基于Vision Transformer训练花分类数据集
基于Vision Transformer训练花分类数据集
数据预处理
由于数据集没有分训练集和测试集,所以我们需要自行划分训练集、验证集。训练集和测试集的划分有多种方法,这里我们使用留出法,选取比例定为7:3。
该数据集一共有5种类别的花,分别为:daisy、dandelion、roses、sunflowers和tulips(雏菊、蒲公英、玫瑰、向日葵和郁金香)。
def pre_data():
photos_path = './../datasets/flower_photos'
files = os.listdir(photos_path)
print(files)
for i in range(len(files)):
class_path = photos_path +'/' + files[i]
# print(class_path)
flower_file = os.listdir(class_path)
flower_num = len(flower_file)
new_train_path = './../datasets/flowers/train/' + files[i]
new_val_path = './../datasets/flowers/validation/' + files[i]
print(new_train_path,new_val_path)
if not os.path.exists(new_train_path):
os.makedirs(new_train_path)
if not os.path.exists(new_val_path):
os.makedirs(new_val_path)
for j in range(flower_num):
if(j <= flower_num * 0.7):
old_file_path = class_path + '/' + flower_file[j]
new_file_path = new_train_path + '/' + flower_file[j]
shutil.copy(old_file_path,new_file_path)
print(old_file_path,new_file_path)
else:
old_file_path = class_path + '/' + flower_file[j]
new_file_path = new_val_path + '/' + flower_file[j]
shutil.copy(old_file_path,new_file_path)
print(old_file_path, new_file_path)
超参数定义
# 花的类别
class_flowers = ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
flowers_sum = 3670
# 训练集 路径
train_path = './../datasets/flowers/train/'
# 验证集 路径
val_path = './../datasets/flowers/validation/'
# GPU 加速
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 多头数
n_heads = 8
# q , k , v 的维数
d_q = d_k = d_v = 96
d_model = 768
n_layers = 2
batch_size = 32
class_flowers_num = 5
N_EPOCHS = 100
数据加载
但是这次的 花分类数据集 并不在 pytorch 的 torchvision.datasets. 中,因此需要用到datasets.ImageFolder() 来导入。
ImageFolder()返回的对象是一个包含数据集所有图像及对应标签构成的二维元组容器,支持索引和迭代,可作为torch.utils.data.DataLoader的输入。
代码如下:
# 图像预处理
data_transform = {
"train":transforms.Compose([
transforms.RandomRotation(45),# 随机旋转 -45度到45度之间
transforms.CenterCrop(224),# 从中间处开始裁剪
transforms.RandomHorizontalFlip(p = 0.5),# 随机水平旋转
transforms.RandomVerticalFlip(p = 0.5),# 随机垂直旋转
# 参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.ColorJitter(brightness= 0.2,contrast=0.1,saturation=0.1,hue=0.1),
transforms.RandomGrayscale(p=0.025),# 概率转换为灰度图,三通道RGB
# 灰度图转换以后也是三个通道,但是只是RGB是一样的
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
# resize成256 * 256 再选取 中心 224 * 224,然后转化为向量,最后正则化
"val": transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
# 均值和标准差和训练集相同
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
train_dataset = datasets.ImageFolder(root=train_path,transform=data_transform['train'])
val_dataset = datasets.ImageFolder(root=val_path,transform=data_transform['val'])
train_num = len(train_dataset)
val_num = len(val_dataset)
train_loader = DataLoader(train_dataset,batch_size=32,shuffle=True,num_workers=0)
val_loader = DataLoader(val_dataset,batch_size=32,shuffle=True,num_workers=0)
# {'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflowers': 3, 'tulips': 4}
flower_list = train_dataset.class_to_idx
# {0: 'daisy', 1: 'dandelion', 2: 'roses', 3: 'sunflowers', 4: 'tulips'}
cal_dict = dict((val,key) for key ,val in flower_list.items())
