【读书笔记与思考】Andrew 机器学习课程笔记
Andrew 机器学习课程笔记
完成 Andrew 的课程结束至今已有一段时间,课程介绍深入浅出,很好的解释了模型的基本原理以及应用。在我看来这是个很好的入门视频,他老人家现在又出了一门 deep learning 的教程,虽然介绍的内容很浅,毕竟针对大部分初学者。不管学习到什么程度,能将课程跟一遍,或多或少会对知识体系的全貌有一个大致的理解。如果有时间的话,强烈建议跟完课程的同时完成各项作业。但值得注意的是,机器学习除了需要适当的数理基础之外,还是一门实践科学,只有通过不断的深入积累才能有更好的成长。
本文仅是对自身学习的一个 log,总结的顺序有所调整,其中也加入了自己的一些总结与思考。本想在此基础上进行更多的扩展,但越想发现内容越多,似乎不是一篇博文能容纳的,这或许要在以后分章节深入。既然是日记,还是点到为止就好,要不然就没办法写完了。
笔记链接,每个小结前面都有一个总结概述。
目录
Supervised Learning
Unsupervised Learning
Application
Introduction
机器学习的定义
机器学习的定义,我觉得还是 Tom Mitchell 的表述很到位:
"Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance P, if its performance on T, as measured by P, improves with experience E".
以垃圾邮件分类为例:
T : 基于邮件的内容,将邮件分为垃圾邮件(1)和 正常邮件(0)。这是一个典型的二分类问题。
E : 历史数据,每个实例可以是 [text, label] 这样的元组,而 label = 1 or 0。
P : 被分正确的实例占总实例的比例,accuracy
也就是说,在抽象一个实际问题时,我们要弄明白任务(T)是什么,要调研好我们是否有足够的 Experience 来供模型进行学习,最后还要选择好的 matrics 来评价你当前模型的好坏。
其实这和我们人类学习的过程是类似的,我们总以某种目的去完成某个学习任务(T),此过程中我们可以通过一些历史的经验(E,看书或从老师那里获取经验性的知识),对于纷繁复杂的信息我们需要有一定的判别能力(P)去度量我们当前的学习情况。
课程的主要内容
- 监督学习(supervised learning)(有 label,ground truth)
- 分类(classification):label 是离散的 (垃圾邮件分类)
- 回归(regression):label 是连续的 (房价预测)
- 非监督学习(unsupervised learning)
- 聚类(clustering)
- 降维(dimensionality reduction)
- 异常检测(anomaly detection)
- 其他话题:推荐系统,大规模机器学习任务的并行
- 一些关于模型选择或参数选择的经验介绍
课程最开始以线性回归解决房价预测问题为切入点,介绍了常用的监督学习方法(linear regression,logistic regression,svm,neural network),中间还穿插了优化方法(主要是 gradient decent)以及模型选择和调优的一些经验性建议(欠拟合/过拟合问题的发现和解决,模型选择,参数选择技巧等)。接下来过渡到非监督学习,每个话题列举了一个常用的算法,聚类(k-means),降维(PCA),异常检测(density estimation)。在介绍各算法过程中,不仅介绍了基本原理,还适当介绍了算法的优缺点,适用场景,关键参数选择等。
最后基于业界很火的商业介绍了几个方向上的应用,比如推荐系统。以 OCR 为例探讨了如何运用机器学习解决实际问题。还讨论了大规模数据中的优化问题(map-reduce)。
supervised learning
02. linear regression
核心思想:每个实例可以看成<features, y> 这样的一个向量,简单的线性回归就是直接构建多个 feature 和目标 y 的线性关系,权重直接表示了 feature 的重要性,此外还有一个残差项/常数项 bias。基于此升级得到多元回归,这里主要是对 features 进行处理,对已有的 feature 进行更复杂的组合。
典型的例子:房价预测
线性回归:y = w1*x1 + ... + wm*xm + bias
多元回归:y = w1*x1 + w2*x2 + w3*x1*x2 (除了单个变量的系数之外,还有变量间的相互作用,实际上变量间的相互作用可以看作是新生成的特征)
loss function: 误差平方和
求解方法:梯度下降,最小二乘法
python regression tutorial 很好的介绍了常用的线性回归模型
03. Logistic regression
LR 是广义线性模型,用以解决二分类问题。目标是在空间中找到一个决策平面将两个不同类别的实例分开,其核心是在决策边界上通过 sigmoid 函数将 [-inf,inf] 的区间映射到 [0,1] 范围内,可以看作直接对后验概率的估计,这一性质在很多场景中很有用,比如在点击率预估的应用中,LR 的输出可以直接表达为点击概率。


