
Treap
-
-
算法训练营第五章
-
-
-
名称:Treap(Tree+heap,又叫做树堆)。
-
本质:同时满足二叉搜索树和堆两种数据结构的性质。
-
一些abstract:弥补了二叉搜索树输入时因为退化成一条链导致复杂度爆炸的弱点。如果以随机的顺序构造一个二叉搜索树,则期望是平衡的,即左右高度不会差很多。如果我们提前已知所有的输入值,随机打乱插入是可以的,但很多时候我们只能知道当前的值,那就需要别的指标作为堆插入的指标,而这个指标是随机数,即每一个节点包括两个属性,一个属性是用作搜索树的,是输入的值;另一个是用作堆的,是随机出来的,用来平衡的。
-
-
一些操作:
-
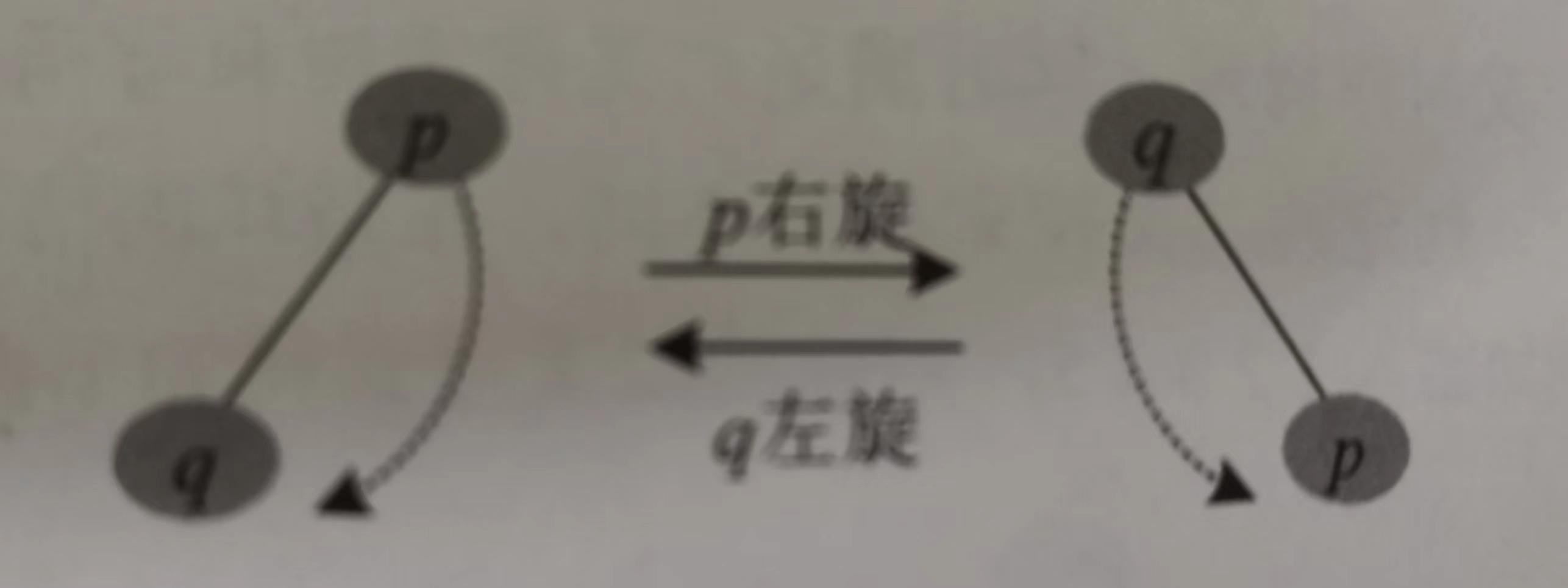
旋转:分为左旋(zag,逆时针)和右旋(zig,顺时针)。
![]()
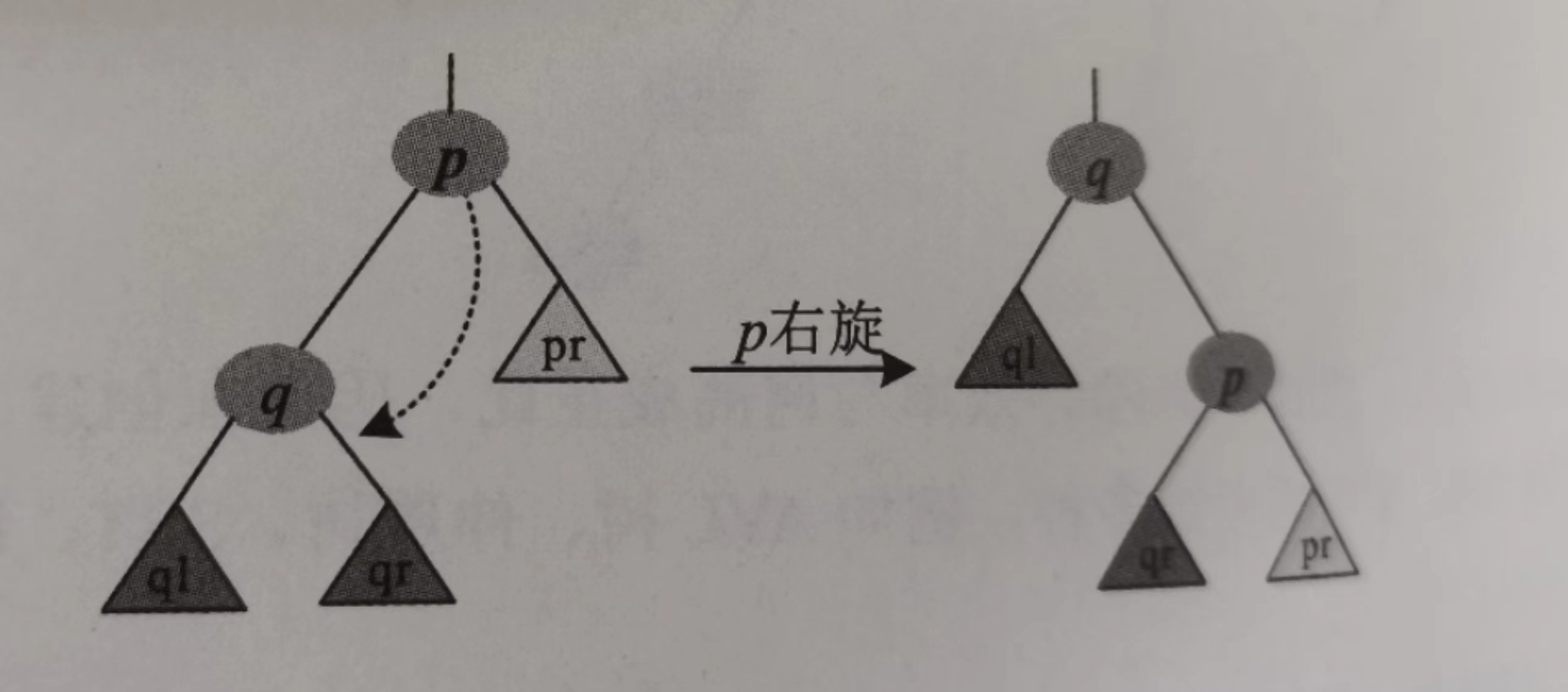
右旋如图:
![]()
看图写代码(这里看起来没有修改父亲的信息,但是注意,每次旋转都是在插入或者删除操作中,调用的时候都是Insert(tr[p].lc)这种操作,然后再旋转,而旋转之后因为最后的赋值操作是对指针操作的,所以我们其实已经自动改变了tr[p].lc的值,所以不用担心父子关系错乱的事情~)
void zig(int &p) {
int q = tr[p].lc;
tr[p].lc = tr[q].rc;
tr[q].rc = p;
tr[q].size = tr[p].size;
update(p); // 见后
p = q; // q变为根
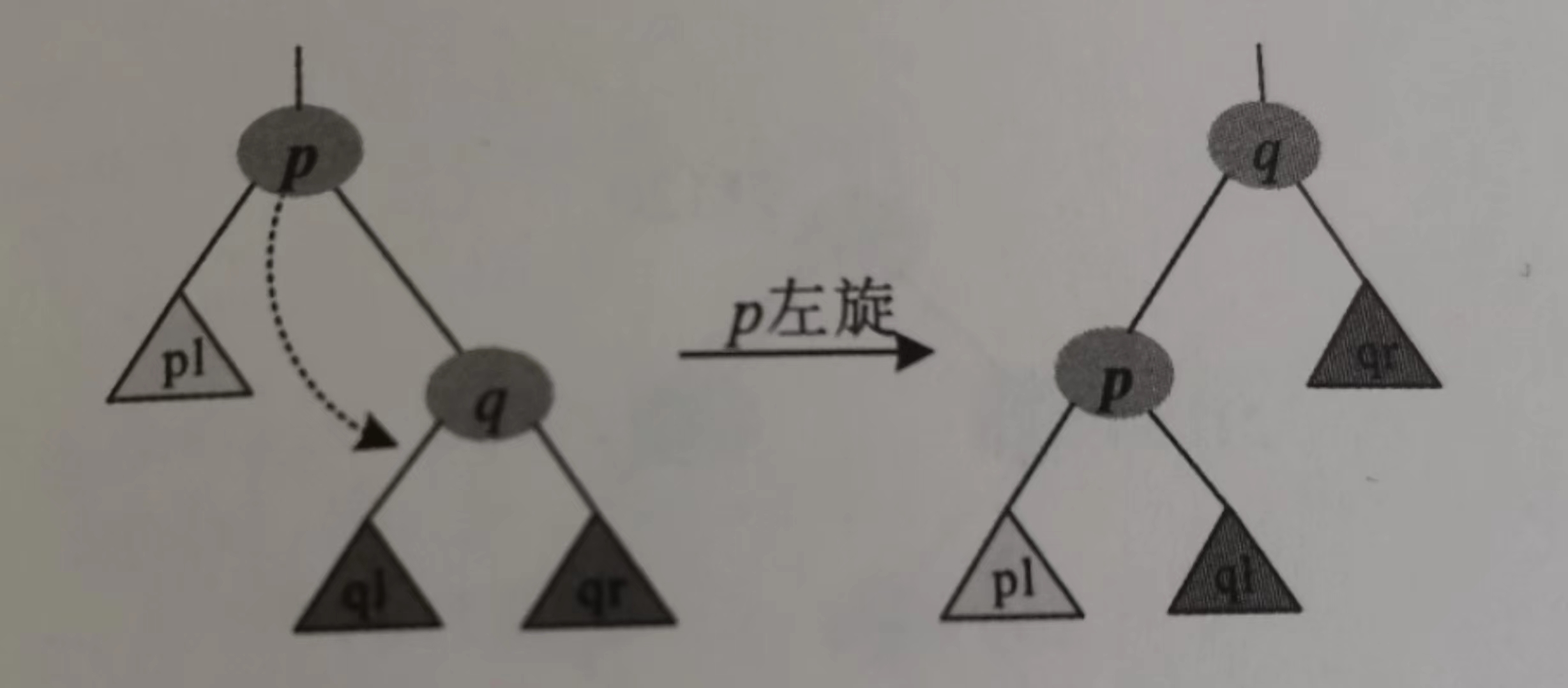
}左旋如图:
![]()
看图写代码:
void zag(int &p) {
int q = tr[p].rc;
tr[p].rc = tr[q].lc;
tr[q].lc = p;
update(p); // 见后
p = q;
} -
插入:先根据有序性找到插入的位置,然后创建新节点,插入此值,然后随机一个数,当作优先级,自底向上检查是否满足堆性质,不满足就左旋或者右旋,使其满足堆的性质。
