基于Vision Transformer实现CIFAR-10分类问题
基于Vision Transformer实现CIFAR-10分类问题
结果
验证集上正确率为55-60。
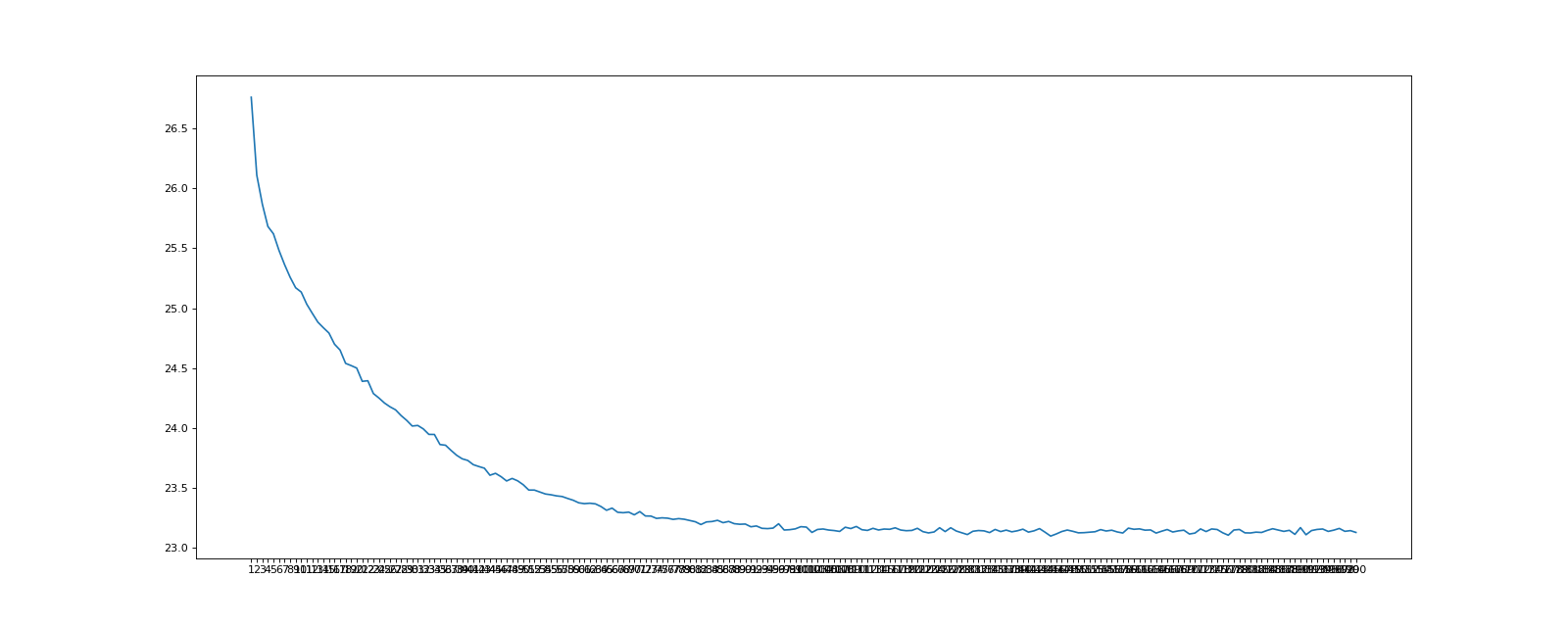
模型weight 正确率为46;
模型weight2 只保存了参数 模型更改 正确率大概在55-60(训练了200个epoch,效果最好);
模型weight3 正确率为51;
代码1
import copy
import math
import os
import time
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from torch.optim import SGD, lr_scheduler
# 超参数
Batch_size = 64 # 批处理
device = torch.device("cuda:0") # 使用GPU加速
EPOCH = 200
hidden_size = 768 # 隐藏层数
num_classes = 10 # 类别数
num_layers = 3 # Encoder Block 的个数
num_heads = 12 # 多头数
d_k = d_q = d_v = 64
mlp_size = 3072
# Patch Embedding
class PatchEmbedding(nn.Module):
def __init__(self, in_chans=3, patch_size=16, embed_dim=hidden_size):
super(PatchEmbedding, self).__init__()
self.conv = nn.Conv2d(in_channels=in_chans, out_channels=embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
# print(x.shape) # torch.Size([32, 3, 224, 224])
x = self.conv(x).flatten(2).transpose(1, 2)
# print(x.shape) # torch.Size([32, 64, 768])
return x
# MLP Block
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.ln = nn.LayerNorm(hidden_size, 1e-6)
self.fc1 = nn.Linear(hidden_size, mlp_size)
self.fc2 = nn.Linear(mlp_size, hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(0.3)
self.drop_path = DropPath(0.2)
def forward(self, x):
res = x
x = self.ln(x)
x = self.fc1(x)
x = self.gelu(x)
x = self.dropout(x)
x = self.fc2(x)
# x = self.dropout(x)
x = x + self.drop_path(x)
x = self.ln(res + x)
return x
# Multi-head attention
class MulitHeadAttention(nn.Module):
def __init__(self):
super(MulitHeadAttention, self).__init__()
self.ln = nn.LayerNorm(hidden_size, 1e-6)
self.w_q = nn.Linear(hidden_size, d_q * num_heads)
self.w_k = nn.Linear(hidden_size, d_k * num_heads)
self.w_v = nn.Linear(hidden_size, d_v * num_heads)
self.softmax = nn.Softmax(dim=-1)
self.drop_path = DropPath(0.2)
def forward(self, x):
res = x
n = x.shape[0]
# torch.Size([32, 197, 768])
query = self.w_q(x).view(n, -1, num_heads, d_q).transpose(1, 2) # query:torch.Size([32, 12, 197, 64])
key = self.w_k(x).view(n, -1, num_heads, d_k).transpose(1, 2)
value = self.w_v(x).view(n, -1, num_heads, d_v).transpose(1, 2)
# print(f"query:{query.shape}")
attn = torch.matmul(query, key.transpose(-1, -2)) # attn:torch.Size([32, 12, 197, 197])
attn = attn / math.sqrt(d_k)
attn = self.softmax(attn)
context = torch.matmul(attn, value)
context = context.transpose(1, 2).reshape(n, -1, hidden_size) # context:torch.Size([32, 197, 768])
context = context + self.drop_path(context)
x = self.ln(res + context)
# print(f"x:{x}")
return x
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
# shape (b, 1, 1, 1...)
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
# 向下取整用于确定保存哪些样本
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
# 除以keep_prob是为了保持训练和测试时期望一致
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
# Block
class Block(nn.Module):
def __init__(self):
super(Block, self).__init__()
self.mlp = MLP()
self.attn = MulitHeadAttention()
def forward(self, x):
x = self.attn(x)
x = self.mlp(x)
return x
# Transforms Encoder
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.layers = nn.ModuleList()
for _ in range(num_layers):
layer = Block()
self.layers.append(copy.deepcopy(layer))
self.ln = nn.LayerNorm(hidden_size, 1e-6)