LR 的 loss function 可以通过二项分布结合最大似然推倒而得,同时也是交叉熵的特例。在实际优化过程中往往还会加上 L1 或 L2 正则。

LR 解决的是二分类问题,通常采用 one-vs-all 的方式来解决多分类问题。对于 k 个类,我们需要 k 个分类器,每个分类器的对应一个类的识别,预测时将 k 个输出中最大值对应的类标作为预测结果。

-
优化方法:GD,或高级的优化算法
-
优点:广义线性模型,权重直接反应 feature 的重要性,可解释性好;输出为概率值,在很多应用场景很有用;sigmoid 函数处处可导,拥有很好的数学性质;容易实现,容易并行,效率高。
-
缺点:广义线性模型,需要很多特征工程,适用于大规模离散数据,因为离散后的高维空间中更容易找到线性可分的分类面。
-
很受工业界欢迎。
-
一些典型的应用:
- Email: Spam / Not Spam
- Online Transactions : Fraudulent (Yes/No)
- Tumor : Malignant / Benign
- 点击率预估: click or not
04. Neural Network
神经网络是一种类人脑的设计,在人脑中神经元之间通过突触进行连接。当人的某个部位受到刺激之后,就会沿着这样连接起来的神经元进行信号的传递,一个神经元接收来自多个神经元的信号作为输入,只有当这些信号的累计值超过某一个阈值时,当前的神经元才会兴奋。


由此可得到神经网络中的关键组件:
- neurons(神经元)
- activation (激活函数)
- bias / threshold (控制是否兴奋的阈值)
- layer
- input layer (输入层)
- hidden layer (隐藏层,可以有多层,神经元带有 activation function)
- out put layer :全连接层,对于多分类问题可以使用 one-hot-vector 编码,即对于 k 个类,可以使用 k 个值的向量,预测的类对应的元素为 1, 其他位为 0。还可以使用 one-vs-all。


神经网络在 80 到 90 年代早期得到广泛的应用,之后由于深层网络优化困难而一度沉寂。后来在反向传播这样的有效优化算法出来后又再次复苏。神经网络的层层连接,相当于函数的层层嵌套,整合起来就是一个复杂的非线性函数,具有很强大的学习能力,从理论上来说任何一个问题都可以被一个或多个这样的函数逼近。值得注意的是,学习能力强大的同时导致了容易过拟合的问题。
简单的例子:
- AND, OR 函数可以通过一层神经网络进行构造 (相当于感知机)
- XOR 需要两层
神经网络的训练:
- 随机初始值(最好多尝试几组)
- 执行前向传播(forward propagation),计算预测值
- 计算预测值和 ground truth 的差异得到误差
- 执行反向传播(backpropagation),将错误反向传播,达到减小误差的目的
- 注意:
- 检查 GD 的正确性,可以使用数值解来校验近似解(验证以后注意将数值解部分的代码注释掉)
- 使用 GD 或高级的优化方法通过反向传播优化模型
05. SVM
SVM 有一套完整的严格的理论支持,在实际中得到广泛应用,经常和Logistic regression 一起出现。这里只做一个直观性的总结。SVM 的基本型是解决如下图的线性可分问题,即找到一个分类平面使得两个类别之间的 margin 最大化,margin 是支持向量间的距离,即结构风险最小化。其中支持向量(support vector)是那些落在距离决策平面距离为 +/-1 的面上的点。