算法步骤:
![]()
所以Treap根本不会判断左右子树的高度差才决定是否旋转,而是一开始就选择相信这个玄学优先级。
插入之后,沿着插入的路径回去看优先级大小,如果不满足堆,注意因为是沿着路径往回找,而此时矛盾的点就仅在于上面的p和q的优先级,也就是说q相当于新插入的点,递归回来到了这个位置,p是原来的点。而p的优先级显然大于除了q之外所有的点的优先级,因为只有q是新插入的点。然后我们发现旋转之后,新子树优先级满足大根堆的性质,也满足查找树的性质。
int createNode(int val) { // 创建新节点
tr[++cnt].val = val;
tr[cnt].pri = rand();
tr[cnt].lc = tr[cnt].rc = 0;
tr[cnt].count = tr[cnt].size = 1; // 有1次,子树大小为1
return cnt;
}
void update(int p) {
tr[p].size = tr[tr[p].lc].size + tr[tr[p].rc].size + tr[p].count;
}
void Insert(int &p, int val) { // 在p的子树中插入val
if (!p) { // 空树
p = createNode(val);
return;
}
tr[p].size++;
if (val == tr[p].val) {
tr[p].count++;
return;
} else if (val < tr[p].val) {
Insert(tr[p].lc, val);
if (tr[p].pri < tr[tr[p].lc].pri) { // 递归到这里,看和左儿子的优先级是否满足大根堆
zig(p); // 和左儿子的矛盾肯定要右旋
}
} else {
Insert(tr[p].rc, val);
if (tr[p].pri < tr[tr[p].rc].pri) { // 递归到这里,看和右儿子的优先级是否满足大根堆
zag(p); // 和右儿子的矛盾肯定要左旋
}
}
} -