根据正余弦获取位置编码
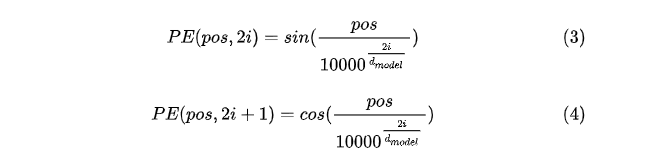
公式解释:pos表示单词在句子中的位置;dmodel表示词向量的维度;2i和2i+1表示奇偶性。至于上面公式怎么得到的,其实不重要。
def get_positional_embeddings(sequence_length,d):
result = torch.ones(sequence_length,d)
for i in range(sequence_length):
for j in range(d):
result[i][j] = np.sin(i/(10000**(j/d))) if j %2==0 else np.cos(i/(10000**((j-1)/d)))
return result
封装点积运算
"""
封装点积运算
需要传入Q,K,V三个矩阵
将三个矩阵按照公式计算出Attention
"""
class scaledDotProductAttention(nn.Module):
def __init__(self):
super(scaledDotProductAttention, self).__init__()
def forward(self,Q,K,V):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
DropPath操作
"""
封装DropPath操作
DropPath:将深度学习模型中的多分支结构随机失效
Dropout:将神经元随机失效
在这里DropPath实际就是对一个batch中随机选择一定数量的sample,将其特征值变为0
"""
def drop_path(x,drop_prob:float = 0.,training:bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
# print("x.shape:",x.shape)
# print("shape:",shape)
# print("keep_prob:",keep_prob)
random_tensor = keep_prob + torch.rand(shape,dtype=x.dtype,device=device)
# print("random_tensor:",random_tensor)
random_tensor.floor_()
output = x.div(keep_prob) * random_tensor
# print("output:",output.shape)
return output
class DropPath(nn.Module):
# drop_prob 有啥作用 这里我随便填的0.1
def __init__(self,drop_prob = 0.1):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self,x):
return drop_path(x,self.drop_prob,self.training)
Multi-Head Attention操作
"""
Multi-Head Attention实现
利用nn.Linear实现得到矩阵QKV
需要传入input_q,input_k,input_v
经过点积运算得到Attention权重之和
最后需要再经过一层全连接层 实现将维数转成起初的维数
最后经过LayerNorm函数
"""
class Multi_Head_Attention(nn.Module):
def __init__(self):
super(Multi_Head_Attention, self).__init__()
self.W_Q = nn.Linear(d_model,d_q * n_heads)
self.W_K = nn.Linear(d_model,d_k * n_heads)
self.W_V = nn.Linear(d_model,d_v * n_heads)
self.fc = nn.Linear(d_k*n_heads,d_model)
self.drop_path = DropPath()
def forward(self,input_q,input_k,input_v):
residual, batch_size = input_q, input_q.size(0)
Q = self.W_Q(input_q).view(batch_size,-1,n_heads,d_q).transpose(1,2)
K = self.W_K(input_k).view(batch_size,-1,n_heads,d_k).transpose(1,2)
V = self.W_V(input_v).view(batch_size,-1,n_heads,d_v).transpose(1,2)
# context: torch.Size([32, 8, 197, 96]) (batch_size,n_heads,197,d_k)
context,attn = scaledDotProductAttention()(Q,K,V)
# print(context.shape)
context = context.transpose(1,2).reshape(batch_size, -1 ,d_model)
# context: torch.Size([32, 197, 768])
context = self.fc(context)
# print("context1:",context)
# 在此加入DropPath处理
context1 = context
context = self.drop_path(context)
# print(context1.equal(context))
# print("context2:",context)
# context: torch.Size([32, 197, 768])
# 残差块处理 解决神经网络退化问题
return nn.LayerNorm(d_model).cuda(device)(context + residual),attn
MLP-Block操作
class MLP_Block(nn.Module):
def __init__(self):
super(MLP_Block, self).__init__()
self.fc1 = nn.Linear(d_model,4*d_model).cuda(device)
self.gelu = nn.GELU()
self.dropout = nn.Dropout()
self.fc2 = nn.Linear(4*d_model,d_model).cuda(device)
self.drop_path = DropPath()
def forward(self,x):
# x = x.to(device)
x = self.fc1(x)
x = self.gelu(x)
x = self.dropout(x)
# print(x)
x = self.fc2(x)
