

大数据分布式微服务实战步骤
一.下载安装docker
1.windows系统中Docker目前仅有win10专业版和企业版的安装包,win7/win8/win10家庭版需要通过docker toolbox来安装。CE为免费版
docker toolbox下载地址:http://mirrors.aliyun.com/docker-toolbox/windows/docker-toolbox/
双击exe文件,按默认步骤安装,安装过程中选择插件时全部勾选即可,安装完成桌面会显示三个图表,如下图:

2.双击桌面上的Docker Quickstart Terminal图标,进入Docker客户端。

国内下载较慢,可以手动下载,放到此目录下:C:\Users\LENOVO\.docker\machine\cache\
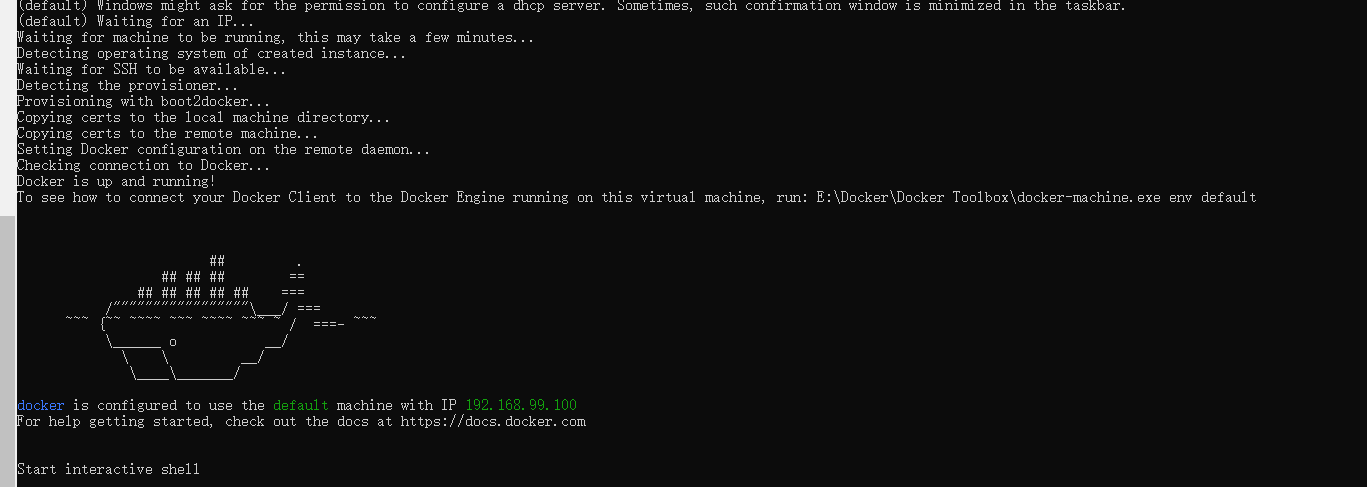
出现小鲸鱼图案表示登录成功
3.在Docker客户端中执行docker version来查看Docker版本
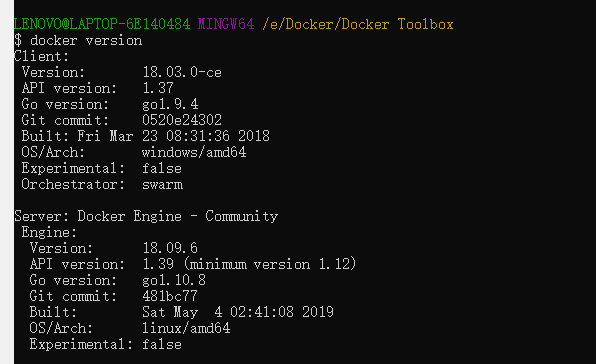
如上图所示,即安装成功
二.搭建环境
1.安装zookeeper: docker run -d -p 2181:2181 -p 2888:2888 -p 3888:3888 --name zookeeper confluent/zookeeper
如果name以被占用,执行 docker rm -f $(docker ps -a -q) 把所有已启用的container删掉
2.安装kafka: docker run -d -p 9092:9092 -e KAFKA_ADVERTISED_HOST_NAME=127.0.0.1 -e KAFKA_ADVERTISED_PORT=9092 --name kafka --link zookeeper:zookeeper confluent/kafka
- windows设置127.0.0.1,没有建立IP映射可能取不到docker的ip号,所以直接设置为固定IP(不会设置映射,待研究)

- docker run -d -p 9092:9092 -e KAFKA_ADVERTISED_HOST_NAME=192.168.99.100 -e KAFKA_ADVERTISED_PORT=9092 --name kafka2 --link zookeeper:zookeeper confluent/kafka
3.docker ps 查看docker中容器运行状态
- docker ps -a 查看所有容器(包括停止运行的容器)状态
- docker start 容器id或容器名 启动容器(先启动zookeeper再启动kafka)
- docker stop 容器id或容器名/docker kill 容器id或容器名 停止容器
- docker restart 容器id或容器名 重启容器
- docker rm 容器id或容器名 删除容器
4.使用 virtualenv进行开发环境隔离,不会和其他项目版本冲突:
- 先安装python
- 安装virtualenv:pip install virtualenv
- 创建虚拟环境:virtualenv pydir
- 激活虚拟环境:cd pydir/Scripts 执行 ./activate 成功后命令行前边会有(pydir)字样
- 取消激活:执行 ./deactivate.bat
如果使用virtualenv的话,需要进入相对应的路径,这样一来就相对麻烦,但是可以通过使用virtualwrapper来简化对虚拟环境的操作。
- 下载windows安装包:pip install virtualenvwrapper-win
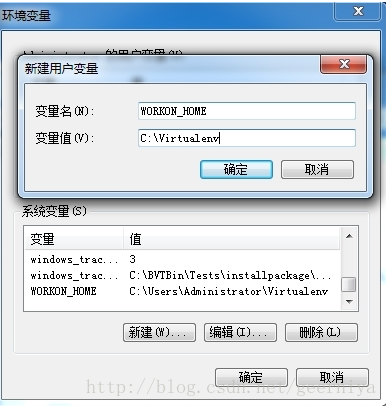
- 配置环境变量:WORKON_HOME,变量值为你虚拟环境的目录。
- 通过virtualenvwrapper新建虚拟环境:
mkvirtualenv myblog - 查看安装的所有虚拟环境:
workon - 进入虚拟环境:
workon myblog 退出虚拟环境:deactivate- 如果这个虚拟环境不打算要了,直接将这个目录删掉就可以了。
5.安装案例中用到的python依赖
- pip install schedule
- pip install kafka_python
- pip install requests
- pip freeze > requirements.txt 可以打出当前安装的依赖
