(一) Kafka简介和搭建
1、kafka介绍
1.1 什么是消息系统
按照一定的规则接收存储信息,并且按照另外一种规则将信息进行发送的一种软件或者涉及模式
1.2 消息系统分类
1.2.1 根据消息发送模型分类
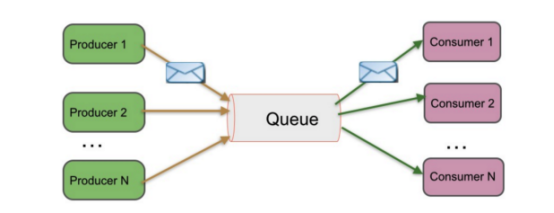
(1) Peer-to-Peer
特点:
1) 一般基于Pull或者Polling接收消息
2) 发送到队列中的消息被一个而且仅仅一个接收者所接收,即使有多个接收者在同一个队列中侦听同一消息
3) 支持异步“即发即弃”的消息传送方式,也支持同步请求/应答传送方式
异步“即发即弃”的消息传送方式:将数据放入一个地方之后,不管是否被发送,发送端立即返回
同步请求/应答传送方式:数据被发送到queeu之后不立即返回,必须等到消费者将此数据接收并且此数据从queeu中移除,之后发送方才能被确认此数据以及被处理,然后在返回发送下一条数据
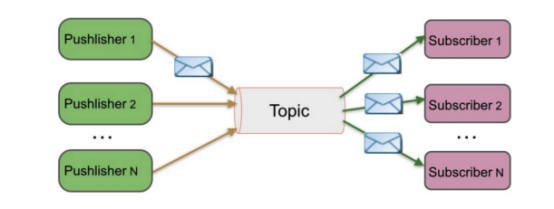
(2) 发布/订阅
特点:
1) 发布到一个主题的消息,可被多个订阅者所接收
2) 发布/订阅即可基于Push消费数据,也可基于Pull或者Polling消费数据
3) 解耦能力比P2P模型更强
两种方式的对比:
Peer-to-Peer一般为单播
发布/订阅支持多播(即不同 Consumer Pull之间的多播),也支持相同Consumer Pull之间的单播
1.3 消息系统适用场景
(1) 解耦 各个系统之间通过消息系统这个统一的接口交换数据,无须了解彼此的存在
(2) 冗余 部分消息系统具有消息持久化能力,可规避消息处理前丢失的风险
(3) 扩展 消息系统是统一的数据接口,各系统可独立扩展
(4) 峰值处理能力 消息系统可顶住峰值流量,业务系统可根据处理能力从消息系统中获取并处理对应量的请求(秒杀为例)
(5) 可恢复性 系统中部分组件失效并不会影响整个系统,它恢复后仍然可从消息系统中获取并处理数据
(6) 异步通信 在不需要立即处理请求的场景下,可以将请求放入消息系统,合适的时候再处理
1.4 常用的消息系统有哪些以及各自的特点
(1) RabbitMQ Erlang编写,支持多协议 AMQP,XMPP,SMTP,STOMP。支持负载均衡、数据持久化。同时支持Peer-to-Peer和发布/订阅模式,比较重量级一般用于比较重量级的企业开发当中
(2) Redis 基于Key-Value对的NoSQL数据库,同时支持MQ功能,可做轻量级队列服务使用。就入队操作而言,Redis对短消息(小于10KB)的性能比RabbitMQ好,长消息的性能比RabbitMQ差。
(3) ZeroMQ 轻量级,不需要单独的消息服务器或中间件,应用程序本身扮演该角色,Peer-to-Peer。它实质上是一个库,需要开发人员自己组合多种技术,使用复杂度高,由于没有消息服务器,一般不提供数据的持久化,很难做到异步发送,因为需要点对点接收,没有中间做缓存,实际上ZeroMQ是一个库,开发人员需要组合多种技术,虽然说是轻量级,但是复杂度比较高,成本高
(4) ActiveMQ JMS实现,Peer-to-Peer,支持持久化、XA事务
(5) Kafka/Jafka 高性能跨语言的分布式发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理,但是kafka不支持XA分布式事务
(6) MetaQ/RocketMQ 纯Java实现,发布/订阅消息系统,支持本地事务和XA分布式事务
1.5 什么是kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据;是由Apache软件基金会开发的一个开源流处理平台;
1.6 kafka的设计目标是什么?
(1) 高吞吐率 在廉价的商用机器上单机可支持每秒100万条消息的读写
(2) 消息持久化 所有消息均被持久化到磁盘(kafka支持多个节点之间的消息复制),无消息丢失,支持消息重放
(3) 完全分布式 Producer,Broker,Consumer均支持水平扩展
(4) 同时适应在线流处理(storm、spark streaming)和离线批处理(hadoop、hive、hdfs)
将kafka的数据导入hadoop的方式:使用flume的kafka-source取出kafka的数据,再使用flume的hdfs-sink或者hive-sink将数据导入hdfs,或者导入hive做离线批处理
2 Kafka架构简介
2.1 Kafka架构图