x = self.dropout(x)
x = self.drop_path(x)
return x
MyVIT_Layer
# torch.Size([32, 3, 224, 224])
class MyViT_Layer(nn.Module):
"""
input_shape : [32,3,224,224]
n_patches : 表示将图片分成n_patches*n_patches块子图片
hidden_d :
n_head : 表示多头注意力的头数
out_d : 表示最后输出的维度 这里为5 表示有5种类别的花
"""
def __init__(self,):
super(MyViT_Layer, self).__init__()
# 经过一层 Norm层 目的是为标准化 加快收敛
self.LN1 = nn.LayerNorm(d_model).cuda(device)
# 经过Multi-Head Attention层 同时会进行残差处理
self.MultiHead = Multi_Head_Attention()
# 再经过一层LN层
self.LN2 = nn.LayerNorm(d_model).cuda(device)
# 再经过一层MLP_Block层
self.MLP_Block = MLP_Block()
def forward(self,x):
n = x.shape[0]
token = x # [n,196,768]
# print(token.shape)
# 添加Class Token
# token = torch.stack([torch.vstack((class_token, token[i])) for i in range(len(token))]) # [32, 196, 768] --> [32, 197, 768]
# 添加第一个LN层
token = self.LN1(token)
context,attn = self.MultiHead(token,token,token)
residual = context
# 添加第二个LN层
context = self.LN2(context)
# 添加MLP_Block层
# context = context.to(device)
context = self.MLP_Block(context)
context = nn.LayerNorm(d_model).cuda(device)(context + residual)
#transforms Encoder 部分
# print("context:",context.shape)
return context
MyViT
class MyViT(nn.Module):
def __init__(self,input_shape,n_patches=14,hidden_d=768):
super(MyViT, self).__init__()
self.input_shape = input_shape
self.patch = (input_shape[1] / n_patches, input_shape[2] / n_patches) # self.patch : [16,16]
self.n_patchs = n_patches
self.input_d = int(self.input_shape[0] * self.patch[0] * self.patch[1])
self.hidden_d = hidden_d
self.class_token = nn.Parameter(torch.rand(1, self.hidden_d))
self.get_position_emb = nn.Embedding.from_pretrained(get_sinusoid_encodingg_table(197,d_model),freeze=True)
self.myvit = nn.ModuleList([MyViT_Layer() for _ in range(n_layers)])
self.mlp_head = nn.Sequential(
nn.Linear(d_model,class_flowers_num),
nn.Softmax(dim=-1)
)
def forward(self,x):
n = x.shape[0]
# print("n:", n)
x = x.reshape(n, self.n_patchs ** 2, self.input_d)
x = torch.stack(
[torch.vstack((self.class_token, x[i])) for i in range(len(x))]) # [32, 196, 768] --> [32, 197, 768]
i = 1
# 添加位置编码
# print(f"input_d:{self.input_d} x:{self.n_patchs**2 + 1}")
# posit_emb = self.get_position_emb(x).to(device)
# print("posit_emb:",posit_emb.shape)
x += get_positional_embeddings(self.n_patchs ** 2 + 1, self.input_d).repeat(n, 1, 1).to(device)
for layer in self.myvit:
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
x = layer(x)
# print(i)
i+=1
x = x[:,0]
x = self.mlp_head(x)
return x
优化器&损失函数
model = MyViT((3,224,224),).to(device)
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
optimizer = torch.optim.Adam(model.parameters(),lr=0.01)
criterion = nn.CrossEntropyLoss().to(device)
训练
for epoch in range(N_EPOCHS):
train_loss = 0.0
now_index = 1
sum_num = int(flowers_sum/batch_size)
for img_batch,label_batch in train_loader:
img_batch = img_batch.to(device)
label_batch = label_batch.to(device)
y_pre = model(img_batch)
loss = criterion(y_pre,label_batch)/len(img_batch)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"epoch:{epoch} loss: {loss.item():.5f} 当前进度参考: {now_index}/{sum_num}")