- pip install -r requirements.txt 迁移环境或者别人使用同样环境时,可以同步环境,不需要一步一步安装
6.查看docker配置的命令
- docker-machine env
- docker-machine.exe ls
三.案例,用python编写脚本查询gdax比特币交易平台接口,处理返回的数据
1.检验执行脚本需要传入的参数: python dataproducer.py -h
2.执行dataproducer脚本:python dataproducer.py BTC-USD gdax 192.168.99.100:9092
3.执行dataconsumer脚本: python dataconsumer.py gdax 192.168.99.100:9092
四.使用docker快速部署
1.简单命令
- docker pull
- docker bulid
- docker run
- docker exec 登录
- docker ps
- docker kill
- docker rm 删除container
- 删除全部container: docker rm -f $(docker ps -a -q)
- docker rmr 删除image
2.编写文件Dockerfile
# Docker image containing dataproducer and dataconsumer
FROM ubuntu:latest
MAINTAINER Wang "fan.wang@bittiger.io"
RUN apt-get update
RUN apt-get install -y python python-pip wget
COPY ./dataproducer.py /
COPY ./dataconsumer.py /
COPY ./requirements.txt /
RUN pip install -r requirements.txt
CMD python dataproducer.py BTC-USD gdax kafka:9092
3.在docker中执行build命令: docker build --tag=big_data_producer . 最后有个点,表示安装在当前目录
4.查看images: docker images
删除images: docker rmi imageid -f
5.注册并登录dockerhub: docker login
6.打上传地址tag: docker tag imageid username/big_data_producer:master
7.上传image: docker push username/big_data_producer
8.下载别人的image: docker pull -a qianmao/cs502_week1
五.安装hbase
1.配置hosts: vim /etc/hosts 127.0.0.1 myhbase
2.启动hbase: docker run -d -h myhbase -p 2182:2182 -p 8080:8080 -p 8085:8085 -p 9090:9090 -p 9095:9095 -p 16000:16000 -p 16010:16010 -p 16201:16201 -p 16301:16301 --name hbase harisekhon/hbase
3.进入hbase: docker exec -it hbase /bin/bash 执行 hbase shell即可
4.创建表
- create 't', 'f1', 'f2'
- create 't1', {NAME=>'f1', VERSIONS=>5} 同一个单元格可以放5个历史版本
5.描述表
- describe 't1'
6.插入数据
- put 't1', 'row1', 'f1:c1', 'value1',1526222761
- put 't1', 'row1', 'f1:c1', 'value2',1526222762
- put 't1', 'row1', 'f1:c1', 'value3',1526222763
- put 't1', 'row1', 'f1:c1', 'value4',1526222764
- put 't1', 'row1', 'f1:c1', 'value5',1526222765
- put 't1', 'row1', 'f1:c1', 'value6',1526222766
7.查询数据
