未提供密钥,则将以轮循机制方式为每条消息选择分区。
请求信息
Post请求
http://101.201.101.206:8082/topics/testA
http://101.201.101.206:8082/topics/{主题名称}
Accept:application/vnd.kafka.v2+json, application/vnd.kafka+json, application/json
Content-Type:application/vnd.kafka.json.v2+json
body
{
"records": [
{
"key": "somekey",
"value": {"foo": "bar"}
},
{
"value": [ "foo", "bar" ],
"partition": 1
},
{
"value": 53.5
}
]
}
响应信息
{
"offsets": [ (消息发布到的分区和偏移量的列表)
{
"partition": 0, (对消息发布到的分区,如果发布消息失败,则为 null)
"offset": 7, (消息的偏移量,如果发布消息失败,则为 null)
"error_code": null, (对此操作失败原因进行分类的错误代码,如果操作成功,则为 null)
"error": null (描述操作失败原因的错误消息,如果操作成功,则为 null)
},
{
"partition": null,
"offset": null,
"error_code": 50003,
"error": "Topic testA not present in metadata after 60000 ms."
},
{
"partition": 0,
"offset": 8,
"error_code": null,
"error": null
}
],
"key_schema_id": null, (用于生成密钥的架构的 ID,如果未使用密钥,则为 null)
"value_schema_id": null (用于生成值的架构的 ID)
}
(4)获取该topic主题的分区列表
请求信息
Get请求
http://101.201.101.206:8082/topics/testA/partitions
http://101.201.101.206:8082/topics/{主题名称}/partitions
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
Content-Type:application/vnd.kafka.v2+json
响应信息
[
{
"partition": 0, (分区ID)
"leader": 0, (此分区的领导者的代理 ID)
"replicas": [ (此分区的副本的列表)
{
"broker": 0, (副本的 Broker ID)
"leader": true, ( 如果此代理是分区的领导者,则为 true)
"in_sync": true (如果副本与领导者同步,则为 true)
}
]
}
]
(5)获取topic主题中单个分区的元数据
请求信息
Get请求
http://101.201.101.206:8082/topics/testA/partitions/0
http://101.201.101.206:8082/topics/{主题名称}/partitions/{partitionId}
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
Content-Type:application/vnd.kafka.v2+json
响应信息
{
"partition": 0, (分区ID)
"leader": 0, (此分区的领导者的代理 ID)
"replicas": [ (此分区的副本列表)
{
"broker": 0, (副本的 Broker ID)
"leader": true, (如果此代理是分区的领导者,则为 true)
"in_sync": true (如果副本与领导者同步,则为 true)
}
]
}
(6)向指定topic的指定分区发送消息(生产)
请求信息
Post请求
http://101.201.101.206:8082/topics/testA/partitions/0
http://101.201.101.206:8082/topics/{主题名称}/partitions/{分区ID}
Accept:application/vnd.kafka.v2+json, application/vnd.kafka+json, application/json
Content-Type:application/vnd.kafka.json.v2+json
body
{
"records": [
{
"key": "somekey2",
"value": {"test1": "test2"}
},
{
"value": 53.5
}
]
}
响应信息
{
"offsets": [
{
"partition": 0,
"offset": 11,
"error_code": null,
"error": null
},
{
"partition": 0,
"offset": 12,
"error_code": null,
"error": null
}
],
"key_schema_id": null,
"value_schema_id": null
(7)在消费组中创建新的消费者
请求信息
Post请求
http://101.201.101.206:8082/consumers/testGroupName
http://101.201.101.206:8082/consumers/{消费组名称}
Accept:application/vnd.kafka.v2+json, application/vnd.kafka+json, application/json
Content-Type:application/vnd.kafka.json.v2+json
body
{
"name": "myFirstConsumer",
"format": "json",
"auto.offset.reset": "latest",
"auto.commit.enable": "false"
}
响应信息
{
"instance_id": "myFirstConsumer",
"base_uri": "http://101.201.101.206:8082/consumers/testGroupName/instances/myFirstConsumer"
}
(8)查询broker列表
请求信息
Get请求
http://101.201.101.206:8082/brokers
Accept:application/vnd.kafka.v2+json, application/vnd.kafka+json, application/json
Content-Type:application/vnd.kafka.json.v2+json
响应信息
{
"brokers": [
0
]
}
(9)使用来自topic主题的消息(消费)
请求信息
Get请求
http://101.201.101.206:8082/consumers/console-consumer-9076/instances/mySecondConsumer/topics/testA
http://101.201.101.206:8082/consumers/{消费者名称}/instances/{消费者名称}/topics/{主题名称}
Accept:application/vnd.kafka.v2+json, application/vnd.kafka+json, application/json
Content-Type:application/vnd.kafka.json.v2+json
响应信息
(10)使用来自主题的一个分区的消息
请求信息
Get请求
http://101.201.101.206:8082/topic/testA/partitions/0/messages?offset=10&count=2
http://101.201.101.206:8082/topic/{主题名称}/partitions/0/messages?offset=10&count=2
Accept:application/vnd.kafka.v2+json, application/vnd.kafka+json, application/json
Content-Type:application/vnd.kafka.json.v2+json
响应信息
(11)为消费者提交偏移量
请求信息
Get请求
http://101.201.101.206:8082/consumers/default-group/instances/myFirstConsumer/offsets
http://101.201.101.206:8082/consumers/{消费者名称}/instances/{消费者名称}/offsets
Accept:application/vnd.kafka.v2+json, application/vnd.kafka+json, application/json
application/vnd.kafka.json.v2+json
响应信息
十二,Kafka Rest Proxy部署集群
TODO
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· .NET10 - 预览版1新功能体验(一)
2021-05-21 Linux_Shell脚本的艰辛之路(初级篇)