Python3 基本数据知识
Python3 基本数据知识
变量
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。等号(=)
用来给变量赋值。
变量起名:
-
通俗易懂 方便后续出措施及时更改
-
变量名只能是字母、数字、下划线的组合
-
变量的首字符不能是数字
- 数字不能开头
- 特殊字符不能开头
- 字符中间不能有空格
-
关键字不能作为变量名
-
格式:
- welcome_to_you 下划杠链接法 (官方推荐)
- WelcomeToYou 驼峰法,首字母大写
变量赋值:
Python中用等号(=)运算符用来链接变量名称和所赋的值,如下:
a = 1
new_input = 6
print (a)
print(new_input)
1
6
多个变量赋值
Python中可以同时为多个变量赋值。例如:
1 a = b = c = 6 2 3 print(a,b,c) 4 6 6 6 5 6 a,b,c=6,8,'new' 7 8 print (a,b,c) 9 6 8 new
常量
常量即不变的量,如:∏ 3.1415926...或在程序中不变的量
在Python中没有特定语法表示常量,约定成俗用变量名全部大写来代表常量
在C语言中有专门定义常量的语法:count int count = 6868 一旦定义为常量,更改就会报错
Python 基本数据类型
Python3 中有六个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dict(字典)
- Sets(集合
- 布尔型
通用的序列操作:索引、切片、相加、相乘、成员资格检查
- 索引:序列的所有元素都有编号(左0~右-1:即左边从零开始,右边从-1开始),可以通过这些编号来获取元素
- 切片:使用两个索引,并用冒号(:)隔开来获取一定范围内的元素
- 相加:使用加法运算符拼接序列
- 相乘:将序列与x相乘,将重复这个序列x次来创建一个新序列
- 成员资费检查:使用运算符 in 检查特定的值是否包含在序列中,并返回相应的值
注意:切片:两个索引来指定切片的边界,其中第一个索引指定的元素包含在切片内,第二个不包含在切片内
成员资格检查: 满足时返回True,不满足时返回Flase。这样的运算符称为布尔运算符,真假值称为布尔值
1. Number(数字):
Python3 支持 int、float、bool、complex(复数)。内置的 type() 函数可以用来查询变量所指的对象类型。


1 a,b,c = 6,1.5,1+4j 2 3 print (a,b,c) 4 6 1.5 (1+4j) 5 6 print(type(a),type(b),type(c)) 7 <class 'int'> <class 'float'> <class 'complex'>
其中,6为 int (整数)、1.5为 float(浮点数)、1+4j 为 complex (复数:复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型)!
int(整型)
在32位机器上,整数的位数为32位,取值围为 :2**31-2**31-1,即 -2147483648 ~ 214748364
在64位机器上,整数的位数力64位,取值围为 : 2**63-2**63-1,即 -9223372000854775808 ~ 9223372036854775807
long(长整型)
C语言不同,Pyto的长整数没有指定位宽,即 Atlo有限制长整数数借的大小,但实际上曲于机器内存有思,我们使用的长整数数不可用无大,
注意:自从Python 2.2起.如果整数发生溢出, Python自动将整数数转换为长数,所以如今在长整数数据后不加字母L也不会导到严重后果了
注意:在 Python3里不再有long类型了,全都是 int
Python 中除了 type外,还有一种判断字符类型方法,isinstance:
1 a,b,c = 6,1.5,1+4j 2 3 isinstance (a,int) 4 Out[17]: True 5 6 isinstance (b,float) 7 Out[18]: True 8 9 isinstance (c,complex) 10 Out[19]: True
type 和 isinstance 的区别:
- type()不会认为子类是一种父类类型。
- isinstance()会认为子类是一种父类类型。
注意:在 Python2 中没有布尔型的,它用数字 0 表示 False,用 1 表示 True。
在Python3 中,把 True 和 False 定义成关键字了,但它们的值还是 1 和 0,它们可以和数字相加
数值运算:
1 1+1 #加法运算 2 Out[23]: 2 3 4 1*2 #乘法运算 5 Out[24]: 2 6 7 4/2 #除法运算 8 Out[25]: 2.0 9 10 4//2 #除法运算 取整数 11 Out[29]: 2 12 13 14 4%2 # 除法 %为取余数的 15 Out[26]: 0 16 17 4-1 #减法运算 18 Out[27]: 3 19 20 2**3 #冥运算 21 Out[28]: 8
2.String(字符串):
Python中的字符串用单引号 ( ' ) 、双引号 ( " )、三引号 ( ’‘’ )括起来,同时使用反斜杠 ( \ ) 转义特殊字符。So 所有加引号的都是字符串!另,字符串内的字符不能改变!