now_index += 1
# break
# break
try:
print(f"Epoch {epoch + 1}/{N_EPOCHS} loss: {train_loss:.5f}")
with open(file="./train.txt",mode='a',encoding='UTF-8') as file_obj:
file_obj.write(f"Epoch {epoch + 1}/{N_EPOCHS} loss: {train_loss:.5f}\n")
except Exception:
print("asdf")
测试
test_loss = 0.0
correct = 0.0
total = 0.0
for img_batch,label_batch in val_loader:
img_batch = img_batch.to(device)
label_batch = label_batch.to(device)
y_pre = model(img_batch)
loss = criterion(y_pre,label_batch)/len(img_batch)
test_loss += loss.item()
# print(y_pre.shape)
correct += torch.sum(torch.argmax(y_pre,dim=1) == label_batch).item()
total += len(img_batch)
print(f"验证ing,正确数:{correct},验证总数:{total}")
# print(correct)
# break
try:
print(f"Test loss: {test_loss:.5f}")
print(f"Test accuracy: {correct / total * 100:.5f}%")
with open(file="./train.txt", mode='a', encoding='UTF-8') as file_obj:
file_obj.write(f"Test accuracy: {correct / total * 100:.5f}%\n")
except Exception:
print("asdf")
结果
训练了100个epoch,最后的验证的正确率只能达到30%左右。分析每一个EPOCH,发现其loss都在4.3左右徘徊,模型欠拟合。
查阅一些资料后了解到,训练集Loss不下降一般由这几个方面导致:
- 模型结构和特征工程存在问题
如果一个模型的结构有问题,那么它就很难训练,通常,自己“自主研发”设计的网络结构可能很难适应实际问题,通过参考别人已经设计好并实现和测试过的结构,以及特征工程方案,进行改进和适应性修改,可以更快更好的完成目标任务。当模型结构不好或者规模太小、特征工程存在问题时,其对于数据的拟合能力不足,是很多人在进行一个新的研究或者工程应用时,遇到的第一个大问题。
- 权重初始化方案有问题
神经网络在训练之前,我们需要给其赋予一个初值,但是如何选择这个初始值,则要参考相关文献资料,选择一个最合适的初始化方案。常用的初始化方案有全零初始化、随机正态分布初始化和随机均匀分布初始化等。合适的初始化方案很重要,用对了,事半功倍,用不对,模型训练状况不忍直视。博主之前训练一个模型,初始化方案不对,训练半天都训练不动,loss值迟迟居高不下,最后改了初始化方案,loss值就如断崖式下降。
- 正则化过度
L1 L2和Dropout是防止过拟合用的,当训练集loss下不来时,就要考虑一下是不是正则化过度,导致模型欠拟合了。一般在刚开始是不需要加正则化的,过拟合后,再根据训练情况进行调整。如果一开始就正则化,那么就难以确定当前的模型结构设计是否正确了,而且调试起来也更加困难。
- 选择合适的激活函数、损失函数
不仅仅是初始化,在神经网络的激活函数、损失函数方面的选取,也是需要根据任务类型,选取最合适的。
比如,卷积神经网络中,卷积层的输出,一般使用ReLu作为激活函数,因为可以有效避免梯度消失,并且线性函数在计算性能上面更加有优势。而循环神经网络中的循环层一般为tanh,或者ReLu,全连接层也多用ReLu,只有在神经网络的输出层,使用全连接层来分类的情况下,才会使用softmax这种激活函数。
而损失函数,对于一些分类任务,通常使用交叉熵损失函数,回归任务使用均方误差,有自动对齐的任务使用CTC loss等。损失函数相当于模型拟合程度的一个评价指标,这个指标的结果越小越好。一个好的损失函数,可以在神经网络优化时,产生更好的模型参数。
- 训练时间不足
- 模型训练遇到瓶颈
- batch size过大
- 数据集未打乱
- 数据集有问题
- 并未进行归一化
- 特征工程对数据特征的选取有问题
猜测原因:模型结构存在问题、正则化过度等。
总之这或许是一个失败的实现,仅供学习使用。
总代码
import os
import shutil
import numpy as np
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn as nn
# 花的类别
class_flowers = ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
flowers_sum = 3670
# 训练集 路径
train_path = './../datasets/flowers/train/'
# 验证集 路径
val_path = './../datasets/flowers/validation/'
# GPU 加速
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 多头数
n_heads = 8
# q , k , v 的维数
d_q = d_k = d_v = 96
d_model = 768
n_layers = 2
batch_size = 32
class_flowers_num = 5
N_EPOCHS = 1
# 根据正余弦获取位置编码
def get_positional_embeddings(sequence_length,d):
result = torch.ones(sequence_length,d)
for i in range(sequence_length):
for j in range(d):
result[i][j] = np.sin(i/(10000**(j/d))) if j %2==0 else np.cos(i/(10000**((j-1)/d)))
return result
def get_sinusoid_encodingg_table(n_position, d_model):
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx // 2) / d_model)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in range(d_model)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table)
