多路复用
作者:李蒙
链接:https://www.zhihu.com/question/28594409/answer/478575374
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://www.zhihu.com/question/28594409/answer/478575374
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
下面举一个例子,模拟一个tcp服务器处理30个客户socket。假设你是一个超市老板,30个用户分别买不同的东西,但是有的商品有库存有的商品没有库存需要等待供应商送货,然后有下面几个选择:
- 第一种选择:按顺序逐个检查,A用户先来买卫生纸,B用户买手电筒,C用户买泡面。。。。,逐个处理的结果是A用户买完走了,但是B用户的商品卖完了等待供应商送货30分钟后货送到了B购买成功,继续处理C用户。。。,这样处理就相当于最后的需要等待前面的用户全部购买成功才能继续购买。这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。
- 第二种选择:你创建30个分身,每个分身去负责处理每个用户的购买请求。 这种类似于为每一个用户创建一个进程或者线程处理连接,但是Redis是单线程的
- 第三种选择,当A请求购买时 有货告知可以买 然后A购买,B请求购买 需要等待供应商送货 等待直到供应商送货过来 告知B来货了 B发起购买 购买成功;在B等待供应商的期间C用户的购买请求开始处理 有货直接购买成功 无需等待B用户购买。 这种就是IO复用模型
我认为第三种这个就是多路复用模型
然后希望以下回答可以帮助了解一些概念 解释了阻塞模型和多路复用模型的区别:
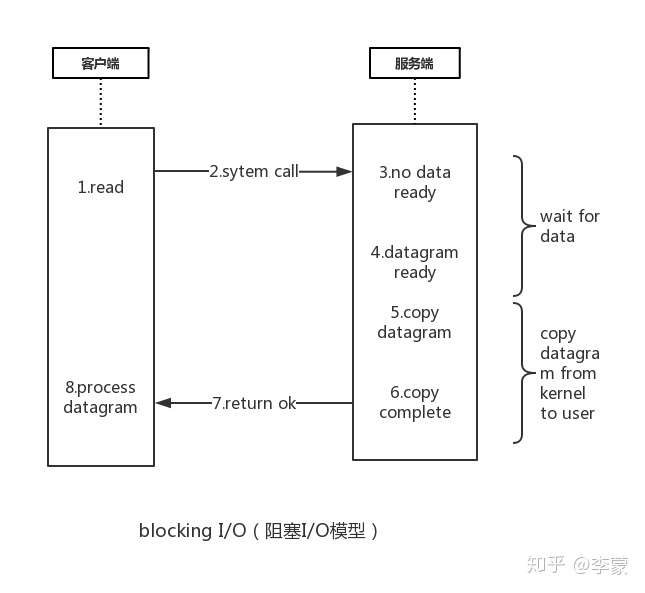
阻塞I/O模型
阻塞I/O顾名思义就是:
服务端面对并发请求逐个处理,如果其中一个请求准备数据处理时间过长会导致其他请求都在等待,系统的吞吐量下降。
具体流程可以参照下图:
- 客户端发起读(read)的命令
- 调用redis服务端
- 此时没有数据
- 数据报准备完成
- 复制数据报
- 复制完成
- 返回成功
- 客户端 处理数据报
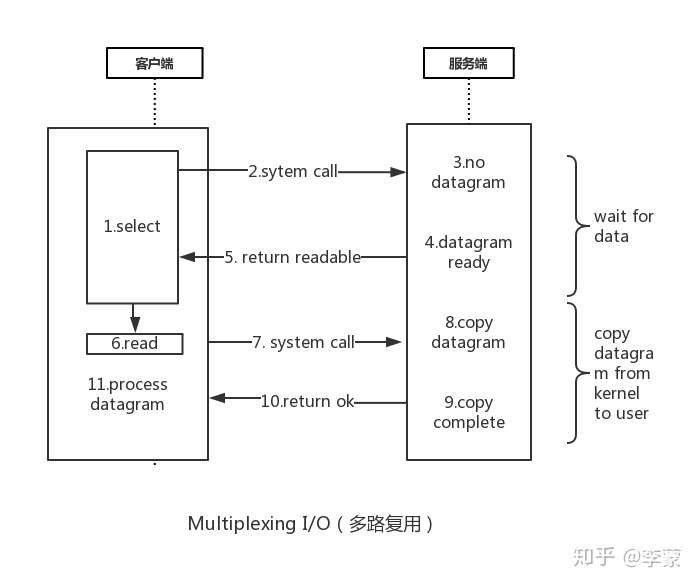
多路复用I/O模型
简单理解一下 就是
redis客户端先去select循环询问服务端是否可以发起read (主动去查看下现在有没有可以读的内容datagram ready)这个过程是阻塞的 但是速度很快,当服务端准备好了数据报告诉客户端readable,客户端即可发起read请求,此时因为服务端已经准备好了数据报,直接返回即可。整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的。这种方式避免了线程的阻塞,又称为非阻塞I/O模型
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗)
具体流程可以参照下图:
- 客户端select机制 循环请求
- 去请求服务端 询问是否可以read
- 此时没有数据
- 数据报准备完成
- 服务端告诉客户端 可以read了
1~5 这个过程是阻塞的 - 客户端发起read
- 系统调用read
- 复制数据报
- 复制完成
- 返回成功
- 客户端 处理数据报
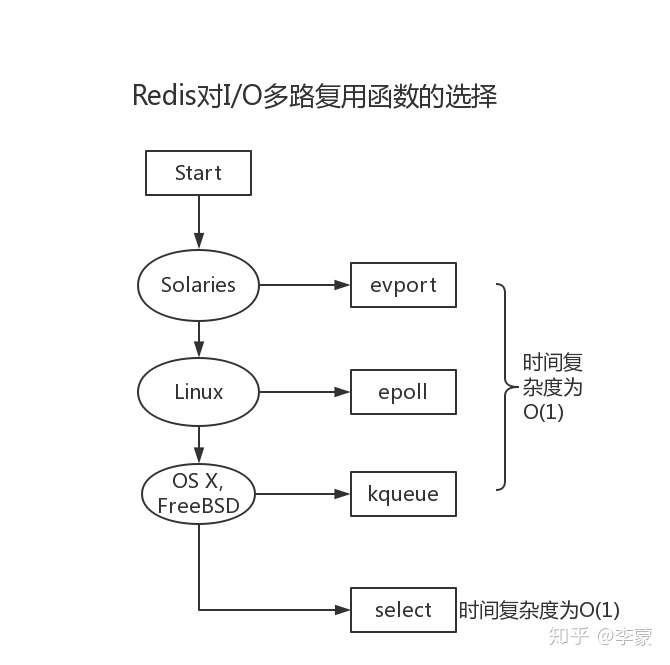
不同操作系统中的select复用函数
因为 select 函数是作为 POSIX 标准中的系统调用,在不同版本的操作系统上都会实现,所以将其作为保底方案:
Redis 会优先选择时间复杂度为 O(1) 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的 epoll 和 macOS/FreeBSD 中的 kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。
参考文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号