字符串的语法格式如下:
1 name = 'Python' 2 3 print (name) 4 Python
字符串运算格式:
1 name = 'Hello Word!' 2 3 print (name) 4 Hello Word! 5 6 name *3 #乘法 7 Out[34]: 'Hello Word!Hello Word!Hello Word!' 8 9 name = 'Hello Word!'+'Hello Python!' #加法 10 11 print (name) 12 Hello Word!Hello Python!
Python 使用反斜杠(\)转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串。
字符串格式化
如果我们要打印一个人员信息表,那么可以这样写
1 Name = 'Jack' 2 Age = '18' 3 Job = 'Teacher' 4 Hometown = 'Sun' 5 print('========== info of name=========') 6 print('Name:',Name) 7 print('Age:',Age) 8 print('Job:',Job) 9 print('Hometown:',Hometown) 10 print('============ end ===============') 11 12 输出: 13 ========== info of name========= 14 Name: Jack 15 Age: 18 16 Job: Teacher 17 Hometown: Sun 18 ============ end ===============
上述代码写的比较繁琐,有没有简单的方式呢?那就是字符串格式化
1 info = ''' 2 ========== info of %s ========= 3 Name: %s 4 Age %s 5 Job: %s 6 Hometown: %s 7 ============ end ============== 8 ''' % (Name,Name,Age,Job,Hometown) 9 print(info) 10 11 输出: 12 ========== info of Jack ========= 13 Name:Jack 14 Age:18 15 Job:Teacher 16 Hometown:Sun 17 ============ end ==============
在上述代码中,%s 相当于一个占位符,就是给后续传进的参数占个位置,类似于 %s 这样的占位符有以下几种
- %s :string(字符串)
- %d:digit(数字)
- %f:float(浮点数)
如果你在代码中写的是 %d ,那么后续传参必须是数字。注意: 后续传参必须与占位符相对应
1 info = ''' 2 ========== info of %s ========= 3 Name:%s 4 Age:%d # 此处需要数字 5 Job:%s 6 Hometown:%s 7 ============ end ============== 8 ''' % (Name,Name,Age,Job,Hometown) 9 print(info) 10 11 输出: 12 Traceback (most recent call last): 13 File "C:/Users/legend/Desktop/作业集/1/te.py", line 34, in <module> 14 ''' % (Name,Name,Age,Job,Hometown) 15 TypeError: %d format: a number is required, not str
为什么上述代码还是报错了呢?那是因为 input 读取的都是字符串,那么我们就需要把它转化成数字
1 Name = 'Jack' 2 Age =int ('18') # int 将字符串转化成数字 3 Job = 'Teacher' 4 Hometown = 'Sun' 5 6 输出: 7 ========== info of Jack ========= 8 Name:Jack 9 Age:18 10 Job:Teacher 11 Hometown:Sun 12 ============ end ==============
结果来看,不就OK了?在上述情境下,如果不小心将 %d 写成 %s了,会不会报错呢?