"""
封装点积运算
需要传入Q,K,V三个矩阵
将三个矩阵按照公式计算出Attention
"""
class scaledDotProductAttention(nn.Module):
def __init__(self):
super(scaledDotProductAttention, self).__init__()
def forward(self,Q,K,V):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
"""
封装DropPath操作
DropPath:将深度学习模型中的多分支结构随机失效
Dropout:将神经元随机失效
在这里DropPath实际就是对一个batch中随机选择一定数量的sample,将其特征值变为0
"""
def drop_path(x,drop_prob:float = 0.,training:bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
# print("x.shape:",x.shape)
# print("shape:",shape)
# print("keep_prob:",keep_prob)
random_tensor = keep_prob + torch.rand(shape,dtype=x.dtype,device=device)
# print("random_tensor:",random_tensor)
random_tensor.floor_()
output = x.div(keep_prob) * random_tensor
# print("output:",output.shape)
return output
class DropPath(nn.Module):
# drop_prob 有啥作用 这里我随便填的0.1
def __init__(self,drop_prob = 0.1):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self,x):
return drop_path(x,self.drop_prob,self.training)
"""
Multi-Head Attention实现
利用nn.Linear实现得到矩阵QKV
需要传入input_q,input_k,input_v
经过点积运算得到Attention权重之和
最后需要再经过一层全连接层 实现将维数转成起初的维数
最后经过LayerNorm函数
"""
class Multi_Head_Attention(nn.Module):
def __init__(self):
super(Multi_Head_Attention, self).__init__()
self.W_Q = nn.Linear(d_model,d_q * n_heads)
self.W_K = nn.Linear(d_model,d_k * n_heads)
self.W_V = nn.Linear(d_model,d_v * n_heads)
self.fc = nn.Linear(d_k*n_heads,d_model)
self.drop_path = DropPath()
def forward(self,input_q,input_k,input_v):
residual, batch_size = input_q, input_q.size(0)
Q = self.W_Q(input_q).view(batch_size,-1,n_heads,d_q).transpose(1,2)
K = self.W_K(input_k).view(batch_size,-1,n_heads,d_k).transpose(1,2)
V = self.W_V(input_v).view(batch_size,-1,n_heads,d_v).transpose(1,2)
# context: torch.Size([32, 8, 197, 96]) (batch_size,n_heads,197,d_k)
context,attn = scaledDotProductAttention()(Q,K,V)
# print(context.shape)
context = context.transpose(1,2).reshape(batch_size, -1 ,d_model)
# context: torch.Size([32, 197, 768])
context = self.fc(context)
# print("context1:",context)
# 在此加入DropPath处理
context1 = context
context = self.drop_path(context)
# print(context1.equal(context))
# print("context2:",context)
# context: torch.Size([32, 197, 768])
# 残差块处理 解决神经网络退化问题
return nn.LayerNorm(d_model).cuda(device)(context + residual),attn
class MLP_Block(nn.Module):
def __init__(self):
super(MLP_Block, self).__init__()
self.fc1 = nn.Linear(d_model,4*d_model).cuda(device)
self.gelu = nn.GELU()
self.dropout = nn.Dropout()
self.fc2 = nn.Linear(4*d_model,d_model).cuda(device)
self.drop_path = DropPath()
def forward(self,x):
# x = x.to(device)
x = self.fc1(x)
x = self.gelu(x)
x = self.dropout(x)
# print(x)
x = self.fc2(x)
x = self.dropout(x)
x = self.drop_path(x)
return x
# torch.Size([32, 3, 224, 224])
class MyViT_Layer(nn.Module):
"""
input_shape : [32,3,224,224]
n_patches : 表示将图片分成n_patches*n_patches块子图片
hidden_d :
n_head : 表示多头注意力的头数
out_d : 表示最后输出的维度 这里为5 表示有5种类别的花
"""
def __init__(self,):
super(MyViT_Layer, self).__init__()
# 经过一层 Norm层 目的是为标准化 加快收敛
self.LN1 = nn.LayerNorm(d_model).cuda(device)