删除:找到被删除的节点,将该节点向优先级较大的子节点旋转,递归到旋转到的位置执行删除,一直旋转到叶子,然后删除叶子的位置就行了。
![]()
我们将这个树视为很平衡的树,所以旋转的次数大概是O(logn)(层数)的。
板子:
void Delete(int &p, int val) { // 在p的子树中删除val
if (!p) return;
tr[p]--;
if (val == tr[p].val) {
if (tr[p].count > 1) {
tr[p].count = 1;
return;
}
if (!tr[p].lc || !tr[p].rc) {
p = tr[p].lc + tr[p].rc; // 至少有一个为空,直接让不为空(有一个为空)的或者空(两个全是空)的儿子代替p。
} else if (tr[tr[p].lc].pri > tr[tr[p].rc].pri) { // 左边的儿子上来,所以是右旋
zig(p);
// 右旋之后,p由于是指针,已经改变,原来的点是现在的p的右儿子
Delete(tr[p].rc);
} else {
zag(p);
// 同理
Delete(tr[p].lc);
}
}
else if (val < tr[p].val) {
// 小于显然要往左找
Delete(tr[p].lc, val);
} else {
Delete(tr[p].rc, val);
}
} -
前驱:
从树根开始找,如果当前节点值小于val,则暂存这个节点的值,说明可以尝试变得更大,尝试去右子树找答案(暂存的原因是防止右子树的值都大于val,这样值得提前准备好);否则当前的值比较大,需要在左子树里找。
板子:
int GetPre(int val) { // 找val在这棵树中的前驱
int p = root;
int res = -inf;
while(p) {
if (tr[p].val < val) {
res = tr[p].val;
p = tr[p].rc;
} else {
p = tr[p].lc;
}
}
return res;
} -
后继:
显然和前驱正好反过来