- scan 't1'
- get 't1', 'row1'
- get 't1', 'row1', 'f1:c1'
- get 't1', 'row1', {COLUMN=>'f1:c1', VERSIONS=>5} 查询历史版本的值
8.删除表中数据
- delete 't1', 'row1', 'f1:c1', 1526222763
9.删除表
- disable 't1'
- drop 't1'
六.编写datastroage脚本,保存数据到hbase
1.安装happybase: pip install happybase
2.kafka连接hbase中的zookeeper:
docker run -d -p 9092:9092 -e KAFKA_ADVERTISED_HOST_NAME=192.168.99.100 -e KAFKA_ADVERTISED_PORT=9092 --link hbase:zookeeper confluent/kafka
3.执行脚本datastroage:
python datastorage.py gdax 192.168.99.100:9092 gdax myhbase
七.spark
1.安装pyspark: pip install pyspark
2.进入spark: pyspark
退出spark: exit()
3.使用spark统计文档中单词出现频次:
- text = sc.textFile('test.txt')
- counts = text.flatMap(lambda line:line.split(" ")).map(lambda word :(word, 1)).reduceByKey(lambda a, b: a+b)
- counts.collect()
4.编写datastraming代码
5.启动zookeeper和kafka,下载spark-streaming-kafka-0-8_2.11-2.4.3.jar
6.执行脚本: spark-submit --jars spark-streaming-kafka-0-8_2.11-2.4.3.jar datastream.py gdax average_price 127.0.0.1:9092 5
八.Redis
1.安装redis: pip install redis
2.编写脚本redis_publisher.py
3.启动zookeeper, kafka, redis: docker run -d -p 6379:6379 --name redis redis:alpine
4.执行脚本: python redis_publisher.py gdax 127.0.0.1:9092 price 127.0.0.1 6379
5.登录redis: docker exec -it redis redis-cli
6.订阅channel: subscribe price
九.Node.js
1.安装node, 查看版本: node -v
2.查看版本: npm -v
3.新建node文件夹, 创建npm模板: npm init --yes
4.安装
- npm install socket.io --save 如果不创建npm模板,需要加--save来保存依赖
- npm install express
- npm install redis
- npm install jquery
- npm install minimist
- npm install bootstrap
- npm install d3@3.5.17
- npm install nvd3
5.编写index.js index.html main.js 脚本
6.启动zookeeper, kafka, redis
7.启动spark: spark-submit --jars spark-streaming-kafka-0-8_2.11-2.4.3.jar datastream.py gdax average_price 127.0.0.1:9092 5
8.执行redis_publisher.py: python redis_publisher.py gdax 127.0.0.1:9092 price 127.0.0.1 6379
9.启动node.js: node index.js --redis_host=localhost --redis_port=6379 --redis_channel=price --port=3000
10.访问浏览器: localhost:3000 查看图表