def forward(self, x):
for layer_block in self.layers:
x = layer_block(x)
# print(f"x:{x.shape}")
# print(f"x2:{x.shape}")
encoder = self.ln(x)
return encoder
# Vision transforms
class VIT(nn.Module):
def __init__(self):
super(VIT, self).__init__()
self.PatchEmbedding = PatchEmbedding()
self.cls_token = nn.Parameter(torch.zeros(1, 1, hidden_size))
self.pos_emb = nn.Parameter(torch.zeros(1, 5, hidden_size)) # pos_emb:torch.Size([1, 197, 768])
self.encoder = Encoder()
self.fc = nn.Linear(hidden_size, num_classes)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
x = self.PatchEmbedding(x) # torch.Size([32, 64, 768])
# print(self.cls_token.shape)
cls_tokens = self.cls_token.expand(x.shape[0], -1, -1) # cls_token:torch.Size([32, 1, 768])
# print(f"cls_token:{cls_tokens.shape}")
x = torch.cat((cls_tokens, x), dim=1) # torch.Size([32, 197, 768])
# print(x.shape)
x = x + self.pos_emb # x:torch.Size([32, 197, 768])
# print(f"x:{x.shape}")
x = self.encoder(x)
x = x[:, 0]
x = self.fc(x)
x = self.softmax(x)
return x
def main():
trans_train = transforms.Compose([
# transforms.RandomResizedCrop(64),
transforms.RandomHorizontalFlip(),
transforms.RandomGrayscale(),
# transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_sets = datasets.CIFAR10(root='./data3', train=True, download=False, transform=trans_train)
train_loader = DataLoader(dataset=train_sets, batch_size=Batch_size, shuffle=True)
# print(len(train_loader)) 1563
# print(len(train_sets)) 50000
# model = VIT().to(device)
# model = VIT().to(device)
model = torch.load('./data3/model/weight4.pth')
# model.load_state_dict(torch.load('./data3/model/weight2.pth'))
# print(model)
# torch.nn.init.trunc_normal_(model,mean=0,std=1)
# optimizer = torch.optim.Adam(model.parameters(),lr=0.1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.99)
criterion = nn.CrossEntropyLoss().to(device)
best_loss = 100000
best_epoch = 1
# path_train = './data3/model'
path_train = os.path.join('./data3/model', 'weight.pth')
y_loss = []
x_table = []
lambda1 = lambda epoch: 0.95 ** epoch # 学习率 = 0.95**(轮数)
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
for epoch in range(EPOCH):
train_loss = 0.0
index = 1
correct = 0.0
num = 0
start = time.time()
ha = 1
for x, y in train_loader:
# x : torch.Size([32, 3, 224, 224])
x = x.to(device)
y = y.to(device)
y_pre = model(x)
loss = criterion(y_pre, y) / len(x)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
correct += torch.sum(torch.argmax(y_pre, dim=1) == y).item()
num += len(x)
fang = 100 * index / 1563
if ha >= 10000:
# print(f"Test accuracy: {correct / total * 100:.5f}%")
ha = 1
print(' index:', '%.2f' % fang, 'loss:', '{:.6f}'.format(loss.item()), 'accuracy:',
'%.3f' % (100 * correct / num), f'correct:{correct},sum:{num}')
index += 1
ha += len(x)
# break
end = time.time()
scheduler.step()
y_loss.append(train_loss)
x_table.append(epoch + 1)
# print(f"y_pre:{y_pre}")
# break
if train_loss < best_loss:
best_loss = train_loss
best_epoch = epoch
# best_model_wts = copy.deepcopy(model.state_dict())
torch.save(model, path_train)
print(f"更新模型{epoch}")
print('Epoch:', '%06d' % (epoch + 1), 'loss =', '{:.6f}'.format(train_loss),
f'correct:{100 * correct / num:.2f}%', f'time:{end - start:.2f}s',
f"lr:{optimizer.state_dict()['param_groups'][0]['lr']}")
