
MySQL 删除重复的行(去重留一)
参见:https://www.mysqltutorial.org/mysql-delete-duplicate-rows/
概括:在这个教程中,你将会学到多种用在 MySQL 中的删除重复行的方法。
一、准备样本数据
为了便于演示,我们用下面的脚本创建了表 contacts,并向其中插入了一些样本数据。
DROP TABLE IF EXISTS contacts;
CREATE TABLE contacts (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
);
INSERT INTO contacts (first_name,last_name,email)
VALUES ('Carine ','Schmitt','carine.schmitt@verizon.net'),
('Jean','King','jean.king@me.com'),
('Peter','Ferguson','peter.ferguson@google.com'),
('Janine ','Labrune','janine.labrune@aol.com'),
('Jonas ','Bergulfsen','jonas.bergulfsen@mac.com'),
('Janine ','Labrune','janine.labrune@aol.com'),
('Susan','Nelson','susan.nelson@comcast.net'),
('Zbyszek ','Piestrzeniewicz','zbyszek.piestrzeniewicz@att.net'),
('Roland','Keitel','roland.keitel@yahoo.com'),
('Julie','Murphy','julie.murphy@yahoo.com'),
('Kwai','Lee','kwai.lee@google.com'),
('Jean','King','jean.king@me.com'),
('Susan','Nelson','susan.nelson@comcast.net'),
('Roland','Keitel','roland.keitel@yahoo.com');
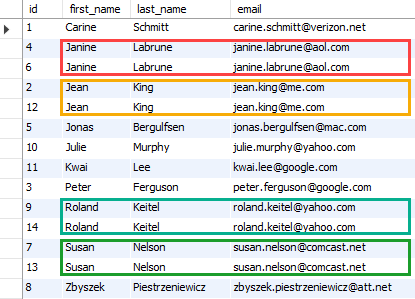
下面这个查询将返回 contacts 表的数据:
SELECT * FROM contacts
ORDER BY email;
下面的查询将返回 contacts 表中重复的 emails:
SELECT
email, COUNT(email)
FROM
contacts
GROUP BY
email
HAVING
COUNT(email) > 1;
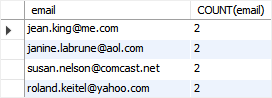
如上图所示,我们的数据中有 4 行重复的 emails(即有重复的 email 的行)。
二(A)、 使用 DELETE JOIN 语句删除重复行
MySQL 提供了 DELETE JOIN 语句,这个语句可以使你快速移除重复的行。
下面的语句删除了重复的行,并且保留了(重复行中)最大的 id。
DELETE t1 FROM contacts t1
INNER JOIN contacts t2
WHERE
t1.id < t2.id AND
t1.email = t2.email;
这个查询引用了两次 contacts 表,因此,它使用表的别名 t1 和 t2。
上面语句的输出是:
Query OK, 4 rows affected (0.10 sec)
这表明 4 行数据已经被删除。你可以执行下面这个查询再次查找重复的行来验证删除的效果:
SELECT
email,
COUNT(email)
FROM
contacts
GROUP BY
email
HAVING
COUNT(email) > 1;
上面这个查询的返回结果是一个空集,这意味着重复的行已经被删除了。
让我们从 contact 表中验证一下数据:
SELECT * FROM contacts;
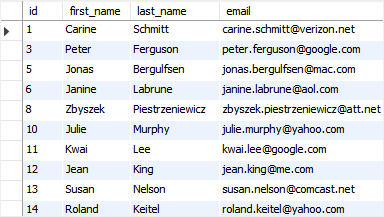
可以发现,id 为 2,4,7,9 的行被删除了。
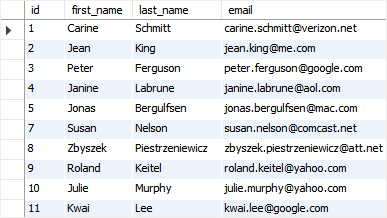
万一你想删除重复的行,同时,你想保留最小的 id,你可以使用下面的语句:
DELETE c1 FROM contacts c1
INNER JOIN contacts c2
WHERE
c1.id > c2.id AND
c1.email = c2.email;
注意,你可以重新执行脚本来再次建立刚刚的表,然后测试这个查询。下面的输出展示了删除重复的行之后的 contacts 表的数据。
二(B)、使用一个中间表来删除重复的行
下面展示用一个中间表来删除重复行的步骤:
- 创建一个和你想删除的重复行的表具有相同结构的新表。
- 从原表中向中间表中插入所有不同的(不重复)数据。
- 删除原表,并将中间表重命名为原表的表名。
下面的查询阐释了这些步骤:
Step 1. 创建一个和你想要删除重复行的表具有相同结构的新表:
CREATE TABLE source_copy LIKE source;
Step 2. 从原表中向中间表中插入所有不同的(不重复)数据:
INSERT INTO source_copy
SELECT * FROM source
GROUP BY col; -- 有重复值的列
Step 3. 删除原表,并将中间表重命名为原表的表名:
DROP TABLE source;
ALTER TABLE source_copy RENAME TO source;
例如,下面的语句就是从 contacts 表中删除了具有重复 emails 的行:
-- step 1
CREATE TABLE contacts_temp
LIKE contacts;
-- step 2
INSERT INTO contacts_temp
SELECT *
FROM contacts
GROUP BY email;
-- step 3
DROP TABLE contacts;
ALTER TABLE contacts_temp
RENAME TO contacts;
二(C)、使用 ROW_NUMBER() 函数删除重复的行
注意,ROW_NUMBER() 函数是从 MySQL 8.02 版本开始得到支持,所以在你使用这个函数之前,你应该检查你的 MySQL 版本。
下面的语句使用了 ROW_NUMBER() 函数给每一行分配了一个整数序列值。如果 email 是重复的,那么,行数(即下表中的 row_num)将会比 1 大。
SELECT
id,
email,
ROW_NUMBER() OVER (
PARTITION BY email
ORDER BY email
) AS row_num
FROM contacts;
下面的语句返回重复行的 id 集合:
SELECT
id
FROM (
SELECT
id,
ROW_NUMBER() OVER (
PARTITION BY email
ORDER BY email) AS row_num
FROM
contacts
) t
WHERE
row_num > 1;
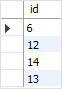
然后,你只要使用在 WHERE 分句中带有一个子查询的 DELETE 语句从 contacts 表中删除重复的行即可:
DELETE FROM contacts
WHERE
id IN (
SELECT
id
FROM (
SELECT
id,
ROW_NUMBER() OVER (
PARTITION BY email
ORDER BY email) AS row_num
FROM
contacts
) t
WHERE row_num > 1
);
MySQL 给出了以下的执行后的信息:
4 row(s) affected

 浙公网安备 33010602011771号
浙公网安备 33010602011771号