架构模块介绍:
ZooKeeper:可以做单机也可以做集群,做集群主要是为了做HA
中间三个kafka:为kafka的broker或kafka的server,
注:ZooKeeper和kafka以服务的形式运行,必须先启ZooKeeper再启kafka
Producer:称为生产者或发布者,可以将数据发布到kafka-server中
Consumer:可以从kafka-server中订阅数据
3 如何安装和使用Kafka
3.1 使用真实的机器部署kafka (centos_7.3)
java环境的安装: tar -xf jdk-7u80-linux-x64.tar.gz -C /usr/local/
vim /etc/profile.d/java.sh
#Java Env
export JAVA_HOME=/usr/local/jdk1.7.0_80
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
#运行环境变量生效
source /etc/profile.d/java.sh
(1) 使用kafka安装包自带的zookeeper启动kafka
tar -xf kafka_2.11-0.8.2.2.tgz -C /usr/local/
cd /usr/local/kafka_2.11-0.8.2.2/
#前台启动zk
./bin/zookeeper-server-start.sh config/zookeeper.properties

#检查zk的2181是否被监听
lsof -i :2181

#启动kafka(前台)
cd /usr/local/kafka_2.11-0.8.2.2/
./bin/kafka-server-start.sh config/server.properties

#检查kafka的端口 9092
lsof -i :9092


小结:此时再次查看2181发现kafka的borker和zookeeper之间建立起来连接
#创建一个topic
./bin/kafka-topics.sh --zookeeper 192.168.211.21:2181 --create --topic test1 --partitions 3 --replication-factor 1

#检查topic的信息
./bin/kafka-topics.sh --zookeeper 192.168.211.21:2181 --describe --topic test1

测试01:一个简单的消费者/生产者模型演示
#启动一个consumer订阅test1 topic的消息
./bin/kafka-console-consumer.sh --zookeeper 192.168.211.21:2181 --topic test1
#启动一个producer生产者
./bin/kafka-console-producer.sh --broker-list 192.168.211.21:9092 --topic test1
#在生产者的一段发送一条消息


小结:通过以上的验证,可以证明此kafka可以进行正常工作

小结:通过以上检测端口看,启动生产者和消费者时,各自启动一个端口接收数据
(2) 单独使用zookeeper启动kafka
注:清空上部的环境 rm -rf /tmp/*
tar -xf zookeeper-3.4.10.tar.gz -C /usr/local/
cd /usr/local/zookeeper-3.4.10/
#启动zk
./bin/zkServer.sh start conf/zoo_sample.cfg

#使用zk的脚本检测zk的状态
./bin/zkServer.sh status conf/zoo_sample.cfg

lsof -i :2181

#启动kafka
cd /usr/local/kafka_2.11-0.8.2.2
./bin/kafka-server-start.sh config/server.properties
#检查kafka是否启动
lsof -i :9092

#创建topic
/usr/local/kafka_2.11-0.8.2.2/bin/kafka-topics.sh --zookeeper 192.168.211.21:2181 --create --topic test1 --partitions 3 --replication-factor 1

#检查topic的信息
/usr/local/kafka_2.11-0.8.2.2/bin/kafka-topics.sh --zookeeper 192.168.211.21:2181 --describe --topic test1

测试02:一个简单的消费者/生产者模型演示
#启动一个consumer订阅test1 topic的消息
/usr/local/kafka_2.11-0.8.2.2/bin/kafka-console-consumer.sh --zookeeper 192.168.211.21:2181 --topic test1
#启动一个producer生产者
/usr/local/kafka_2.11-0.8.2.2/bin/kafka-console-producer.sh --broker-list 192.168.211.21:9092 --topic test1
#在生产者的一段发送一条消息

#检查消费者是否接收到此消息

小结:从以上测试可以看出,消费者可以正确消费kafka的消息,此kafka可以进行使用
注:在以上的环境中消费者可以启动多个,经测试之后,多个消费者可以同时订阅一个生产者的消息,各个消费者单独启动一个端口监听消息
3.2 使用docker 安装kafka (centos_7.3)
#docker的版本17.09.1-ce
使用docker安装部署kafka集群操作过程:
(1)安装Docker
#step 1: 安装必要的一些系统工具
yum install -y yum-utils device-mapper-persistent-data lvm2
#Step 2: 添加软件源信息
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#Step 3: 更新并安装 Docker-CE
yum makecache fast
yum -y install docker-ce-17.09.1.ce-1.el7.centos
#Step 4: 开启Docker服务
systemctl start docker
#Step 5: 配置Docker镜像加速
#Step 6: 重启docker
systemctl restart docker
(2)创建CentOS容器
(3)安装JDK 1.7+
(4)创建Zookeeper容器
#软件版本
zookeeper-3.4.6.tar.gz
jdk-8u152-linux-x64.tar.gz
kafka_2.11-0.8.2.2.tgz
#创建Zookeeper容器
mkdir /docker && cd /docker
#创建zookeeper镜像
docker build -t docker/zookeeper:3.4.6 -f zookeeper.Dockerfile .
#创建kafka镜像
docker build -t docker/kafka:0.8.2.2 -f kafka.Dockerfile .
#检查镜像是否生成
docker images