1 info = ''' 2 ========== info of %s ========= 3 Name:%s 4 Age: %s # 此处应为 %d 5 Job: %s 6 Hometown:%s 7 ============ end ============== 8 ''' % (Name,Name,Age,Job,Hometown) 9 print(info) 10 11 输出: 12 ========== info of Jack ========= 13 Name:Jack 14 Age:18 15 Job:Teacher 16 Hometown:Sun 17 ============ end ==============
是不是有点出乎意料?,为什么会这样呢?那是应为你有 转化符 “ int ”。int 将参数转化为数字类型,So 无论你写成 %s 还是 %f,它都不会报错
字符串常用方法:
所有的标准序列 操作(索引、切片、乘法、成员资格检查、长度、最大/小值)都适用于字符串,但所有的元素 复制和切片复制都是非法的
1 seq = [1,2,3,4] #错误原因:序列中的元素必须为字符串 2 3 '+'.join(seq) 4 5 Traceback (most recent call last): 6 7 File "<ipython-input-17-8aa8af360004>", line 1, in <module> 8 '+'.join(seq) 9 10 TypeError: sequence item 0: expected str instance, int found 11 12 13 seq = ['1','2','3','4'] 14 15 a.join(seq) 16 17 Out[12]: '1+2+3+4' 18 19 name = 'Tom','Tony','Jack' 20 21 '/'.join(name) 22 23 Out[14]: 'Tom/Tony/Jack'
split:将字符串拆分为序列的方法,和 join 作用相反(非常重要)
1 list_str ='1 2 3 4 5 ' 2 3 list_str.split() #()内可以以逗号、空格为切分点 4 Out[41]: ['1', '2', '3', '4', '5']
1 sentence = 'If you want to be better,so star working hard!' 2 3 sentence.find('to') 4 5 Out[2]: 12
replace:将指定子串都替换成另一个字符串,并返回替换后的结果
1 name_str= 'Hello Python' 2 3 print (name_str) 4 Hello Python 5 6 name_str.replace ('Python','Word') 7 Out[4]: 'Hello Word'
1 name_str= 'Hello Python' 2 3 name_str.upper() #大写替换 4 Out[8]: 'HELLO PYTHON' 5 6 name_str.lower() #小写替换 7 8 Out[9]: 'hello python'
1 name_str=',,hello word,' 2 3 name_str.strip (',') #删除‘’内元素 4 5 Out[12]: 'hello word' 6 7 name_str.lstrip(',') #删除左边‘’内元素 8 9 Out[13]: 'hello word,' 10 11 name_str.rstrip(',') #删除右边‘’内元素 12 13 Out[14]: ',,hello word'
1 name_str = 'we are family!' 2 3 name_str.capitalize() 4 5 Out[16]: 'We are family!'
center:通过在两边添加字符(默认为空格)让字符 串居中
1 sentence = 'Wolcome to you!' 2 3 sentence.center(20) 4 5 Out[5]: ' Wolcome to you! ' 6 7 sentence.center(30,"*") 8 9 Out[6]: '*******Wolcome to you!********'
♠引号扩展♣:
单引号 ( ' ) 、双引号 ( " )、多引号 ( ’‘’ )使用场景
场景一:
在代码中不包含单引号的时候,单双多引号均可使用
1 name = 'Jack' 2 name1 = "Jack" 3 name2 = '''jack''' 4 print(type(name),type(name2),type(name1),) 5 输出: 6 <class 'str'> <class 'str'> <class 'str'>
场景二:
当代码中包含单引号时,只能使用双引号或多引号
