
五、资源控制器
Pod 的分类
自主式 Pod:Pod 退出了,此类型的 Pod 不会被创建
控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
5.1 Kubernetes Pod 控制器
扩容和缩容
暂停和继续 Deployment
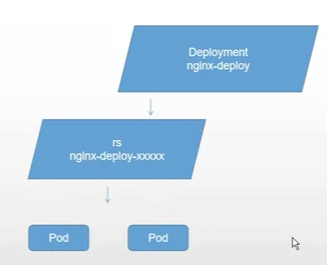
Deployment创建rs,rs创建、管理pod
DaemonSet
DaemonSet 确保全部(或者一些,根据调度策略或者污点定义)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod使用。
DaemonSet 的一些典型用法:
运行集群存储 daemon,例如在每个 Node 上运行 glusterd 、 ceph
在每个 Node 上运行日志收集 daemon,例如 fluentd 、 logstash
在每个 Node 上运行监控 daemon,例如 zabbix agent、Prometheus Node Exporter、 collectd 、Datadog 代理、New Relic 代理,或 Ganglia gmond
Job

Horizontal Pod Autoscaling
5.2 Kubernetes Deployment 控制器
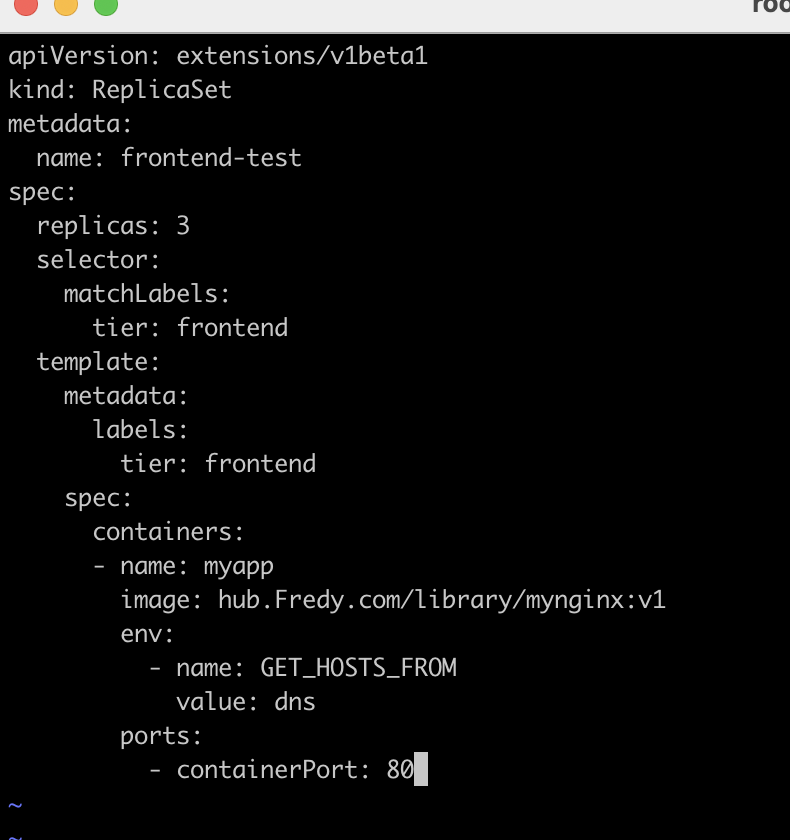
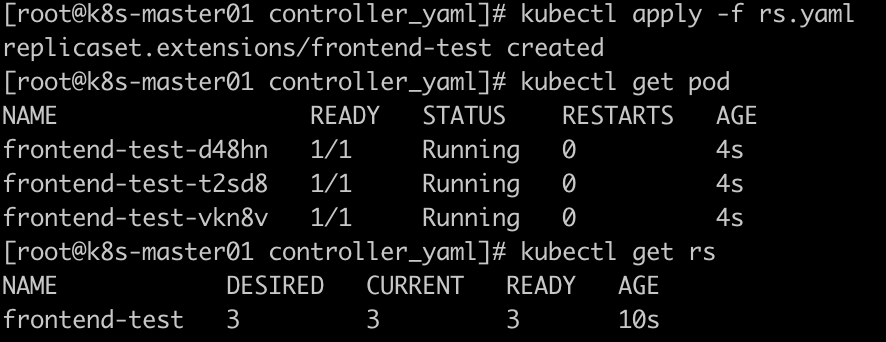
修改pod标签