核技巧是 SVM 的一个关键技术。引入核技巧解决非线性可分问题,即将线性不可分问题的样本空间映射到映射到高维空间中,在高维空间中更容易找到线性可分的分类面。
在应用方面。线性可分的情况下使用 linear svm。非线性可分的情况下,一般使用 Gaussian 核,还有其他的核函数,String kernel, chi-square kernel, histogram intersection kernel 可以尝试。


训练过程中涉及的重要参数(通常使用 cross-validation 来进行参数选择):
- C : 惩罚因子,是我们常说的 regularization parameter 的倒数 (1/lamda),其值越大越容易过拟合
- 核函数和核参数的选择
优化算法:SMO(Sequential Minimal Optimization)
对噪声敏感,如何解决过拟合问题?
- noise: 加入松弛变量,在一定程度上容许错误的存在
- 使用 cross-validation 选择合适的参数
标准型的 SVM 只针对二分类问题,解决多分类问题需要进一步调整,经常用的是 on-vs-all 的建模方式:
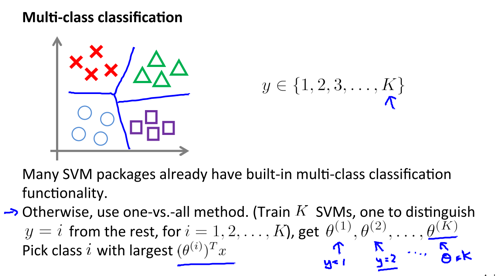

对于回归问题可以使用 SVR。
06. some advice
对模型进行诊断和fine tune 往往是个耗时的过程,但却是一个必须和有效的过程。
梯度下降(GD)优化算法
-
gradient descendent
- 梯度的反方向是函数减小最大的方向
- loss function 对各个参数求偏导得到梯度
- 参数初始化
- 参数沿着梯度的反方向,以某一个学习率迭代更新直到收敛
-
注意:
- 变量的规范化,加快 GD
- 注意 loss 随着迭代的次数不增(plot 图检查训练过程是否正确)
- 可调参数有:初始值,学习率,迭代更新的方式(batch, minibatch, stochastic)
- 其他高级的优化方法有:BFGS, L-BFGS, Conjugate
-
GD:
- batch GD : 每次迭代都使用完所有数据
- 耗时
- stochastic GD (SGD) : 每次迭代只需要一个实例
- 高效
- 崎岖的往最优值逼近,可能存在收敛问题,可以随着时间逐渐减小学习率以保证最后收敛
- mini-batch GD : 介于 batch GD 和 SGD 之间,每次使用 b 个实例构成的小数据集
- balance choice
- checking for convergence
- 作图,error vs number of iteration,误差随着迭代次数是不增函数
- Note: for SGD, error should be a mean error during a time section

- batch GD : 每次迭代都使用完所有数据

欠拟合(underfitting) vs 过拟合(overffiting)
机器学习实际上是求解 NP 问题近似解的过程,我们总在以某种方式去逼近最优解。这个逼近的过程会产生两个问题:underfitting(欠拟合) 和 overfitting(过拟合)。欠拟合是指模型的学习能力太弱,无法很好的拟合历史数据;而过拟合刚好相反,反应了模型学习能力太强,及时是历史数据中的微小变化(噪声)都能被模型捕捉到,以至于模型对未知的样例预测能力很弱,即泛化能力差。
欠拟合的问题比较好解决,我们可以通过提高模型的复杂度和增加特征等方式来提高模型的学习能力。而过拟合的问题比较麻烦,可以说,我们只能尽可能降低过拟合的风险,却不能绝对的避免过拟合。
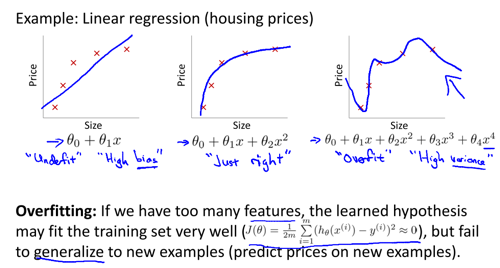

