HDFS写入数据
HDFS副本摆放策略
不同的版本副本摆放策略可能并不一致,HDFS主要采用一种机架感知(rack-ware)的机制来实现摆放策略。
由于不同的机架上节点间通信要通过交换机(switches),同一机架上的通信带宽要优于不同机架。
HDFS默认采用3副本策略(参考2.9.1 & 3.2.1):
1.若操作的机器(writer)为一个DataNode,则将一个副本放在该机器上,否则任选一个DataNode;
2.将第二个副本放在与第一个不同的机架上;
3.第三个副本放置在与第二个同一机架但不同的节点上。
机架故障的可能性远小于节点故障的可能性。
如果复制因子大于3,则在确定每个机架的副本数量低于上限(基本上是(副本-1)/机架+ 2)的同时,随机确定第4个及以下副本的位置。
由于NameNode并不允许同一DataNode存放多于一个副本,因此副本数不能超过DataNode数。
HDFS写数据流程
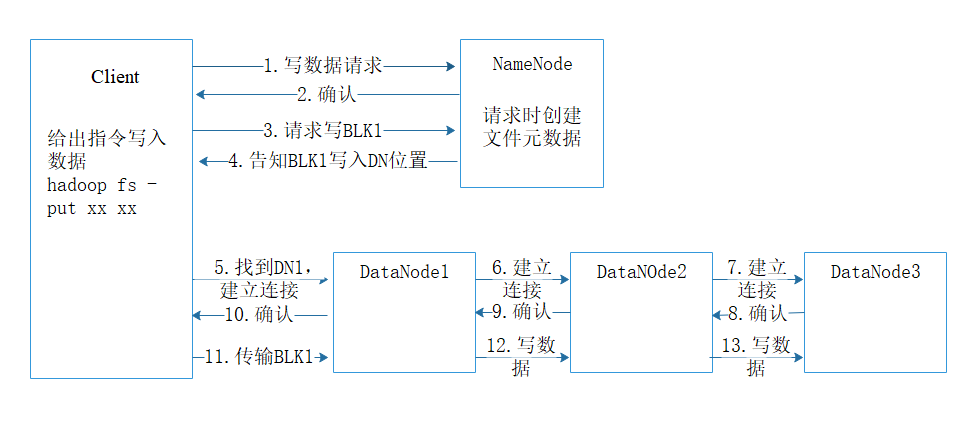
1. client发起文件上传请求,通过RPC与NameNode建立通信连接;
2. NameNode检查目标文件是否已存在等,是否可以上传;
2. client向NameNode请求写入第一个block位置;
4. NameNode根据配置文件中指定的备份数量及机架感知原理进行文件分配,返回可用的DataNode的地址告知client如:DN1,DN2,DN3;
5. client请求3台DataNode中的一台DN1上传数据(本质上是一个RPC调用,建立pipeline),DN1收到请求会继续调用DN2,然后DN2调用DN3,将整个pipeline建立完成,后逐级返回client;
6. client开始往DN1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(默认64K),DN1收到一个packet就会传给DN2,DN2传给DN3;N1每传一个packet会放入一个应答队列等待应答。
7. 数据被分割成一个个packet数据包在pipeline上依次传输,在pipeline反方向上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节点DN1将pipelineack发送给client;
8. 当一个block传输完成之后,client再次请求NameNode上传第二个block到服务器。
HDFS元数据(metadata)
元数据即数据的数据,是维护HDFS中的文件和目录所需要的信息。用于描述和组织具体的文件内容。元数据的可用性直接决定了HDFS的可用性。
形式上分为内存元数据和元数据文件两类,其中NameNode在内存中维护整个文件系统的元数据镜像,用于HDFS的管理;元数据文件则用于持久化存储。
元数据上保存信息分为以下三类:
- 文件与目录自身的属性信息,如文件名、目录名、文件大小、创建时间等;
- 文件内容存储的相关信息,如分块情况、副本个数、副本存放位置等;
- HDFS所有DataNodes的信息,用于DataNodes管理。
从来源上讲,元数据主要来源于NameNode磁盘上的元数据文件(它包括元数据镜像fsimage和元数据操作日志edits两个文件)以及各个DataNode的上报信息
参考来源:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号