循环语句 & 字符编码
计算机语言进化史
计算机语言经过这些年的发展壮大,从基础的二级制到现在的多种高级语言,使编程变得简单而快捷
- 机器语言
- 汇编语言
- 高级语言
机器语言:
- 优点:运行速度快
- 缺点:代码复杂度高,直观性差,开发效率低
机器语言就是所谓的 “ 二进制 ”,二进制是计算机最底层的语言,因此它的运行速度是最快的。但是由于机器语言本身的限制,它的开发效率较低,而且编写出的代码复杂度最高。现在除了计算机厂家的工程师外,没有人去学机器语言。
汇编语言:
- 优点:运行速度快
- 缺点:代码复杂度高,开发效率低
汇编语言的实质和机器语言是相同的,,多事直接对硬件进行操作,只不过指令采用了英文所写的标识符,看起来更容易理解和记忆。
汇编语言也需编程者将每一步具体的操作用命令的形式写出来,汇编语言每一句指令只能对应实际操作的一个很细微的动作,例如:移动,自增
因此汇编源程序一般比较复杂,容易出错。但是汇编语言的优点也是显而易见的,用汇编语言所完成的操作不是一般高级语言能够实现的,而且源程序经汇编语言生成的可执行文件不见比较小,而且执行速度也很快。
高级语言:
- 优点:运行速度较慢
- 缺点:代码复杂低,开发效率高
高级语言相比于汇编语言,不但能将指令简化并且去除了具体操作相关的细节,如:使用堆栈。寄存器等。同时对编程者专业知识要求较低
高级语言运行速度较慢主要相对汇编语言而言,其实速度相差不大。高级语言在代码编写上有很大的提高,相比于汇编语言几十行写的的指令,高级语言有的只需一条就OK了
高级语言现在市面上有很多种高级语言,如C\C++、JAVA、PHP、Python、GO、C#等等
分类:编译型 & 解释型
高级语言所编制的程序不能直接被计算机识别,必须经过转换才能被执行
根据转换方式 高级语言又分为“ 编译型 “和 ” 解释型 ”
- 编译型语言:不能跨平台
高级语言所编制的程序不能直接被计算机识别,必须经过转换才能被执行。因此其目标程序可以脱离其语言环境独立执行,使用比较方便灵活。但应用程序一旦需要修改,就必须修改源代码,再重新生成目标文件(*obj。也就是OBJ文件)才能执行。只有目标文件没有源代码修改很不方便
编译后的程序运行是不需要重新翻译,直接使用编译的结果就行了。程序执行 效率高,依赖编译器,跨平台性差,如C、C++、Dellphi、Go等

- 解释型语言:可以跨平台
执行方式类似于 ” 同声翻译 “,应用程序源代码一边由相应语言的解释器 “ 翻译 ”成目标代码(机器语言),一边执行,因此效率较低,而且不能生成可独立的可执行文件。应用程序不能脱离其解释器,但这种方式比较灵活,可以动态的调整,修改应用程序。如进JAVA、PHP、Python、Ruby等

Python 交互器作用:代码调试
运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算
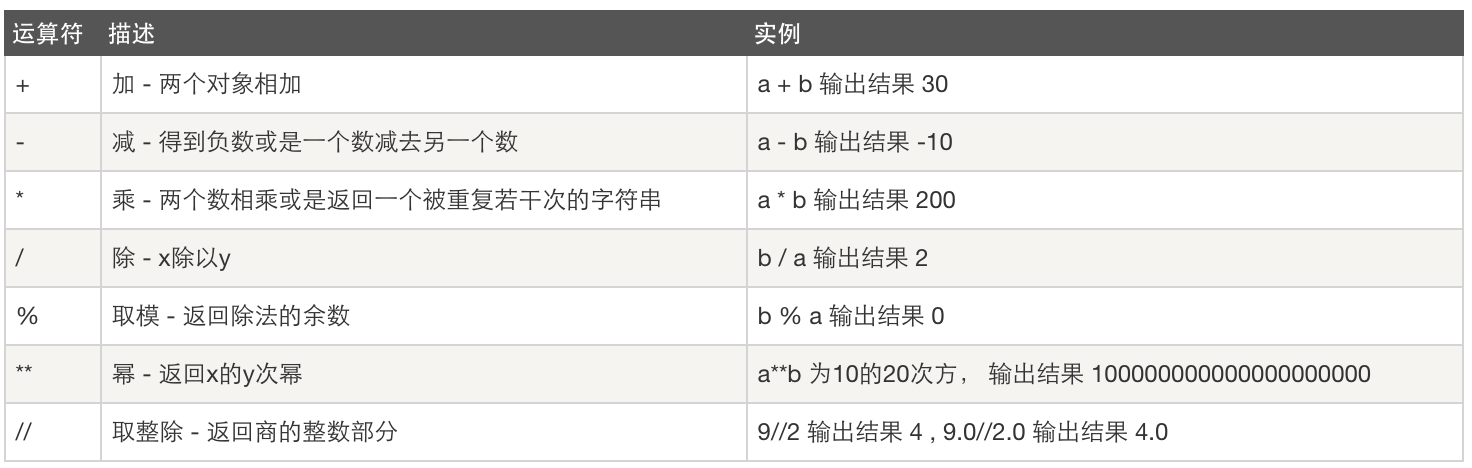
算数运算
以下假设变量:a=10,b=20
比较运算
以下假设变量:a=10,b=20