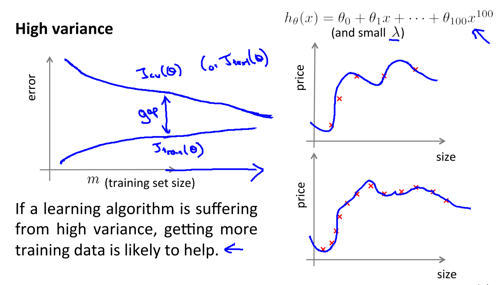
欠拟合和过拟合的现象 (detection & analysis)
最小化泛化误差是我们最终的目的,然而真实的泛化误差无法被测量到,这个时候我们通常将数据集分成 trainning set, validation set, testing set。trainning set 用于训练模型,validation set 用于模型选择,而 testing set 用于测试最终模型的泛化能力。


基于这样的数据划分,我们可以通过 bias-variance analysis 来发现欠拟合和过拟合问题,进而对模型进行调整。
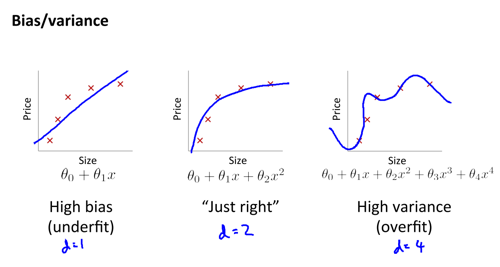



除此之外,我们还可以用学习曲线来发现问题。判断“增加数据是否有效???”





正则化(regularization)

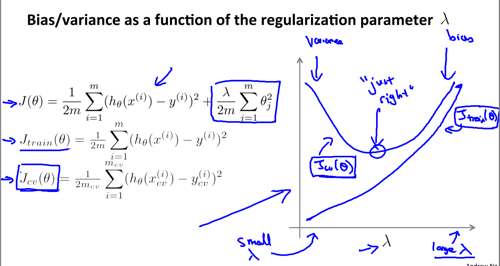


- 任何模型的 loss function 都可以分为两个部分:
- 误差项: 衡量模型的 accuracy,即对历史数据的拟合能力
- 正则项: 对模型的复杂程度的惩罚项,最常用的是 L1 和 L2 正则
- L2 : 又称 ridge regression, 偏向于保留所有的 feature,但每个 feature 权重较小,即大家都对目标 y 有贡献,即使关系不大也可以有很小的贡献。
- L1 : 又称 Lasso, 偏向于较少的 feature,将不太相关即全中很小的 feature 去掉,可以进行 sparcity, feature selection.
- regularization parameter: (can be selected by cross validation)
- too large: underfitting
- too small: cann't address the overfitting problem
如何解决欠拟合问题
欠拟合的根本问题是模型的学习能力不足,这时一味的增加数据是不可行的,应该从提高模型学习能力的角度考虑。两个方向,提高模型的复杂度或增加特征。
- 尝试增加特征:
- 发现新的特征
- 在原来的特征上构建新的特征(polynomial feature)
- 尝试减小 regularization parameter (正则项是对模型复杂程度的惩罚,减小对应的阐述即提高模型的复杂程度,在一定程度上可以认为模型的复杂程度和模型的学习能力是成正比的)
如何解决过拟合问题
过拟合的核心问题在于模型太过于复杂,拟合能力(学习能力)太强,以至于即使数据有轻微的扰动都能被模型捕捉到,导致模型对未出现过的实例具有很差的泛化能力。思考的两个方向:减少特征和降低模型的复杂程度。
- 减小特征:
- 手动选择特征
- 通过模型选择算法(比如 L1 稀疏)
- 加入正则项:
- 增大 regularization parameter
- L2 保存所有的 feature,但是每个 feature 的系数都很小,当存在很多 feature 并且每个 feature 对目标变量都有或多或少的贡献时。
- 获取更多的数据(往往最有用)
对于神经网络