1 sentence = " Sentence : 'Hi! I`m Jack!'" 2 print(type(sentence),sentence) 3 输出: 4 <class 'str'> Sentence : 'Hi! I`m Jack!'
场景三
当代码语句较长时,使用多引号来连接语句
1 poem = '''天苍苍, 2 野茫茫, 3 风吹草低见牛羊''' 4 print(poem) 5 输出: 6 天苍苍, 7 野茫茫, 8 风吹草低见牛羊
3.List(列表):
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(即所谓嵌套)。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
列表的创建有两种方式:
- 通过中括号 ([]) 来创建
- 通过list来进行创建
1 a = [1,2,3,4,5,6,] #通过【】来创建 2 3 print (a) 4 [1, 2, 3, 4, 5, 6] 5 6 7 a = list([1,2,3,4,5,6,]) #通过 list 来创建 8 9 print(a ) 10 [1, 2, 3, 4, 5, 6] 11 12 a=list('1,2,3,4,5,6,') #通过 list 来创建中间用逗号隔开 13 14 print (a) 15 ['1', ',', '2', ',', '3', ',', '4', ',', '5', ',', '6', ',']
列表的运算格式如下:
1 a=[741,852] 2 b=['wang','tao'] 3 4 a+b #加法 为两个 list 所有元素相加并组成一个新 list 5 6 Out[]: [741, 852, 'wang', 'tao'] 7 8 9 a*2 #乘法 为复制 list 中所有元素 10 11 12 Out[2]: [741, 852, 741, 852]
list 常用方法操作:
1 a = [6, 2, 3, 4, 5] 2 3 6 in a # in/not in 判断某元素是否在list中并返回 ture/flase 4 5 Out[79]: True
1 a = [1,1,3,4,6,7,1,3,] 2 3 a.count (1) # count 计算某元素在list中出现的次数 4 5 Out[82]: 3
1 a = [1,2,3,4,5,6,7,'sd'] 2 3 a.index ('sd') # index 检索某元素在list中的位置 4 5 Out[85]: 7
1 a = [1,2,3,4,5,6,7,'sd'] 2 3 a.append ('88') # append 增加 往list中新增某元素,只能增加单个 4 5 a 6 Out[87]: [1, 2, 3, 4, 5, 6, 7, 'sd', '88']
1 a = [] 2 3 a.insert (0,66) # insert 往list中某位置插入某元素 4 5 a 6 Out[93]: [66] 7 8 a.insert (1,'good') 9 10 a 11 Out[96]: [66, 'good'] 12 13 14 a.insert (2,['hello','word']) # insert 往list中某位置插入多个元素 15 16 17 a 18 Out[100]: [66, 'good', ['hello', 'word']]
reverse:按相反的顺序排列列表中的元素
1 a = [1,2,3,4,2,1,5] 2 3 a.reverse() 4 5 a 6 7 Out[29]: [5, 1, 2, 4, 3, 2, 1]
sort:对列表就地排序
1 a =[6,5,4,3,2,1] 2 3 a.sort() 4 5 a 6 7 Out[32]: [1, 2, 3, 4, 5, 6]
remove:用于删除第一个为指定值的元素
1 a = [1,2,3,2,4,1] 2 3 a.remove(1) 4 5 a 6 7 Out[35]: [2, 3, 2, 4, 1] 8 9 a.remove(2) 10 11 a 12 13 Out[37]: [3, 2, 4, 1]
clear:就地清空列表的内容
1 dd = [1,2,3,4,5,] 2 3 dd.clear() 4 5 dd 6 Out[5]: []
1 a = [1,2,3,4,] 2 3 c = [7,8,9,] 4 5 c.extend(a) 6 7 c 8 Out[12]: [7, 8, 9, 1, 2, 3, 4]
1 a = [1,2,3,4,] 2 3 a.pop() 4 Out[13]: 4 5 6 a.pop(1) 7 Out[15]: 2
4.元组( tuple):不可修改的序列
元组和列表相似,但元组不可修改。元祖的创建用小括号 ‘()’,而且元组语法非常简单,只需将元素用逗号分隔开。
a = (1,2,3,4,) a Out[17]: (1, 2, 3, 4) b = 5,6,7, # 元组中的逗号不可或缺,没有逗号就无法创建元组 b Out[19]: (5, 6, 7) c = () # 空元组创建 c Out[21]: ()