print('best_loss::|', best_loss, '---best_epoch::|', best_epoch)
fig = plt.figure(figsize=(20, 8), dpi=80)
plt.plot(x_table, y_loss)
plt.xticks(x_table)
plt.savefig("./data3/png/loss.png")
# return model
def vaild():
# model = fang
model = torch.load('./data3/model/weight3.pth')
# model = VIT().to(device)
# model.load_state_dict(torch.load('./data3/model/weight2.pth'))
# print(model)
# model.torch.load('./model/weight1.pth')
trans_vaild = transforms.Compose([
# transforms.Resize(256),
# transforms.RandomResizedCrop(64),
# transforms.RandomHorizontalFlip(),
# transforms.RandomGrayscale(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
vaild_sets = datasets.CIFAR10(root='./data3', train=False, download=False, transform=trans_vaild)
vaild_loader = DataLoader(dataset=vaild_sets, batch_size=Batch_size, shuffle=False)
criterion = nn.CrossEntropyLoss()
total = 0.0
correct = 0.0
vaild_loss = 0.0
correct_rate = 0.0
for x, y in vaild_loader:
x = x.to(device)
y = y.to(device)
y_pre = model(x)
# print(y_pre.shape)
loss = criterion(y_pre, y) / len(x)
# print(loss.item())
correct += torch.sum(torch.argmax(y_pre, dim=1) == y).item()
total += len(x)
vaild_loss += loss.item()
correct_rate = 100 * correct / total
print(f"验证ing,正确数:{correct},验证总数:{total},正确率:{correct_rate:.3f}%,loss:{vaild_loss:.5f}")
# break
print(f"验证结束,正确数:{correct},验证总数:{total},正确率:{correct_rate:.3f}%,loss:{vaild_loss:.5f}")
# print(model)
pass
if __name__ == '__main__':
# main()
vaild()
代码2
import copy
import math
import os
import time
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from torch.optim import SGD, lr_scheduler
# 超参数
Batch_size = 64 # 批处理
device = torch.device("cuda:0") # 使用GPU加速
EPOCH = 10
hidden_size = 768 # 隐藏层数
num_classes = 10 # 类别数
num_layers = 1 # Encoder Block 的个数
num_heads = 12 # 多头数
d_k = d_q = d_v = 64
mlp_size = 3072
path_train = os.path.join('../dataset/VIT_CIFAR10/model', 'weight.pth') # 模型保存地址
d_2 = 9
data_path = '../dataset/VIT_CIFAR10/data'
load_model_path = '../model/cnn_vit.pth'
class CNN(nn.Module):
# torch.Size([32, 3, 224, 224]) ===> torch.Size([64, 4, 768])
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5)
self.pool = nn.MaxPool2d(2, 2)
self.Conv2 = nn.Conv2d(6, hidden_size, 16,16)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.Conv2(x))).flatten(2).transpose(1, 2)
# sdf torch.Size([32, 6, 110, 110])
# print("sdf", x.shape)
return x
# Patch Embedding
class PatchEmbedding(nn.Module):
def __init__(self, in_chans=3, patch_size=16, embed_dim=hidden_size):
super(PatchEmbedding, self).__init__()
self.conv = nn.Conv2d(in_channels=in_chans, out_channels=embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
# print(x.shape) # torch.Size([32, 3, 224, 224])
x = self.conv(x).flatten(2).transpose(1, 2)
# print(x.shape) # torch.Size([32, 64, 768])
return x
# MLP Block
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.ln = nn.LayerNorm(hidden_size, 1e-6)
self.fc1 = nn.Linear(hidden_size, mlp_size)
self.fc2 = nn.Linear(mlp_size, hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(0.3)
self.drop_path = DropPath(0.2)
def forward(self, x):
res = x
x = self.ln(x)
x = self.fc1(x)
x = self.gelu(x)
x = self.dropout(x)
x = self.fc2(x)
# x = self.dropout(x)
x = x + self.drop_path(x)
x = self.ln(res + x)
return x
