
达梦数据库分页查询优化记录
用户反馈正式上线之后,系统非常卡顿。迁移完之后没有收集统计信息,数据库参数优化脚本也没跑。弄完之后还是非常卡顿。排查发现cpu使用率超高
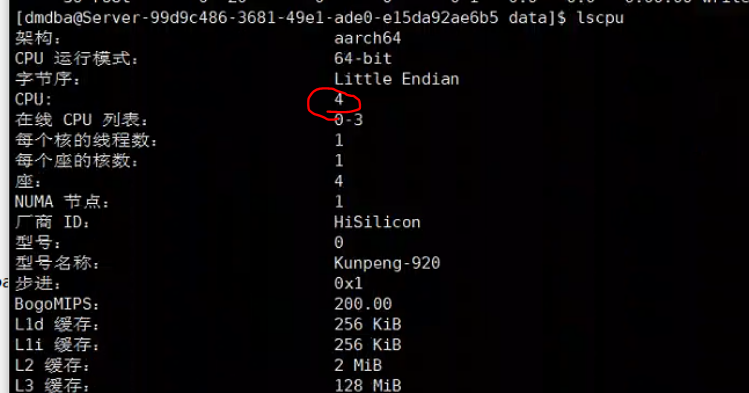
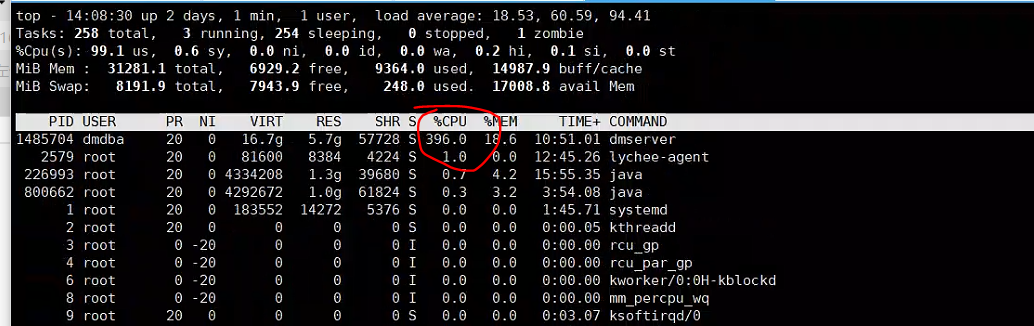
根据pid查找占用cpu较高的线程
ps -eLo pcpu,pmem,pid,tid,psr,wchan:14,comm|grep 1485704|sort

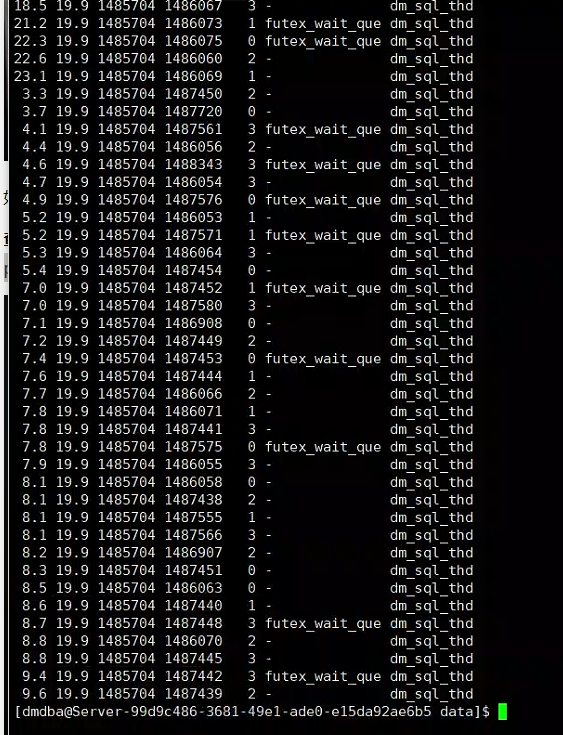
上图所示,都是dm_sql_thd线程占用cpu资源,根据线程号查找对应的sql,如下所示都分页查询