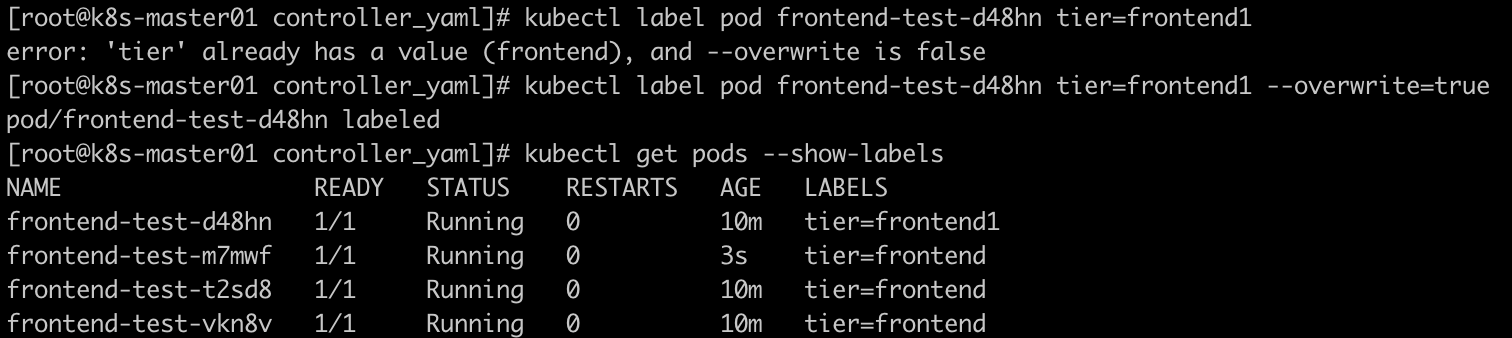
修改pod标签之后由于yaml文件中已经定义了pod的匹配标签,所以frontend标签会继续维持副本数目,添加一个新的pod
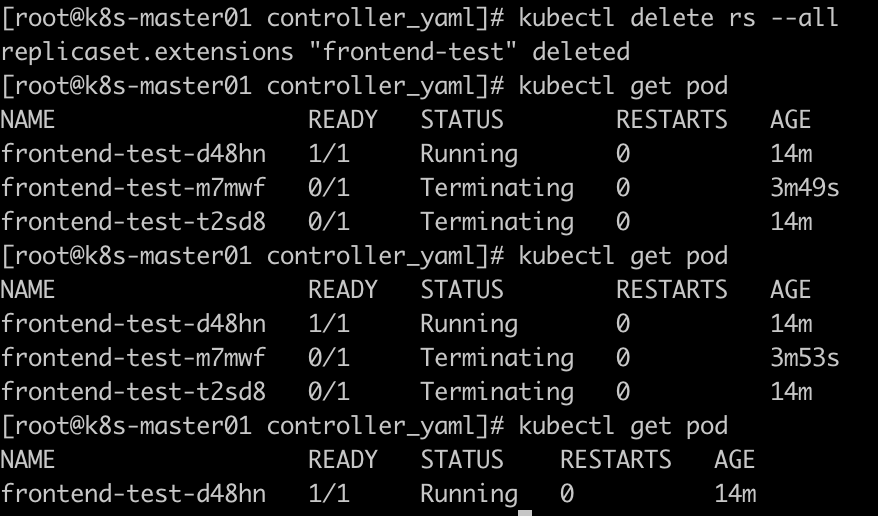
删除所有的rs,会删除所有由rs创建的pod,刚刚修改过标签之后的pod并不会被删除。
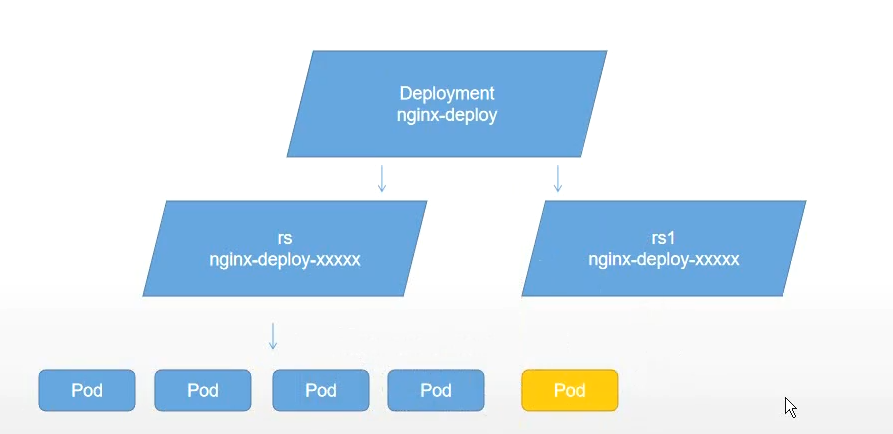
RS 与 Deployment 的关联
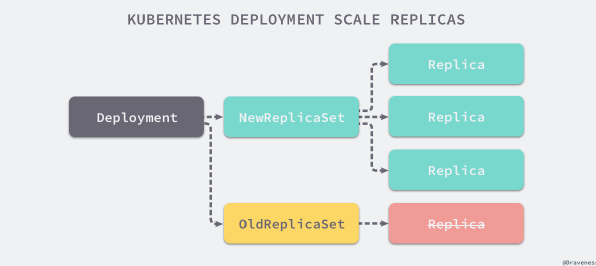
Deployment
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义(declarative)方法,用来替代以前的ReplicationController 来方便的管理应用。典型的应用场景包括:
定义Deployment来创建Pod和ReplicaSet
滚动升级和回滚应用
扩容和缩容
暂停和继续Deploymen
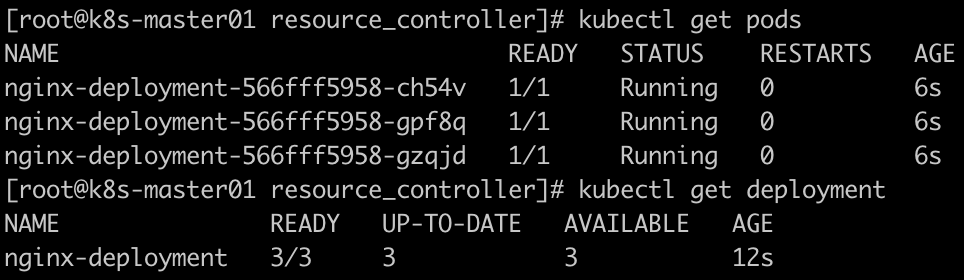
I、部署一个简单的 Nginx 应用

II、扩容副本数
kubectl scale deployment nginx-deployment --replicas=10
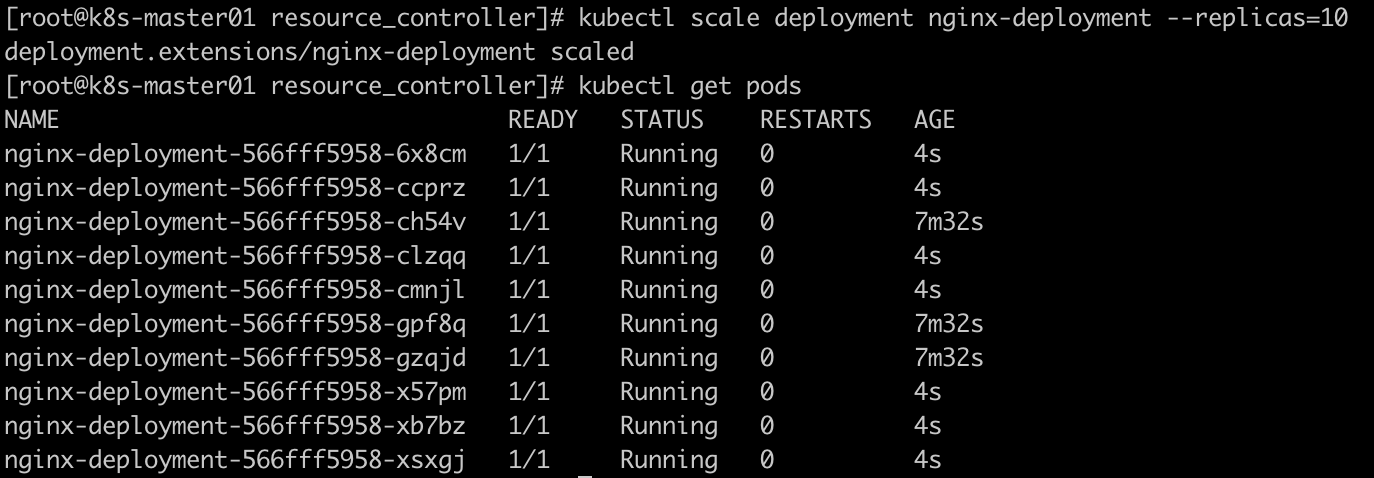
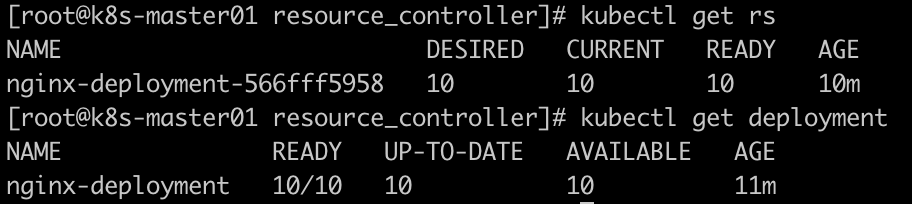
像nginx这种无状态服务扩容特别简单,名称未变,数目调整不会调整模板信息。