# Multi-head attention
class MulitHeadAttention(nn.Module):
def __init__(self):
super(MulitHeadAttention, self).__init__()
self.ln = nn.LayerNorm(hidden_size, 1e-6)
self.w_q = nn.Linear(hidden_size, d_q * num_heads)
self.w_k = nn.Linear(hidden_size, d_k * num_heads)
self.w_v = nn.Linear(hidden_size, d_v * num_heads)
self.softmax = nn.Softmax(dim=-1)
self.drop_path = DropPath(0.2)
def forward(self, x):
res = x
n = x.shape[0]
# torch.Size([32, 197, 768])
query = self.w_q(x).view(n, -1, num_heads, d_q).transpose(1, 2) # query:torch.Size([32, 12, 197, 64])
key = self.w_k(x).view(n, -1, num_heads, d_k).transpose(1, 2)
value = self.w_v(x).view(n, -1, num_heads, d_v).transpose(1, 2)
# print(f"query:{query.shape}")
attn = torch.matmul(query, key.transpose(-1, -2)) # attn:torch.Size([32, 12, 197, 197])
attn = attn / math.sqrt(d_k)
attn = self.softmax(attn)
context = torch.matmul(attn, value)
context = context.transpose(1, 2).reshape(n, -1, hidden_size) # context:torch.Size([32, 197, 768])
context = context + self.drop_path(context)
x = self.ln(res + context)
# print(f"x:{x}")
return x
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
# shape (b, 1, 1, 1...)
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
# 向下取整用于确定保存哪些样本
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
# 除以keep_prob是为了保持训练和测试时期望一致
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
# Block
class Block(nn.Module):
def __init__(self):
super(Block, self).__init__()
self.mlp = MLP()
self.attn = MulitHeadAttention()
def forward(self, x):
x = self.attn(x)
x = self.mlp(x)
return x
# Transforms Encoder
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.layers = nn.ModuleList()
for _ in range(num_layers):
layer = Block()
self.layers.append(copy.deepcopy(layer))
self.ln = nn.LayerNorm(hidden_size, 1e-6)
def forward(self, x):
for layer_block in self.layers:
x = layer_block(x)
# print(f"x:{x.shape}")
# print(f"x2:{x.shape}")
encoder = self.ln(x)
return encoder
# Vision transforms
class VIT(nn.Module):
def __init__(self):
super(VIT, self).__init__()
# self.PatchEmbedding = PatchEmbedding()
self.PatchEmbedding = CNN()
self.cls_token = nn.Parameter(torch.zeros(1, 1, hidden_size))
self.pos_emb = nn.Parameter(torch.zeros(1, d_2+1, hidden_size)) # pos_emb:torch.Size([1, 197, 768])
self.encoder = Encoder()
self.fc = nn.Linear(hidden_size, num_classes)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
x = self.PatchEmbedding(x) # torch.Size([32, 4, 768])
# print(x.shape)
# return x
# print(x.shape)
# print(self.cls_token.shape)
cls_tokens = self.cls_token.expand(x.shape[0], -1, -1) # cls_token:torch.Size([32, 1, 768])
# print(f"cls_token:{cls_tokens.shape}")
x = torch.cat((cls_tokens, x), dim=1) # torch.Size([32, 197, 768])
# print(x.shape)
x = x + self.pos_emb # x:torch.Size([32, 197, 768])
# print(f"x:{x.shape}")
x = self.encoder(x)
x = x[:, 0]
x = self.fc(x)
x = self.softmax(x)
return x
def main():
trans_train = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.RandomGrayscale(),
# transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_sets = datasets.CIFAR10(root=data_path, train=True, download=True, transform=trans_train)
train_loader = DataLoader(dataset=train_sets, batch_size=Batch_size, shuffle=True)