# 经过Multi-Head Attention层 同时会进行残差处理
self.MultiHead = Multi_Head_Attention()
# 再经过一层LN层
self.LN2 = nn.LayerNorm(d_model).cuda(device)
# 再经过一层MLP_Block层
self.MLP_Block = MLP_Block()
def forward(self,x):
n = x.shape[0]
token = x # [n,196,768]
# print(token.shape)
# 添加Class Token
# token = torch.stack([torch.vstack((class_token, token[i])) for i in range(len(token))]) # [32, 196, 768] --> [32, 197, 768]
# 添加第一个LN层
token = self.LN1(token)
context,attn = self.MultiHead(token,token,token)
residual = context
# 添加第二个LN层
context = self.LN2(context)
# 添加MLP_Block层
# context = context.to(device)
context = self.MLP_Block(context)
context = nn.LayerNorm(d_model).cuda(device)(context + residual)
#transforms Encoder 部分
# print("context:",context.shape)
return context
class MyViT(nn.Module):
def __init__(self,input_shape,n_patches=14,hidden_d=768):
super(MyViT, self).__init__()
self.input_shape = input_shape
self.patch = (input_shape[1] / n_patches, input_shape[2] / n_patches) # self.patch : [16,16]
self.n_patchs = n_patches
self.input_d = int(self.input_shape[0] * self.patch[0] * self.patch[1])
self.hidden_d = hidden_d
self.class_token = nn.Parameter(torch.rand(1, self.hidden_d))
self.get_position_emb = nn.Embedding.from_pretrained(get_sinusoid_encodingg_table(197,d_model),freeze=True)
self.myvit = nn.ModuleList([MyViT_Layer() for _ in range(n_layers)])
self.mlp_head = nn.Sequential(
nn.Linear(d_model,class_flowers_num),
nn.Softmax(dim=-1)
)
def forward(self,x):
n = x.shape[0]
# print("n:", n)
x = x.reshape(n, self.n_patchs ** 2, self.input_d)
x = torch.stack(
[torch.vstack((self.class_token, x[i])) for i in range(len(x))]) # [32, 196, 768] --> [32, 197, 768]
i = 1
# 添加位置编码
# print(f"input_d:{self.input_d} x:{self.n_patchs**2 + 1}")
# posit_emb = self.get_position_emb(x).to(device)
# print("posit_emb:",posit_emb.shape)
x += get_positional_embeddings(self.n_patchs ** 2 + 1, self.input_d).repeat(n, 1, 1).to(device)
for layer in self.myvit:
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
x = layer(x)
# print(i)
i+=1
x = x[:,0]
x = self.mlp_head(x)
return x
def main():
# 图像预处理
data_transform = {
"train":transforms.Compose([
transforms.RandomRotation(45),# 随机旋转 -45度到45度之间
transforms.CenterCrop(224),# 从中间处开始裁剪
transforms.RandomHorizontalFlip(p = 0.5),# 随机水平旋转
transforms.RandomVerticalFlip(p = 0.5),# 随机垂直旋转
# 参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.ColorJitter(brightness= 0.2,contrast=0.1,saturation=0.1,hue=0.1),
transforms.RandomGrayscale(p=0.025),# 概率转换为灰度图,三通道RGB
# 灰度图转换以后也是三个通道,但是只是RGB是一样的
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
# resize成256 * 256 再选取 中心 224 * 224,然后转化为向量,最后正则化
"val": transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
# 均值和标准差和训练集相同
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
train_dataset = datasets.ImageFolder(root=train_path,transform=data_transform['train'])
val_dataset = datasets.ImageFolder(root=val_path,transform=data_transform['val'])
train_num = len(train_dataset)
val_num = len(val_dataset)
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=0)