函数 tuple 的工作原理和 list 类似:它可以将一个序列作为参数 ,并转化成元组。本身为元组则返回本身值。
tuple ([1,2,3,]) # 将列表转化为元组 Out[22]: (1, 2, 3) tuple ('name') # 将字符串转化成元组 Out[23]: ('n', 'a', 'm', 'e') tuple ((1,2,3,)) # 元组本身不动 Out[24]: (1, 2, 3)
元组方法:
a = (1,2,3,4,) a [1] # 索引 Out[27]: 2 a [0:2] # 切片,元组的切片也是元组同列表一样 Out[28]: (1, 2)
可变与不可变类型
截止到目前为止我们已经学过的数据类型中:数字、字符串、列表、元祖。
在python中,我们还有另外一种分类方式,我们把数据类型分为可变和不可变类型:
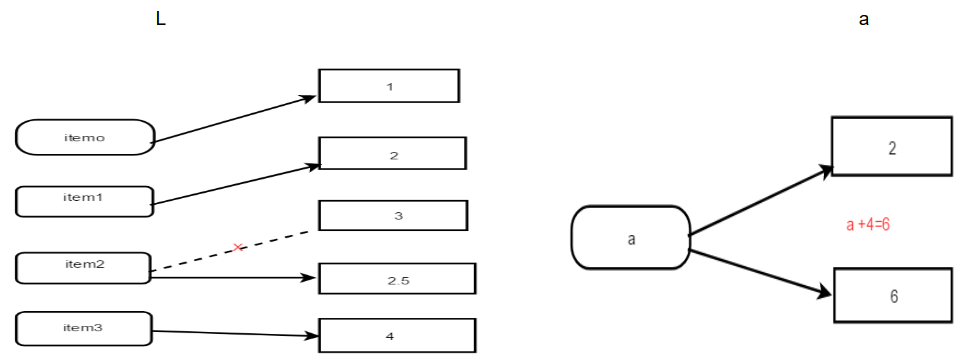
我们来看看什么叫可变什么叫不可变
列表
1 li =[1,2,3,4] 2 3 print(id(li)) 4 2165693836616 5 6 li[2] =2.5 7 8 print(li) 9 [1, 2, 2.5, 4] 10 11 print(id(li)) 12 2165693836616
数字
1 a= 2 2 print(id(a)) 3 1642360320 4 5 a+=4 6 print(a) 7 out:6 8 9 print(id(a)) 10 1642360448
我们来从内存角度来看 变与不变
字符串
1 a = 'hello' 2 3 print(a[2]) 4 out: l 5 6 a[2] ='e' 7 8 Traceback (most recent call last): 9 File "C:/Users/legend/Desktop/作业集/Second module 作业 & 练习/练习.py", line 112, in <module> 10 a[2] ='e' 11 TypeError: 'str' object does not support item assignment
字符串也可以像列表一样使用索引操作,但是通过上例可以看出,我们不能像修改列表一样修改一个字符串的值,当我们对字符串进行拼接的时候,原理和整数一样,id值已经发生了变化,相当于变成了另外一个字符串。
元组----不允许修改
1 t = (1,2,3,4) 2 t[1] = 1.5 3 4 Traceback (most recent call last): 5 File "<pyshell#10>", line 1, in <module> 6 t[1] = 1.5 7 TypeError: 'tuple' object does not support item assignment
hash
Hash,一般翻译做“散列”,也有直接音译为“哈希”的。那么哈希函数的是什么样的?大概就是 value = hash(key),我们希望key和value之间是唯一的映射关系。
鉴于这一点,我们就需要序列中的元素时不可变。那对于上述四个类型,可hash的为:字典、字符串、元组;不可hash的为:列表。
总而言之:可变的数据类型是不可以被hash的,一个值可以hash那么说明这是一个不可变得数据类型。
5.字典 (dict)
映射:可以通过名称来访问其各个值的数据结构,让你能够使用任何不可变的对象(最常用的是字符创和元组)来表示其元素
字典是Python中唯一的内置映射类型。
字典是由键和其相对应的值组成的,每一个键值对称为一个项。每个键与其值之间用冒号( :)分隔,项之间用逗号分隔。整个字典由两个花括号( { } )来包括。
注意:在字典(以及其他映射类型中),每个键都是独一无二的,而字典内的值可以是重复的!
(1)字典的创建方式:
- 直接用{}创建,常用方式 如 a ={}
a = {}
type (a)
Out[33]: dict
(2)字典的基本操作:
- len(d)返回字典 d包含的项(键值对)数
- d [k] 返回与键k相对应的值
- d [k] = v 将值v关联到键k
- del d [k]删除键为k的项
- k in d 检查字典d是否包含犍为k的项
键的类型:字典内的键可以使任何不可变的类型,如浮点数(复数)、字符创或元组
(3)将字符串的格式设置功能用于字典
people = { 'Alice':{'phone':'1654','addr':'Fjj sdf 3'},
'Bidj':{'phone':'231','addr':'Jiji street 231'}
}
"Alice`s personal information is {Alice}.".format_map (people)
Out[41]: "Alice`s personal information is {'phone': '1654', 'addr': 'Fjj sdf 3'}."