select * from v$sessions where thrd_id in ('1486069','1486060','1486075','1486073','1486067','1486068','1486062','1486072');![]()

具体sql及执行计划如下:表结构如下,ID_是主键,单独执行需要20s左右,并发量高的情况下将服务器资源耗尽,执行时间成倍增长。
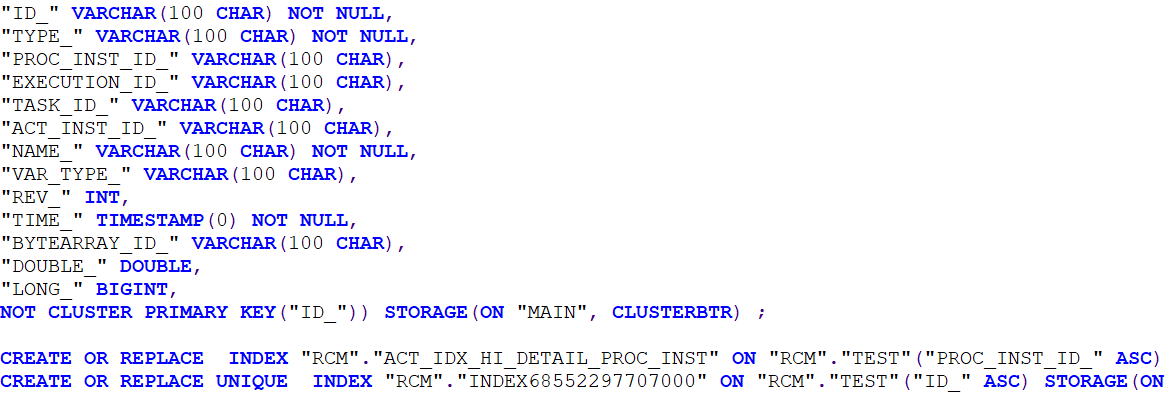
表总数是1千多万,通过PROC_INST_ID过滤之后,数据量是250
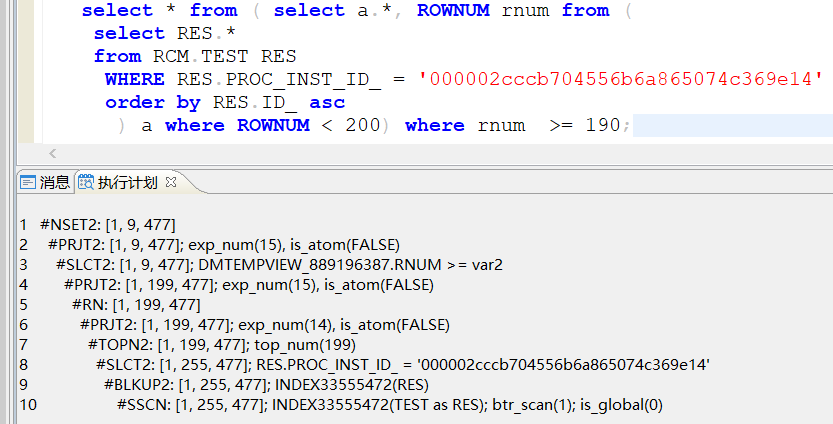