III、更新镜像:
kubectl set image deployment/nginx-deployment nginx=hub.Fredy.com/library/mynginx:v2
![]()
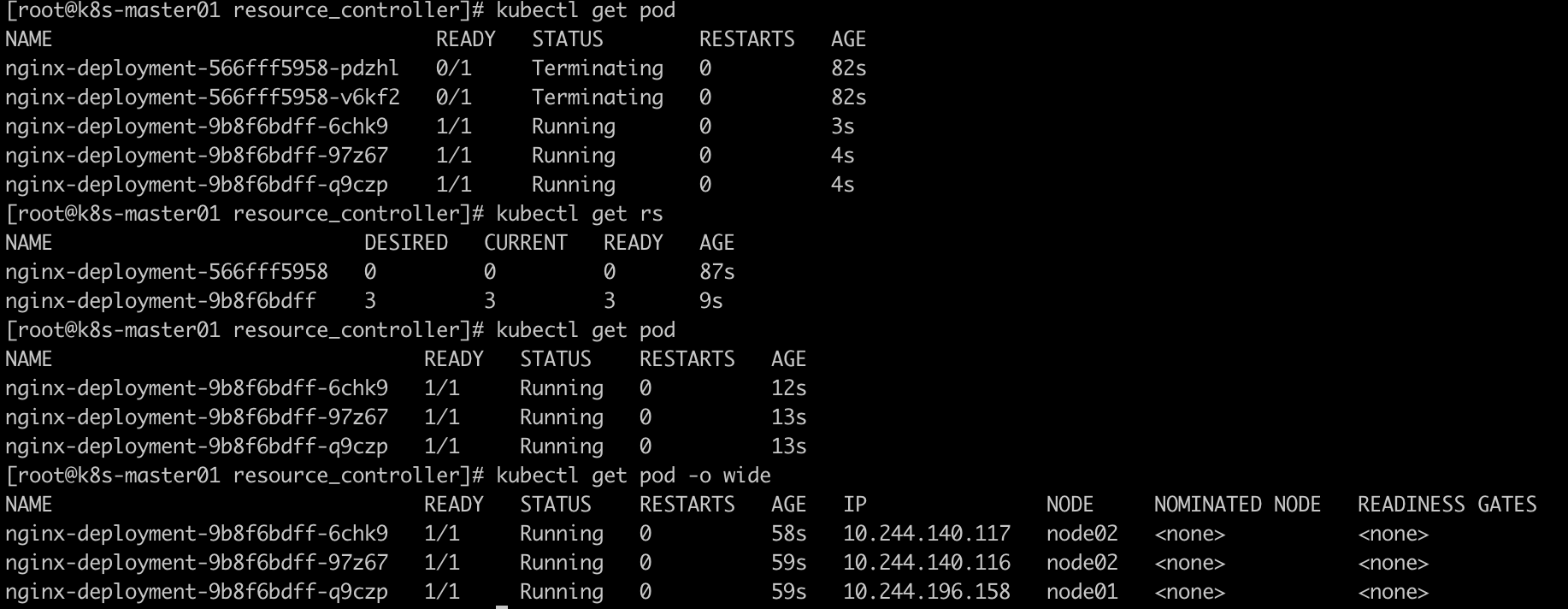
发现更新之后pod会陆续更新完成
IV、回滚:
kubectl rollout undo deployment/nginx-deployment


此时发现pod的启动镜像已经由刚刚的v2版本变为了v1版本。
kubectl rollout status deployment/nginx-deployment
查看回滚状态
![]()
V、如果集群支持 horizontal pod autoscaling 的话,还可以为Deployment设置自动扩展
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
Deployment 更新策略
Deployment 可以保证在升级时只有一定数量的 Pod 是 down 的。默认的,它会确保至少有比期望的Pod数量少一个是up状态(最多一个不可用)
Deployment 同时也可以确保只创建出超过期望数量的一定数量的 Pod。默认的,它会确保最多比期望的Pod数量多一个的 Pod 是 up 的(最多1个 surge )
未来的 Kuberentes 版本中,将从1-1变成25%-25% (无论数量多少,交替过程中每次操作25%的数量)
Rollover(多个rollout并行)