# print(len(train_loader)) 1563
# print(len(train_sets)) 50000
# model = VIT().to(device)
# model = VIT().to(device)
model = torch.load(load_model_path)
# model.load_state_dict(torch.load('./data3/model/weight2.pth'))
# print(model)
# torch.nn.init.trunc_normal_(model,mean=0,std=1)
# optimizer = torch.optim.Adam(model.parameters(),lr=0.0002620450591493622)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.99)
criterion = nn.CrossEntropyLoss().to(device)
best_loss = 100000
best_epoch = 1
# path_train = './data3/model'
y_loss = []
x_table = []
lambda1 = lambda epoch: 0.95 ** epoch # 学习率 = 0.95**(轮数)
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
for epoch in range(EPOCH):
train_loss = 0.0
index = 1
correct = 0.0
num = 0
start = time.time()
ha = 1
for x, y in train_loader:
# x : torch.Size([32, 3, 224, 224])
x = x.to(device)
y = y.to(device)
y_pre = model(x)
loss = criterion(y_pre, y) / len(x)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
correct += torch.sum(torch.argmax(y_pre, dim=1) == y).item()
num += len(x)
fang = 100 * index / 1563
if ha >= 10000:
# print(f"Test accuracy: {correct / total * 100:.5f}%")
ha = 1
print(' index:', '%.2f' % fang, 'loss:', '{:.6f}'.format(loss.item()), 'accuracy:',
'%.3f' % (100 * correct / num), f'correct:{correct},sum:{num}')
index += 1
ha += len(x)
# break
end = time.time()
scheduler.step()
y_loss.append(train_loss)
x_table.append(epoch + 1)
# print(f"y_pre:{y_pre}")
# break
if train_loss < best_loss:
best_loss = train_loss
best_epoch = epoch
# best_model_wts = copy.deepcopy(model.state_dict())
torch.save(model, path_train)
print(f"更新模型{epoch}")
print('Epoch:', '%06d' % (epoch + 1), 'loss =', '{:.6f}'.format(train_loss),
f'correct:{100 * correct / num:.2f}%', f'time:{end - start:.2f}s',
f"lr:{optimizer.state_dict()['param_groups'][0]['lr']}")
print('best_loss::|', best_loss, '---best_epoch::|', best_epoch)
fig = plt.figure(figsize=(20, 8), dpi=80)
plt.plot(x_table, y_loss)
plt.xticks(x_table)
plt.savefig("../dataset/VIT_CIFAR10/png/loss.png")
# return model
def vaild():
# model = fang
model = VIT().to(device)
# model.load_state_dict(torch.load('./data3/model/weight2.pth'))
# print(model)
# model.torch.load('./model/weight1.pth')
trans_vaild = transforms.Compose([
# transforms.Resize(256),
# transforms.RandomResizedCrop(64),
# transforms.RandomHorizontalFlip(),
# transforms.RandomGrayscale(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
vaild_sets = datasets.CIFAR10(root='./dataset/VIT_CIFAR10/data', train=False, download=True, transform=trans_vaild)
vaild_loader = DataLoader(dataset=vaild_sets, batch_size=Batch_size, shuffle=False)
criterion = nn.CrossEntropyLoss()
total = 0.0
correct = 0.0
vaild_loss = 0.0
correct_rate = 0.0
for x, y in vaild_loader:
x = x.to(device)
y = y.to(device)
y_pre = model(x)
# print(y_pre.shape)
loss = criterion(y_pre, y) / len(x)
# print(loss.item())
correct += torch.sum(torch.argmax(y_pre, dim=1) == y).item()
total += len(x)
vaild_loss += loss.item()
correct_rate = 100 * correct / total
print(f"验证ing,正确数:{correct},验证总数:{total},正确率:{correct_rate:.3f}%,loss:{vaild_loss:.5f}")
# break
print(f"验证结束,正确数:{correct},验证总数:{total},正确率:{correct_rate:.3f}%,loss:{vaild_loss:.5f}")
# print(model)
pass
if __name__ == '__main__':
main()
# vaild()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号