看执行计划应该不会这么慢,收集统计信息之后,执行计划还是一样,应该是客户端的执行计划不准。登录disql,执行如下查看sql真实的执行计划,新版本客户端有个按钮可以执行看真实执行计划
ALTER SESSION SET 'MONITOR_SQL_EXEC'=1;
set autotrace trace;
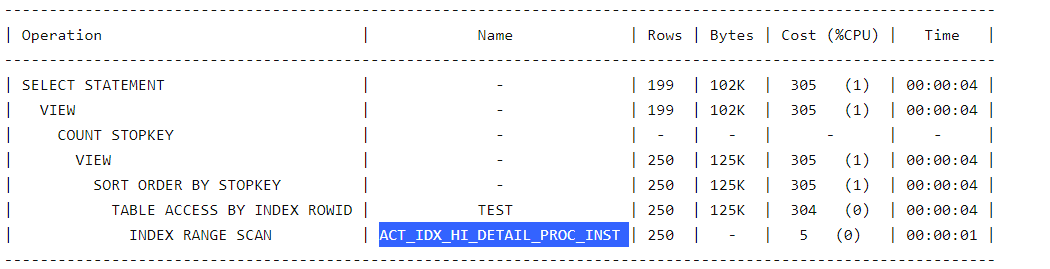
sql执行计划如下:真实结果集8百多万,逻辑读很大
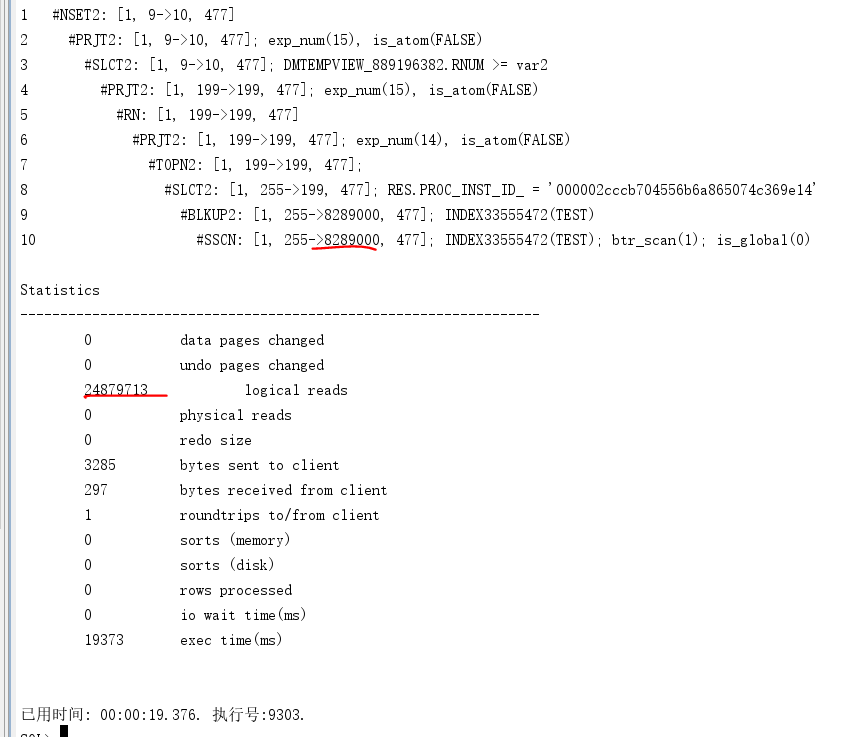
而把 order by RES.ID_ asc 注释掉之后,执行时间毫秒级别,执行计划如下
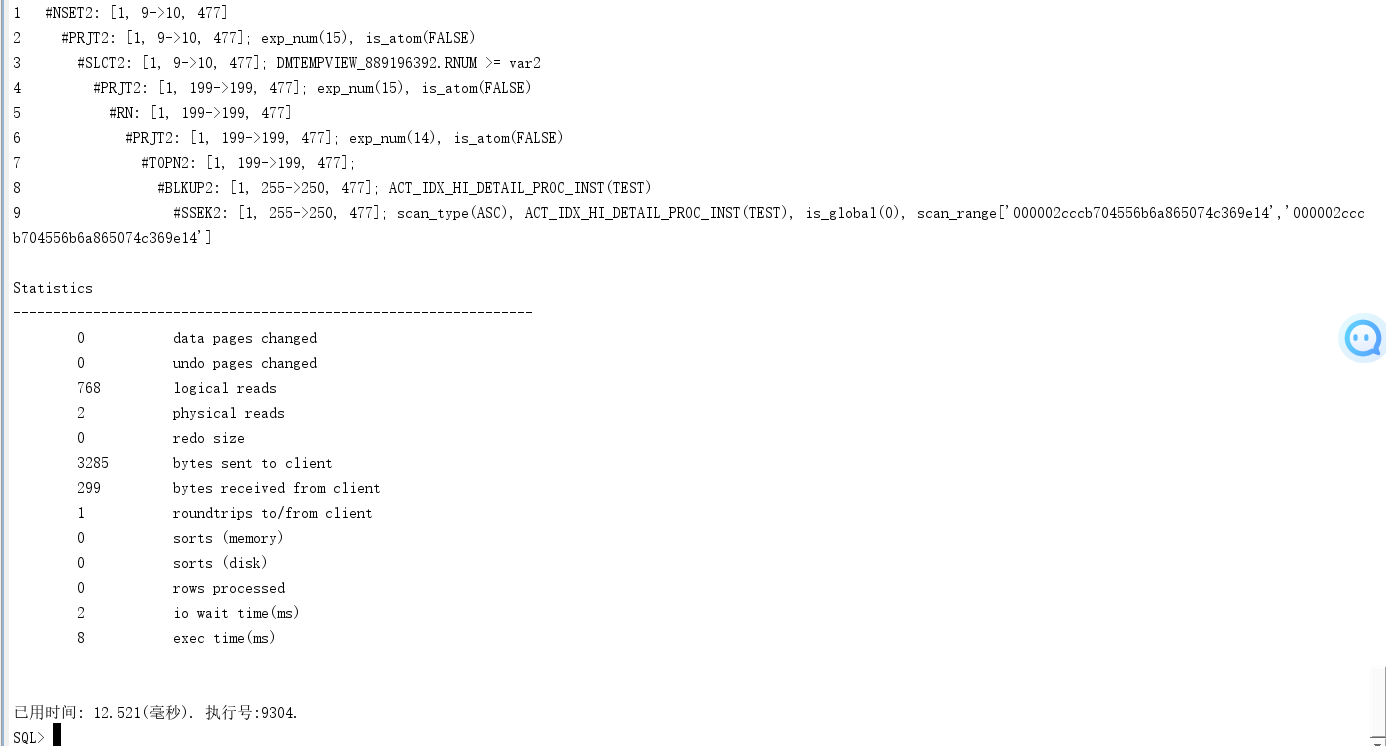
