jieba库分词
(1)团队简介的词频统计
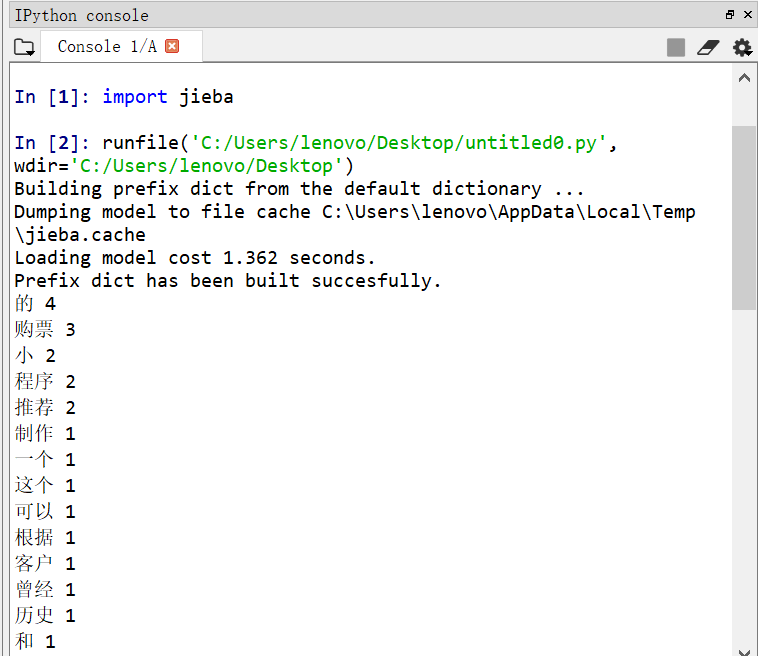
1 import jieba 2 import collections 3 s="制作一个购票小程序,这个购票小程序可以根据客户曾经的购票历史" 4 s+="和评分记录自动推荐用户感兴趣的内容以及热门的热点项" 5 s+="目,类似于大数据的推荐系统。" 6 s1=jieba.cut(s) 7 k=[] 8 l=['、',',','。',';','!'] 9 for i in s1: 10 if i not in l: 11 k.append(i) 12 count=collections.Counter(k) 13 for a,b in count.most_common(4): 14 print(a,b)
结果如下图所示:

(2)词频分布图
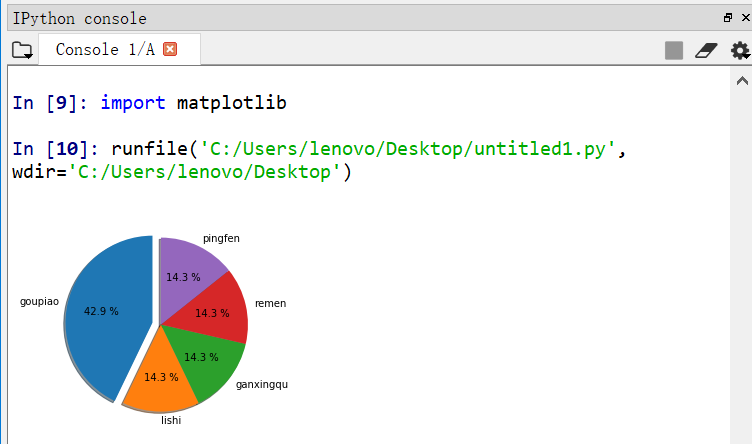
1 import numpy as np 2 import matplotlib.pyplot as plt 3 fracs = [3,1,1,1,1] 4 labels = 'goupiao', 'lishi', 'ganxingqu','remen','pingfen' 5 explode = [ 0.1,0,0,0,0] 6 plt.axes(aspect=1) 7 plt.pie(x=fracs, labels=labels, explode=explode,autopct='%3.1f %%', 8 shadow=True, labeldistance=1.1, startangle = 90,pctdistance = 0.6) 9 plt.show()
结果如下图所示:
(3)简介
制作一个购票小程序,该小程序可以根据客户曾经的购票历史和评分记录自动推荐用户感兴趣的内容以及热门的热点项目,类似于大数据的推荐系统。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号