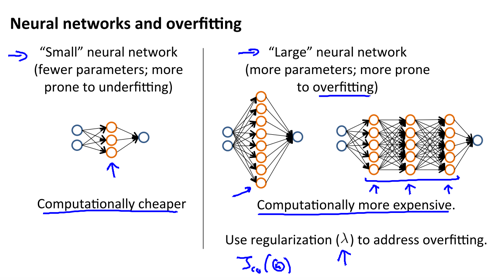
通常使用 dropout 来防止过拟合,增加数据量也是一个方向。
unsupervised learning
07. Clustering
核心思想:最大化簇间距离,最小化簇内距离,将无类标数据聚成相似的几个簇。


- 聚类的 cost funtion 是非凸的,对初始值和 k 值的选择敏感
- 如何选择参数:
- 尝试多个不同的初始值进行训练
- K 的选择:
- 尝试不同的K, 并作图,K vs cost function,
- 一般 kmean 常用做预处理阶段,可以根据下游模型的结果来调整 K 的选择。
- 核心思想与 EM 算法类似
- E: 估计新的中心 (hidden variable, random initialization in the beginning)
- M: maximization, <=> minimize Objective function
08. Dimensionality Reduction
PCA 是一种常用的降纬方法,在更低维度的空间中找到原数据的映射,并尽可能保留原有数据的信息。一般可作为模型前的特征选择过程使用。

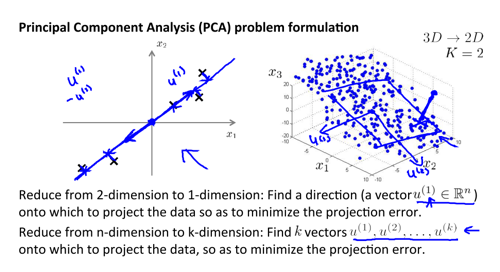
- 动机:
- 压缩:减少存储数据开销的内存和磁盘
- 可视化
- 对 PCA 不好的应用:
- 用于解决过拟合
- 可能有用,但!!!建议使用正则化来解决过拟合问题
- 算法描述:
- PCA:
- [U,S,V] = svd(Sigma), U_[n*n]
- U_reduce = U(1,2..,k), 1<=k<=n, n feature, z = U_reduce' * x , z_[k*1]
- Reconstruction: x = U_reduce * z
- PCA:
- 注意事项和建议:
- k 的选择:决定了有多少信息能够得到保留
- 对于 supervised learning,PCA 不仅仅用于 training set,还应该用于 validating set 和 testing set
- 在使用 PCA 之前,最好在全集上进行训练,方便评估 PCA 所起到的作用
- scale feature,使得各值之间都是可比的
- PCA != Linear regression
09. Anomaly Detection
核心思想:每个数据集在正常情况下都应该遵循某一未知的分布,而异常检测就是检测哪些点违背了数据集隐含的分布。我们可以使用单个高斯分布或联合高斯分布对数据进行拟合,即估计数据集的隐含分布。当某个数集明显偏离给定的阈值时,可认为异常发生。
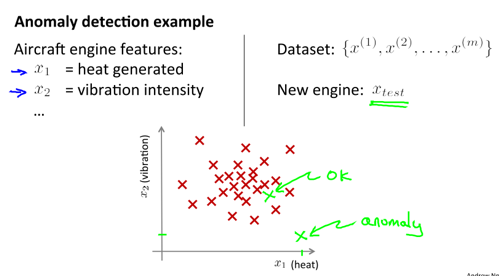