不分页,执行时间也很短![]()

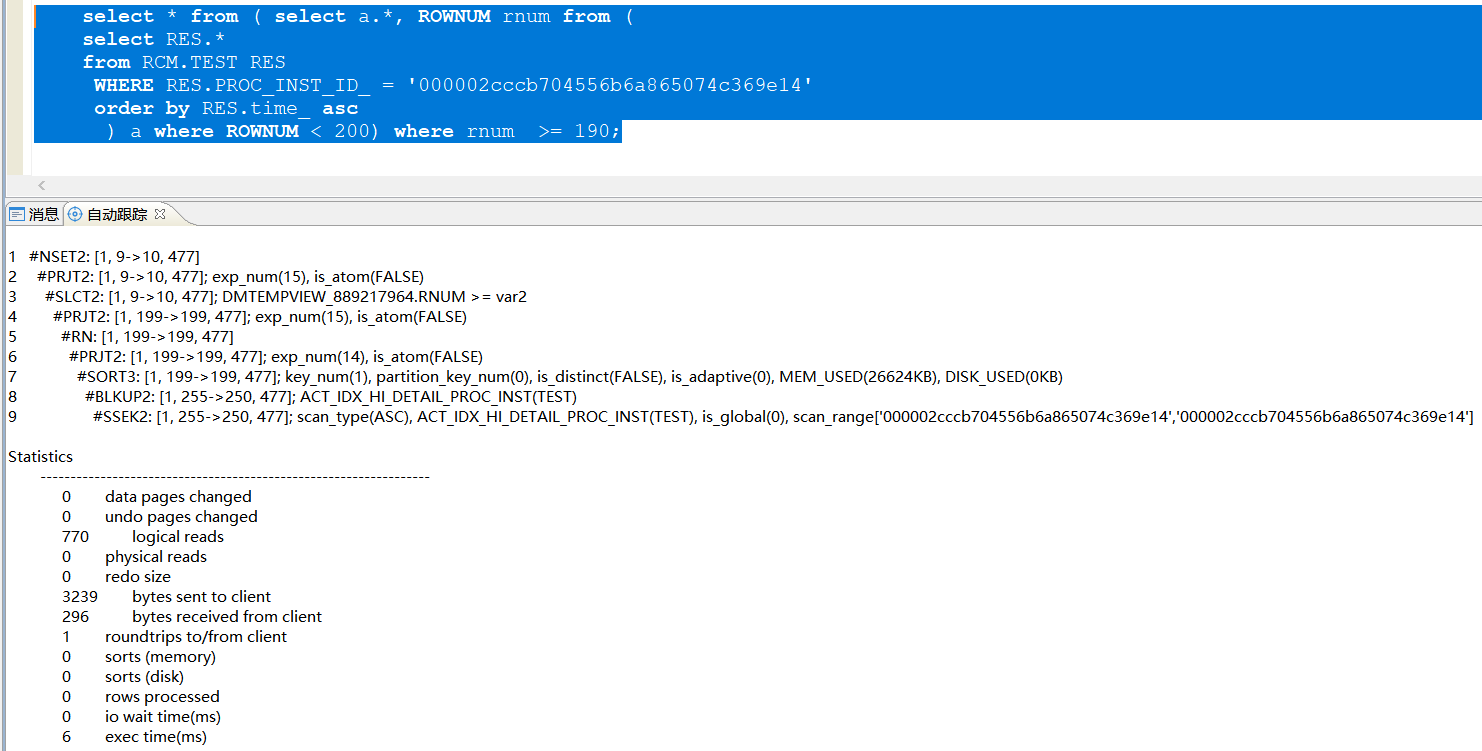
过滤排序分页之后很慢,通过hint 指定索引和 TOP_ORDER_OPT_FLAG(1)没效果。将 order by id_ asc排序改成order by time_ 执行也很快![]()
![]()
同样的sql跑到oracle执行时间毫秒级别,执行计划不会出现索引全扫描的情况。![]()
![]()
怀疑是数据库版本问题,换个新版本测试也一样情况。现采用如下两种方法进行优化
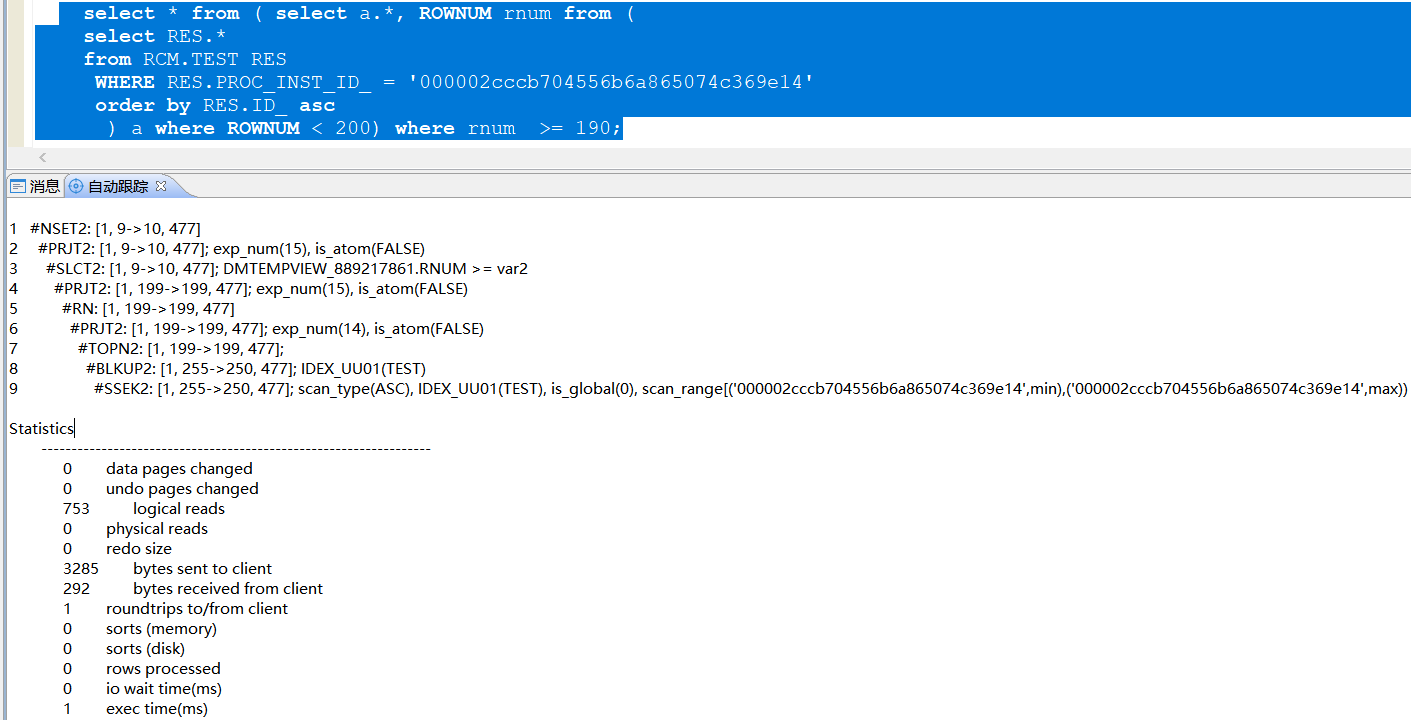
将分页查询框架改写之后,执行时间毫秒级别出结果
select * from (
select * from ( select a.*, ROWNUM rnum from (
select RES.*
from RCM.TEST RES
WHERE RES.PROC_INST_ID_ = '000002cccb704556b6a865074c369e14'
order by RES.ID_ asc
) a) where ROWNUM < 200) where rnum >= 190;

加组合索引,执行时间毫秒级别
create index idex_uu01 on TEST(PROC_INST_ID_,ID_ )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号