板子:
int GetNxt(int val) { // 找val在这棵树中的后继
int p = root;
int res = inf;
while(p) {
if (tr[p].val > val) {
res = tr[p].val;
p = tr[p].lc;
} else {
p = tr[p].rc;
}
}
return res;
} -
查找val在这棵树中的排名:
显然是根据val和当前节点的大小,一直往下搜。
板子:
int GetRankByVal(int p, int val) {
if (!p) return 0;
if (tr[p].val == val) { // 显然这个节点只算一个,而不是count个
return tr[tr[p].lc].size + 1;
}
else if (val < tr[p].val) {
return GetRankByVal(tr[p].lc, val);
} else {
return GetRankByVal(tr[p].rc, val) + tr[tr[p].lc].size + tr[p].count; // 这个count就得都算了,因为已经到右子树了
}
} -
拿到排名为rank的点的val
板子:
int GetValByRank(int p, int rank) {
if (!p) return 0;
if (rank > tr[p].size) return inf;
if (tr[tr[p].lc].size >= rank) { // 在左节点就被截下了
return GetValByRank(tr[p].lc, rank);
}
if (tr[tr[p].lc].size + tr[p].count >= rank) { // 在当前节点被截下
return tr[p].val;
}
return GetValByRank(tr[p].rc, rank - tr[p].count- tr[tr[p].lc].size);
}
-



 浙公网安备 33010602011771号
浙公网安备 33010602011771号