val_loader = DataLoader(val_dataset,batch_size=batch_size,shuffle=True,num_workers=0)
# {'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflowers': 3, 'tulips': 4}
flower_list = train_dataset.class_to_idx
# {0: 'daisy', 1: 'dandelion', 2: 'roses', 3: 'sunflowers', 4: 'tulips'}
cal_dict = dict((val,key) for key ,val in flower_list.items())
model = MyViT((3,224,224),).to(device)
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
optimizer = torch.optim.Adam(model.parameters(),lr=0.01)
criterion = nn.CrossEntropyLoss().to(device)
# 图片数据 torch.Size([32, 3, 224, 224])
for epoch in range(N_EPOCHS):
train_loss = 0.0
now_index = 1
sum_num = int(flowers_sum/batch_size)
for img_batch,label_batch in train_loader:
img_batch = img_batch.to(device)
label_batch = label_batch.to(device)
y_pre = model(img_batch)
loss = criterion(y_pre,label_batch)/len(img_batch)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"epoch:{epoch} loss: {loss.item():.5f} 当前进度参考: {now_index}/{sum_num}")
now_index += 1
# break
# break
try:
print(f"Epoch {epoch + 1}/{N_EPOCHS} loss: {train_loss:.5f}")
with open(file="./train.txt",mode='a',encoding='UTF-8') as file_obj:
file_obj.write(f"Epoch {epoch + 1}/{N_EPOCHS} loss: {train_loss:.5f}\n")
except Exception:
print("asdf")
test_loss = 0.0
correct = 0.0
total = 0.0
for img_batch,label_batch in val_loader:
img_batch = img_batch.to(device)
label_batch = label_batch.to(device)
y_pre = model(img_batch)
loss = criterion(y_pre,label_batch)/len(img_batch)
test_loss += loss.item()
# print(y_pre.shape)
correct += torch.sum(torch.argmax(y_pre,dim=1) == label_batch).item()
total += len(img_batch)
print(f"验证ing,正确数:{correct},验证总数:{total}")
# print(correct)
# break
try:
print(f"Test loss: {test_loss:.5f}")
print(f"Test accuracy: {correct / total * 100:.5f}%")
with open(file="./train.txt", mode='a', encoding='UTF-8') as file_obj:
file_obj.write(f"Test accuracy: {correct / total * 100:.5f}%\n")
except Exception:
print("asdf")
"""
前期数据处理,将数据集划分为训练集以及验证集
选取比例为7:3
"""
def pre_data():
photos_path = './../datasets/flower_photos'
files = os.listdir(photos_path)
print(files)
for i in range(len(files)):
class_path = photos_path +'/' + files[i]
# print(class_path)
flower_file = os.listdir(class_path)
flower_num = len(flower_file)
new_train_path = './../datasets/flowers/train/' + files[i]
new_val_path = './../datasets/flowers/validation/' + files[i]
print(new_train_path,new_val_path)
if not os.path.exists(new_train_path):
os.makedirs(new_train_path)
if not os.path.exists(new_val_path):
os.makedirs(new_val_path)
for j in range(flower_num):
if(j <= flower_num * 0.7):
old_file_path = class_path + '/' + flower_file[j]
new_file_path = new_train_path + '/' + flower_file[j]
shutil.copy(old_file_path,new_file_path)
print(old_file_path,new_file_path)
else:
old_file_path = class_path + '/' + flower_file[j]
new_file_path = new_val_path + '/' + flower_file[j]
shutil.copy(old_file_path,new_file_path)
print(old_file_path, new_file_path)
if __name__ == '__main__':
# pre_data()
main()
# print(train_loader,val_loader)
pass

 浙公网安备 33010602011771号
浙公网安备 33010602011771号