统计学习方法
boosting 算法: 通过改变训练样本的权重,学习多个分类器,并将多个分类器线性组合,提升分类性能。(对于一个复杂任务,将多个专家的判断进行适当的综合得出的判断,要比任一一个单独的判断好) 将弱学习方法boost 为强学习算法。因为弱学习算法相对容易求得。提升算法就是从弱学习算法,出发反复学习,得到一系列弱分类器,然后组合为强分类器。
两个问题:
1. 如何改变训练数据的权重或概率分布
2. 如何将弱分类器组合
adaboost:
1. 提升前一轮弱分类器错误分类样本的权值,降低正确分类样本的权值
2. 加权多数表决方法,加大分类误差率小的弱分类器的权值,减小分类误差大的弱分类器的权值
adaboost 算法模型为加法模型,损失函数为指数函数,学习算法为前向分布算法时的二类分类学习方法。
boosting tree,
EM 算法:
用于含有隐变量的概率模型参数的极大似然估计,或极大后验估计。
分为两步: E步,求期望;M步求极大,
引入: 概率模型有时既含有观测变量,又含有隐变量。 如果概率模型的变量都是观测变量,那么给数据,可以直接用极大似然估计。
例子:
3个硬币: A,B,C, 正面朝上的概率分别为x,p,q; 先抛掷A,根据结果选出硬币B或C,正面选B, 反面选C; 然后抛掷硬币,抛掷结果出现正面记为1,出现反面记为0; 重复n次试验
(1,1,0,1,0,0,1,0,1,1)
只能观测到抛掷硬币的结果,不能观测到过程,问如何估计3个硬币正面出现的概率。。即硬币模型的参数:
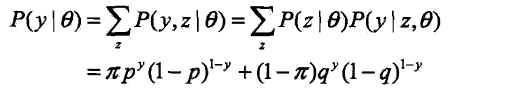


没有解析解,只有通过迭代的方法求解。。。。EM算法就是用于求解这类迭代算法。
HMM : 标注问题的统计学习模型。生成模型。
CRF(条件随机场):
给定一组输入随机变量条件下另一组输出碎甲变量的条件概率分布模型。特点是假定输出随机变量构成马儿克夫岁家常。
概率无向图模型。。MRF, 是可以由一个无向图表示的联合概率分布。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号