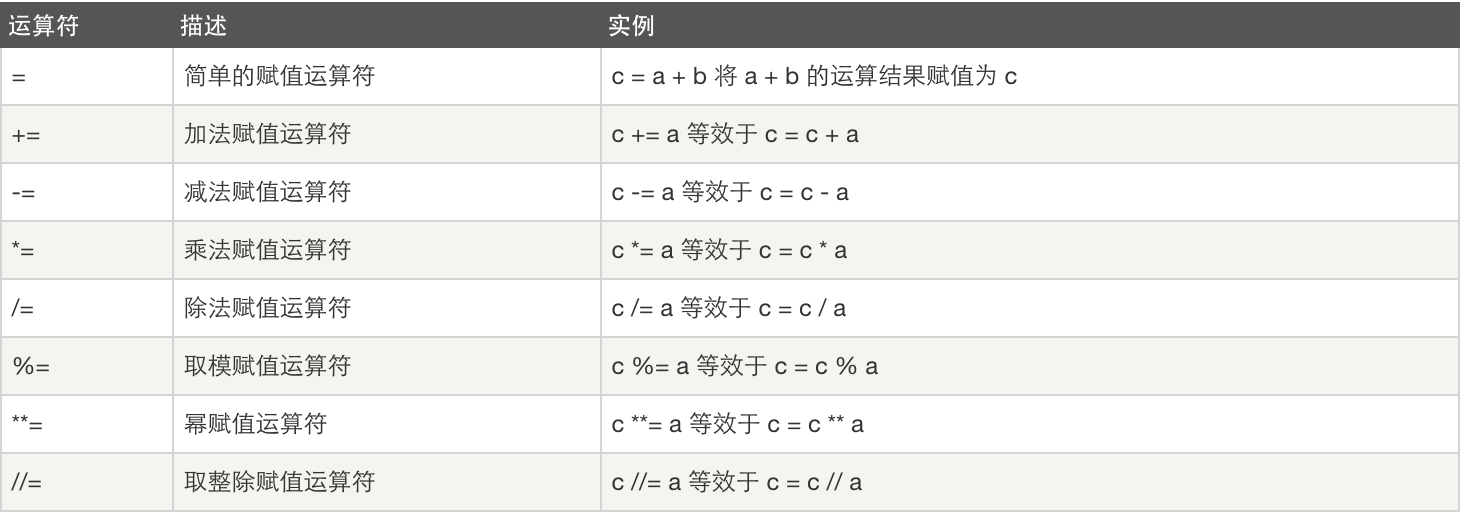
赋值运算
以下假设变量:a=10,b=20
逻辑运算

if...else..条件语句
当满足 if 条件时 ,才会执行的后续的代码,否则会执行 else 语句中的代码
1 a= 2
2 b= 6
3 if a>b:
4 print('a is bigger than b')
5
6 else:
7 print('a is smaller than b')
8
9 输出
10 a is smaller than b
由于a小于b,if 条件不满足,所以执行 else 语句的代码
while 循环语句
如果我们将一段代码执行很多遍时,为了方便快捷,应使用 while 循环语句
1 username = input('请输入你的名字')
2 print('欢迎 %s 来到猜年龄游戏!'% username)
3 age = 18
4 i = 0
5 while i <3:
6
7 guess = int(input('请输入你猜的数字:'))
8
9 if guess > age:
10 print('It`s too bigger! please try again')
11
12 elif guess <age:
13
14 print('It`s too smaller! please try again')
15
16 elif guess == age:
17 print('恭喜你,答对了')
18 break
while。。。。else语法
while 后面的 else 是指:当while 循环正常执行完,中间没有被 break 终止的话,就会执行后面的 else 语句
1 i = 0
2 while i<3:
3 print('That`s ok')
4 i +=1
5 else:
6 print('loogup')
7
8 输出
9 That`s ok
10 That`s ok
11 That`s ok
12 loogup
当 while 循环被 break 终止后
1 i = 0
2 while i<3:
3 print('That`s ok')
4 break
5 i +=1
6 else:
7 print('loogup')
8
9 输出
10 That`s ok
deade loop 死循环
当我们写一个循环时如果没有终止语句,那么这个循环变成一个死循环
1 username = input('请输入你的名字')
2 print('欢迎 %s 来到猜年龄游戏!'% username)
3 age = 18
4 i = 0
5 while i <3:
6
7 guess = int(input('请输入你猜的数字:'))
8
9 if guess > age:
10 print('It`s too bigger! please try again')
11
12 elif guess <age:
13
14 print('It`s too smaller! please try again')
15
16 elif guess == age:
17 print('恭喜你,答对了')
怎么防止变成死循环呢,就需要使用循环终止语句
循环终止语句
如果在 循环中我们需要终止某个循环,那么我们 就需要使用 break 和 continue 语句
- break:用于完全结束一个循环语句,跳出循环执行后面的语句
- continue:和 break 类似,区别在于continue 只是终止本次循环,接着执行后面的循环,break 则完全终止
用 while 做一个猜年龄的游戏,只能才三次,猜对后 break 退出循环
1 username = input('请输入你的名字')
2 print('欢迎 %s 来到猜年龄游戏!'% username)
3 i = 0
4 while i <3: # 当 i 大于等于3时,循环结束