(5)创建Kafka broker容器并且将kafka容器链接到zk容器
注:此时可以通过容器名称直接访问zk服务,而不需要知道ip,此时可以方便部署
#启动zookeeper的容器
docker run -itd --name zookeeper -h zookeeper -p2181:2181 docker/zookeeper:3.4.6 bash
#检查容器是否启动
docker ps -a

#启动kafka的容器,同时使用主机名将zk和kafka进行链接
docker run -itd --name kafka -h kafka -p9092:9092 --link zookeeper docker/kafka:0.8.2.2 bash
#检查容器是否启动
docker ps

#检查容器的端口是否被监听
lsof -i :2181

lsof -i :9092

#进入kafka容器检查端口是否被监听
docker exec -it kafka bash

#在kafka容器内部启动2个topic
/opt/kafka/kafka_2.11-0.8.2.2/bin/kafka-topics.sh --create --topic test01 --zookeeper zookeeper:2181 --partitions 3 --replication-factor 1
/opt/kafka/kafka_2.11-0.8.2.2/bin/kafka-topics.sh --create --topic test02 --zookeeper zookeeper:2181 --partitions 3 --replication-factor 1

#检查是否创建完成
/opt/kafka/kafka_2.11-0.8.2.2/bin/kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic test01
/opt/kafka/kafka_2.11-0.8.2.2/bin/kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic test02

/opt/kafka/kafka_2.11-0.8.2.2/bin/kafka-topics.sh --list --zookeeper zookeeper:2181

测试03:在此容器的终端启动一个consumer订阅test01的消息
/opt/kafka/kafka_2.11-0.8.2.2/bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic test01
#重新开启一个终端进入kafka容器环境启动一个producer生产者
docker exec -it kafka bash
source /root/.bash_profile
/opt/kafka/kafka_2.11-0.8.2.2/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test01
#发送消息测试


小结:此时测试成功,消费者可以接收生产者的消息
测试04:在此容器的终端启动一个consumer订阅test02的消息
/opt/kafka/kafka_2.11-0.8.2.2/bin/kafka-console-consumer.sh --zookeeper zookeeper:2181 --topic test02
注:此时使用kafka-replay-log-producer.sh工具向topic发送数据
#重新开启一个终端进入kafka容器环境启动一个producer生产者将inputtopic test01的数据存放在outputtopic test02中
/opt/kafka/kafka_2.11-0.8.2.2/bin/kafka-replay-log-producer.sh --broker-list localhost:9092 --zookeeper zookeeper:2181 --inputtopic test01 --outputtopic test02
由于此时将test01的数据全部同步在了test02中,此时消费者可以消费test02的数据


报错分析:运行/opt/kafka/kafka_2.11-0.8.2.2/bin/kafka-replay-log-producer.sh --broker-list localhost:9092 --zookeeper zookeeper:2181 --inputtopic test01 --outputtopic test02 之后没有输入就会报此异常
[2018-12-30 19:41:07,804] ERROR consumer thread timing out (kafka.tools.ReplayLogProducer$ZKConsumerThread)
kafka.consumer.ConsumerTimeoutException
at kafka.consumer.ConsumerIterator.makeNext(ConsumerIterator.scala:69)
at kafka.consumer.ConsumerIterator.makeNext(ConsumerIterator.scala:33)
at kafka.utils.IteratorTemplate.maybeComputeNext(IteratorTemplate.scala:66)
at kafka.utils.IteratorTemplate.hasNext(IteratorTemplate.scala:58)
at scala.collection.Iterator$class.foreach(Iterator.scala:750)
at kafka.utils.IteratorTemplate.foreach(IteratorTemplate.scala:32)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at kafka.consumer.KafkaStream.foreach(KafkaStream.scala:25)
at kafka.tools.ReplayLogProducer$ZKConsumerThread.run(ReplayLogProducer.scala:140)
分析:kafka-replay-log-producer.sh实现的功能是将消息test01重发到test02,然而发现如果没有消息的话 过几秒中就会抛出这个异常 如果有消息就不会