(4) 字典常用方法
clear :删除所有的字典项,返回None
clear:示例
1 per_inf = {'Tom':22,'Tony':25} 2 3 per_inf 4 5 Out[2]: {'Tom': 22, 'Tony': 25} 6 7 people =per_inf.copy() 8 9 people 10 11 Out[4]: {'Tom': 22, 'Tony': 25}
deepcopy:复制并返回一个新字典( 深复制:复制键值以及值所包含的所有值 ,在改变新字典内的嵌套的元素时,原字典不会改变)
1 from copy import deepcopy 2 3 per_inf = {'name':['Tom','Tony'],'age':['22','21']} 4 5 per_inf 6 Out[12]: {'age': ['22', '21'], 'name': ['Tom', 'Tony']} 7 8 p2= deepcopy(per_inf) 9 10 p2 11 Out[15]: {'age': ['22', '21'], 'name': ['Tom', 'Tony']} 12 13 p2['name'].append('Jack') 14 15 p2 16 Out[19]: {('age', '0'): 28, 'age': ['22', '21'], 'name': ['Tom', 'Tony', 'Jack']} 17 18 per_inf 19 Out[21]: {'age': ['22', '21'], 'name': ['Tom', 'Tony']}
fromkeys: 创建一个新字典,其中包含指定的键,且每个键对应的值都是None
1 {}.fromkeys(['name','age']) #先创建一个新字典在调用方法创建新字典 2 3 Out[22]: {'age': None, 'name': None} 4 5 dict.fromkeys(['name','age']) #直接对 dict 调用方法 6 7 Out[24]: {'age': None, 'name': None} 8 9 dict.fromkeys(['name','age'],'N/A') #使用指定的值 N/A 10 11 Out[25]: {'age': 'N/A', 'name': 'N/A'}
get:通过指定的键访问字典项并获取其对应的值
1 p = {'Tom': 22, 'Tony': 25} 2 3 p.get('Tom') # 使用get访问存在的键时,其作用与查找相同 4 5 Out[28]: 22 6 7 p.get('Jack') # 使用get访问不存在的键时,将会返回None而不会报错 8 9 ret = p.get('Jack') 10 11 print (ret) 12 13 None
items:返回一个包含所有字典项的列表
1 p = {'Tom': 22, 'Tony': 25} 2 3 p.items() 4 5 Out[34]: dict_items([('Tom', 22), ('Tony', 25)])
keys:返回一个包含字典内所有键的序列
keys:示例 values:返回一个包含字典内所有值得序列
values:示例 pop:获取与指定键相对应的值,并将该键值对从字典内删除
people = {'Tom': ['small', 'beautiful'], 'Tony': 'helllo'}
people.pop('Tony')
Out[85]: 'helllo'
people
Out[86]: {'Tom': ['small', 'beautiful']}
popitem:随机的弹出一个字典项
people = {'Tom': ['small', 'beautiful'], 'Tony': 'helllo'}
people.popitem()
Out[88]: ('Tony', 'helllo')
setdefault:获取与指定键相关联的值,在字典内不包含指定的键时,添加指定的键值对
dic ={} dic.setdefault('name','N/A') Out[91]: 'N/A' dic['name'] = 'Tom' dic.setdefault('name','N/A') Out[93]: 'Tom' dic Out[94]: {'name': 'Tom'}
update: 使用一个字典中的项来更新另一个字典
dic1 = {'name': 'Tom','age':'lal'}
dic2 = {'name':'Jonu','hello':'python'}
dic2.update(dic1)
dic2 # 使用 dic1 中的项来更新 dic2,有相同的键会替换其对应的值
Out[98]: {'age': 'lal', 'hello': 'python', 'name': 'Tom'}
6. set (集合)
set是一个无序且无重复元素的序列
set 创建方式:
- 通过 {} 来创建
- 通过set ()来创建
注意:创建一个空集合必须用 set()来创建,因为 {} 是用来 创建一个空字典
1 a= set([1,2,3,4,2]) # 通过 set()创建集合 ,set自带去重功能 2 3 a 4 5 Out[40]: {1, 2, 3, 4} 6 7 b = {1,2,3} # 通过{}创建集合 8 9 b 10 11 Out[42]: {1, 2, 3} 12 13 a = {} # 此为创建一个新字典 14 15 type(a) 16 17 Out[44]: dict 18 19 a =set() # 此为创建一个新集合 20 21 type(a) 22 23 Out[46]: set
7.布尔值
布尔类型就两个值:真(True)和 假(Flase),主要用于逻辑判断
1 a = 2 2 b = 19 3 print(a>b) 4 print('#########') 5 print(b>a) 6 7 输出: 8 False 9 ######### 10 True
那,知道结果后可以进行其他操作
1 if a>b: # 条件判断,根据结果进行下一步 2 print('a is bigger than b') 3 4 else: 5 print('b is bigger than a') 6 7 输出: 8 b is bigger than a