5 guess = int(input('请输入你猜的数字:'))
6
7 if guess > age:
8 print('It`s too bigger! please try again')
9
10 elif guess <age:
11 print('It`s too smaller! please try again')
12
13 elif guess == age:
14 print('恭喜你,答对了')
15 break # 猜对后退出循环
16
17 i += 1 # 没循环一次 i 加 1
那,现在要求错误三次后来一次询问,是否继续游戏,接下来这么写
1 username = input('请输入你的名字')
2 print('欢迎 %s 来到猜年龄游戏!'% username)
3 age = 18
4 i = 0
5 while i <3:
6
7 guess = int(input('请输入你猜的数字:'))
8
9 if guess > age:
10 print('It`s too bigger! please try again')
11
12 elif guess <age:
13
14 print('It`s too smaller! please try again')
15
16 elif guess == age:
17 print('恭喜你,答对了')
18 break
19
20 i += 1
21 if i ==3: # 判断 i 是否等于3
22
23 print('错误三次')
24 userinput = input('是否还想玩?y|n :')
25 if userinput == 'y':
26 i =0
27 print('请继续游戏')
28
29 else:
30 print('欢迎下次光临!')
for 循环
在前面已经介绍过while语句了,while 语句非常灵活,可用于在条件为真时反复执行代码块。再通常情况下很好,但有时你需要定制。
一种这样的需求是为序列(或其他可迭代对象)中的每个元素执行代码块
注意:基本上,可迭代对象是可使用 for 循环进行遍历 的对象。
为此,可使用 for 语句:
1 nums =[1,2,3,4,]
2 for num in nums:
3 print(num)
4 输出
5 1
6 2
7 3
8 4
提示:能使用 for 循环就不要使用 while 循环!
字符编码
二进制
二进制定义
二进制是计算技术中广泛采用的一种数制。二进制数据是用0和1两个数码来表示的数。它的基数为2,进位规则是“逢二进一”,借位规则是“借一当二”,由18世纪德国数理哲学大师莱布尼兹发现。当前的计算机系统使用的基本上是二进制系统,数据在计算机中主要是以补码的形式存储的。计算机中的二进制则是一个非常微小的开关,用“开”来表示1,“关”来表示0。
每一位 0 和 1 所占的空间单位为 bit(比特),这是计算机最小的 单位
二进制与十进制转换
二进制的第n位代表的十进制值都刚好遵循着2的n次方这个规律
十进制转二进制方法相同,只要对照二进制为1的那一位对应的十进制值相加就可以了。
128 62 32 16 8 4 2 1
0 0 0 0 0 0 0 0
10 1 0 1 0
60 1 1 1 1 0 0
十进制转二进制、八进制、十六进制
1 dec = int(input("输入数字:")) 2 3 print("十进制数为:", dec) 4 print("转换为二进制为:", bin(dec)) 5 print("转换为八进制为:", oct(dec)) 6 print("转换为十六进制为:", hex(dec)) 7 8 输入数字:6 9 十进制数为: 6 10 转换为二进制为: 0b110 11 转换为八进制为: 0o6 12 转换为十六进制为: 0x6
字节单位转换:

上面讲了如何将十进制转为二进制,那计算机是怎么将文字转为二进制呢?