假如您创建了一个有5个 niginx:1.7.9 replica的 Deployment,但是当还只有3个 nginx:1.7.9 的 replica 创建出来的时候您就开始更新含有5个 nginx:1.9.1 replica 的 Deployment。在这种情况下,Deployment 会立即杀掉已创建的3个 nginx:1.7.9 的 Pod,并开始创建 nginx:1.9.1 的 Pod。它不会等到所有的5个 nginx:1.7.9 的Pod 都创建完成后才开始改变航道
回退 Deployment
kubectl set image deployment/nginx-deployment nginx=nginx:1.91 kubectl rollout status deployments nginx-deployment kubectl get pods kubectl rollout history deployment/nginx-deployment
清理 Policy
您可以通过设置 .spec.revisonHistoryLimit 项来指定 deployment 最多保留多少 revision 历史记录。默认的会保留所有的 revision;如果将该项设置为0,Deployment 就不允许回退了
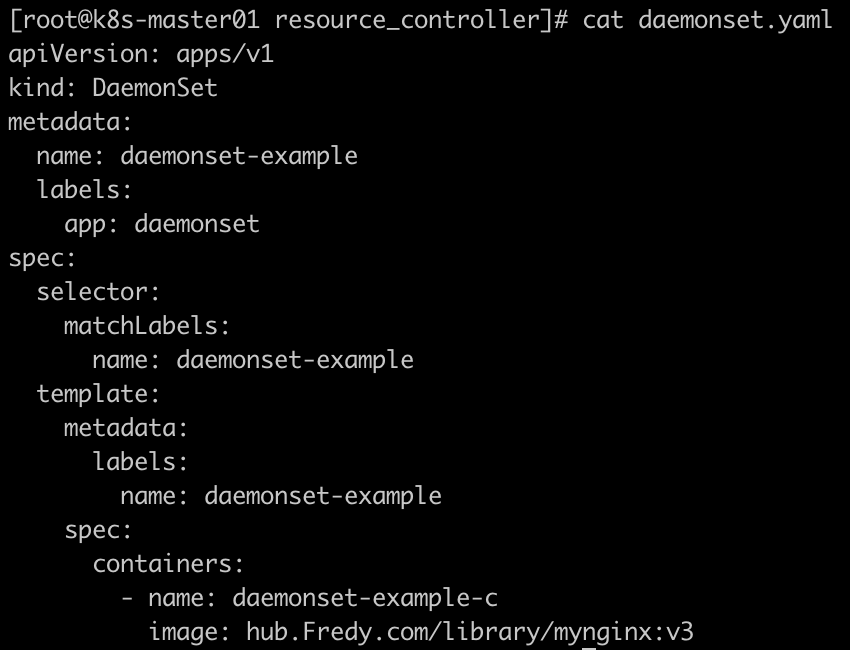
5.3 Kubernetes DaemonSet 控制器
什么是 DaemonSet
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
使用 DaemonSet 的一些典型用法:
运行集群存储 daemon,例如在每个 Node 上运行 glusterd 、 ceph
在每个 Node 上运行日志收集 daemon,例如 fluentd 、 logstash
在每个 Node 上运行监控 daemon,例如 Zabbix agent、 Prometheus Node Exporter、 collectd 、Datadog 代理、New Relic 代理,或 Ganglia gmond


5.4 Kubernetes JobCronJob 控制器
Job
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束
特殊说明:
spec.template格式同Pod
RestartPolicy仅支持Never或OnFailure
单个Pod时,默认Pod成功运行后Job即结束
.spec.completions 标志Job结束需要成功运行的Pod个数,默认为1
.spec.parallelism 标志并行运行的Pod的个数,默认为1
spec.activeDeadlineSeconds 标志失败Pod的重试最大时间,超过这个时间不会继续重试
vi job.yaml
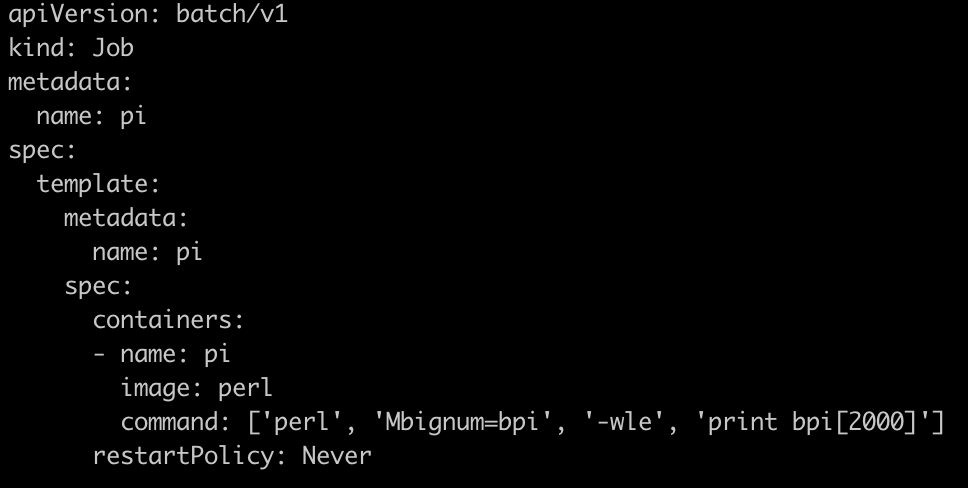

CronJob
Cron Job 管理基于时间的 Job,即:
在给定时间点只运行一次
周期性地在给定时间点运行
使用条件:当前使用的 Kubernetes 集群,版本 >= 1.8(对 CronJob)
典型的用法如下所示:
在给定的时间点调度 Job 运行
创建周期性运行的 Job,例如:数据库备份、发送邮件
CronJob Spec
.spec.schedule :调度,必需字段,指定任务运行周期,格式同 Cron
.spec.jobTemplate :Job 模板,必需字段,指定需要运行的任务,格式同 Job
.spec.startingDeadlineSeconds :启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限
.spec.concurrencyPolicy :并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。只允许指定下面策略中的一种:
Allow (默认):允许并发运行 Job
Forbid :禁止并发运行,如果前一个还没有完成,则直接跳过下一个
Replace :取消当前正在运行的 Job,用一个新的来替换
注意,当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总是允许并发运行。
.spec.suspend :挂起,该字段也是可选的。如果设置为 true ,后续所有执行都会被挂起。它对已经开始执行的 Job 不起作用。默认值为 false 。
.spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit :历史限制,是可选的字段。它们指定了可以保留多少完成和失败的 Job。默认情况下,它们分别设置为 3 和 1 。设置限制的值为 0 ,相关类型的 Job 完成后将不会被保留。
CrondJob 本身的一些限制
创建 Job 操作应该是幂等的