- 密度估计(density estimation)
- 高斯分布(guassian distribution)
- one variable
- multi-variable
- 参数估计(parameter estimation)
- mean
- standard
- 预测(prediction)
- calculate density for example x, p(x)
- p(x) large for normal examples
- p(x) small for anomalous examples
- 评估(evaluation)
- charateristic:
- very small number of postive examples
- larege number of negative
- many different 'types' of anomalies
- future anomalies may look nothing like any anomalous examples we've seen so far
- true positive, false positive, true negative, false negative
- precision / recall
- f-score
- charateristic:
- 特征选择(choosing feature)
- non-guassian feature, (log transformation)
- error analysis
- 应用(application):
- fraud detection
- manufacturing monitor
application
10. Recommender Systems
推荐系统里最常用的协同过滤算法核心思想是维护一个二维矩阵 R,行表示用户 user,列表示物品 item,而每个元素 R[i,j] 表示 user j 到 item i 的评分。


基于内容的推荐
- feature 是一些基于 item 的特性
- x[i],表示 item i 的分值向量,即在每个 feature 上的得分 (已知的)
- theta[j],表示用户 j 对每个 feature 的关注程度 (从打分数据中学习而得)
- 那么用户 j 对 item i 的打分 rating[i,j] = x[i] .* theta[j]




协同过滤:








基于 CF 的相似性度量:
- user-based similarity:column[i] 和 column[j] 之间的相似性
- item-based similarity:row[i] 和 row[j] 之间的相似性
实现细节:
- 缺失值的填充
- 归一化处理
11. Large Scale Machine Learning
数据的作用:
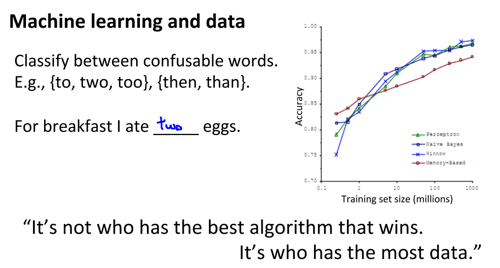

往往比的不是算法,而是数据。当数据量足够时,不同算法的效果趋于一致。
online learning
- shipping service website
- product search
- click throgh rate
- choosing special offers to show user
- customized selection of news articles
- product recommendation
large scale machine learning
- mini-bach
- map: divide training data and learn each part on parallel computer
- reduce: combine all error for model update


多机器 or 多线程




12. Application photo OCR
以 OCR 的应用为例,介绍如何使用机器学习解决实际问题。
- 建模并建立一个 pipline
- for instance OCR: text detection -> character segmentation -> charater classification
- segmentation : sliding window
- win size
- classfication problem for each segmentation
- get more data
- artifical
- sythesis
- Note:
- make sure you have a low bias classification
- "how much work would it be to get 10x as much data as we currently have?"
- artificial data synthesis
- collect / label it yourself
- "crowd source"
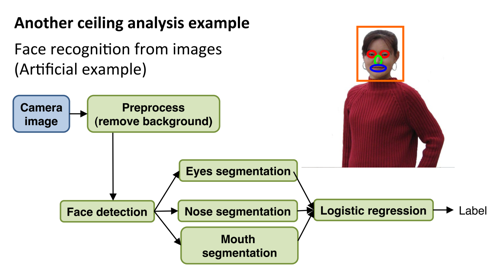
- ceiling analysis
pipline


sliding window
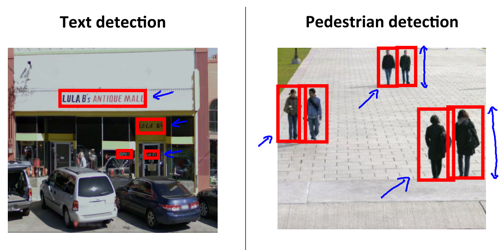

get more data
通常是为了降低过拟合的风险,如果通过对原有数据进行变换来增加数据?比如图片中的变形。


ceiling analysis
往往一个大问题由几个模块构成,如何找出限制整体优化目标的局部模块很关键。