在讲这个 之前我们需要了解字符编码
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号
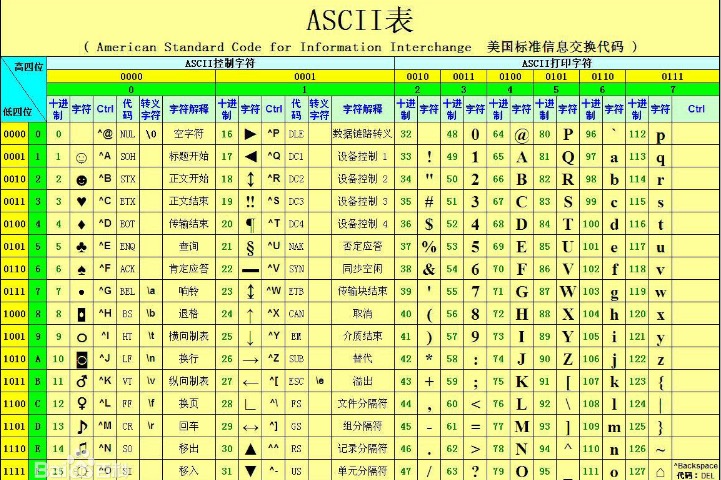
由于ASCII 的局限性,不能够适用于世界上不同国家不同的语言,所以各国就搞出了自己的编码
中国人规定了自己的标准gb2312编码,规定了包含中文在内的字符->数字的对应关系
日本人规定了自己的Shift_JIS编码
韩国人规定了自己的Euc-kr编码
但是为了世界的发展,所以编码必须有一个统一的标准。So unicode应运而生
- ascii用1个字节(8位二进制)代表一个字符
- unicode常用2个字节(16位二进制)代表一个字符,生僻字需要用4个字节
但是问题又来了由于Unicode表示一个字符需要16位,而ASCII只需要8位。并且Unicode在储存上比ASCII多出来一倍的空间。所以为了抵制铺张浪费 utf-8 就降世了。
UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
编码的种类情况

- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- Shift-JIS 日本字符
- ks_c_5601-1987 韩国编码
- TIS-620 泰国编码
由于每个国家都有自己的字符,以上编码都存在局限性,应运而生出现了万国码,他涵盖了全球所有的文字和二进制的对应关系
- Unicode 2-4字节 已经收录136690个字符,并还在一直不断扩张中...
Unicode 起到了2个作用:
- 直接支持全球所有语言,每个国家都可以不用再使用自己之前的旧编码了,用unicode就可以了。(就跟英语是全球统一语言一样)
- unicode包含了跟全球所有国家编码的映射关系,为什么呢?后面再讲
Unicode解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
- UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
- UTF-32: 使用4个字节表示所有字符;
总结:UTF 是为unicode编码 设计 的一种 在存储 和传输时节省空间的编码方案。
编码的转换
python3 执行代码的过程
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
- 把代码字符串按照语法规则进行解释,
- 所有的变量字符都会以unicode编码声明
在python3里utf-8可以在Windows GBK终端上显示,是因为python解释器把utf-8转成了Unicode。但是在python 2中是会乱码的,因为python 2默认支持的是ASCII,想写中文就必须在文件开头声明你是以什么编码去写的(gbk or utf-8,)。python2解释器仅以文件头声明的编码去解释你的代码,并不会去自动转成Unicode。即你的文件编码是utf-8,加载到内存里,你的变量字符串还是utf-8,在Windows中就会乱码
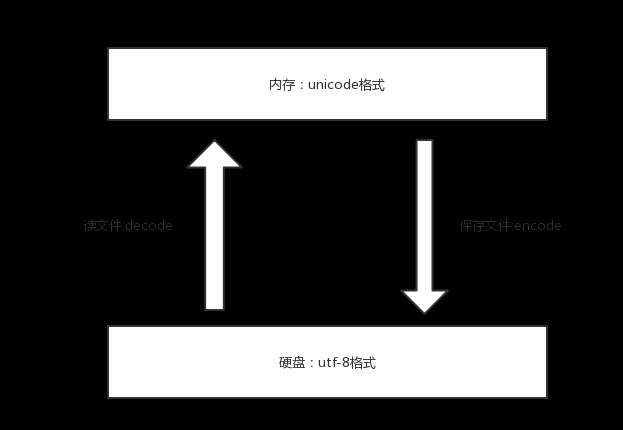
编码和 解码图示:

unicode与gbk的映射表 http://www.unicode.org/charts/
文件读取写入编码转换:
1、在存入磁盘时,需要将unicode转成一种更为精准的格式,utf-8:全称Unicode Transformation Format,将数据量控制到最精简
2、在读入内存时,需要将utf-8转成unicode
所以我们需要明确:内存中用unicode是为了兼容万国软件,即便是硬盘中有各国编码编写的软件,unicode也有相对应的映射关系,但在现在的开发中,程序员普遍使用utf-8编码了,估计在将来的某一天等所有老的软件都淘汰掉了情况下,就可以变成:内存utf-8<->硬盘utf-8的形式了。