Vision Transformer代码(Pytorch版本)
Vision Transformer代码(Pytorch版本)
定义任务
我们选择入门数据集,我们的MNIST 手写数据集进行图像分类,虽然目标简单,但是我们可以基于该图像分类任务理清ViT模型的整个脉络。简单介绍下MNIST数据集,为是手写数字 ([0–9]) 的数据集,图像均为28x28大小的灰度图。
Patchifying和线性映射
对于Vision Transformer模型,我们需要将图像数据序列化。在MNIST数据集中,我们将每个(1*28*28)的图像分成7*7块每块大小为4*4(如果不能完全整除分块,需要对图像padding填充),我们就得到49个子图像。按照Vision Transformer模型,我们将原图重塑成:(N,P*P,H*C/P *W*C/P)=(N,7*7,4*4)=(N,49,16)。
在我们得到展平后的patches即向量,通过一个线性映射来改变维度,线性映射可以映射到任意向量大小,我们向类构造函数添加一个hidden_d参数,用于“隐藏维度”。这里,使用隐藏维度为8,这样我们将每个 16 维patch映射到一个 8 维patch, 实现代码如下。
代码如下:
class MyViT(nn.Module):
def __init__(self,input_shape,n_patches=7,hidden_d = 8):
super(MyViT, self).__init__()
self.input_shape = input_shape
self.n_patches = n_patches
self.patch_size = (input_shape[1] / n_patches, input_shape[2] / n_patches)
self.hidden_d = hidden_d
'''
self.patch = (4,4)
input_shape = (1,28,28)
'''
self.input_d = int(input_shape[0] * self.patch_size[0] * self.patch_size[1]) # input_shape = 16
self.linear_mapper = nn.Linear(self.input_d,self.input_d) # 这里为什么把16维转化成8维 想不明白
def forward(self,images):
n,c,w,h = images.shape
patches = images.reshape(n,self.n_patches ** 2,self.input_d) #(n,c,w,h) --> (n,7*7,16)
tokens = self.linear_mapper(patches) # (n,49,16) --> (n,49,8)
return tokens
添加分类标记
我们需要添加Class Token,用于后面分类使用。所以需要为模型添加一个参数将我们的(N,49,8)张量转换为(N,50,8)。
class MyViT(nn.Module):
def __init__(self,input_shape,n_patches=7,hidden_d = 8):
super(MyViT, self).__init__()
self.input_shape = input_shape
self.n_patches = n_patches
self.patch_size = (input_shape[1] / n_patches, input_shape[2] / n_patches)
self.hidden_d = hidden_d
'''
self.patch = (4,4)
input_shape = (1,28,28)
'''
self.input_d = int(input_shape[0] * self.patch_size[0] * self.patch_size[1]) # input_shape = 16
self.linear_mapper = nn.Linear(self.input_d,self.input_d) # 这里为什么把16维转化成8维 想不明白
self.class_token = nn.Parameter(torch.rand(1,self.hidden_d)) # 形成一个(1,8)的张量
def forward(self,images):
n,c,w,h = images.shape
patches = images.reshape(n,self.n_patches ** 2,self.input_d) #(n,c,w,h) --> (n,7*7,16)
tokens = self.linear_mapper(patches) # (n,49,16) --> (n,49,8)
tokens = torch.stack([torch.vstack((self.class_token,tokens[i])) for i in range(len(tokens))]) # (n,49,8) --> (n,50,8)
return tokens
添加位置编码
虽然在Vision Transformer论文中使用的是可学习的位置编码,但是为了方便起见,我们这里依旧使用的是Transformer论文中使用的是正余弦位置编码。
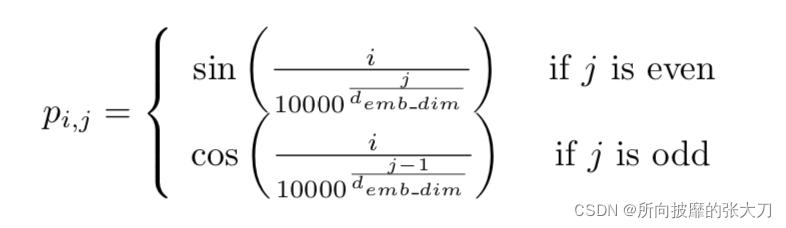
代码如下:
# 根据正余弦获取位置编码
def get_positional_embeddings(sequence_length,d):
result = torch.ones(sequence_length,d)
for i in range(sequence_length):
for j in range(d):
result[i][j] = np.sin(i/(10000**(j/d))) if j %2==0 else np.cos(i/(10000**((j-1)/d)))
return result
class MyViT(nn.Module):
def __init__(self,input_shape,n_patches=7,hidden_d = 8):
super(MyViT, self).__init__()
self.input_shape = input_shape
self.n_patches = n_patches
self.patch_size = (input_shape[1] / n_patches, input_shape[2] / n_patches)
self.hidden_d = hidden_d
'''
self.patch = (4,4)
input_shape = (1,28,28)
'''
self.input_d = int(input_shape[0] * self.patch_size[0] * self.patch_size[1]) # input_shape = 16
self.linear_mapper = nn.Linear(self.input_d,self.input_d) # 这里为什么把16维转化成8维 想不明白
self.class_token = nn.Parameter(torch.rand(1,self.hidden_d)) # 形成一个(1,8)的张量
def forward(self,images):
n,c,w,h = images.shape
patches = images.reshape(n,self.n_patches ** 2,self.input_d) #(n,c,w,h) --> (n,7*7,16)
tokens = self.linear_mapper(patches) # (n,49,16) --> (n,49,8)
tokens = torch.stack([torch.vstack((self.class_token,tokens[i])) for i in range(len(tokens))]) # (n,49,8) --> (n,50,8)
# 添加位置编码
tokens += get_positional_embeddings(self.n_patches **2 +1,self.hidden_d).repeat(n,1,1) # 添加的是(n,50,8)的矩阵
return tokens
Transformer Encoder层
我们经过上面的处理,我们得到了Embedding Patches。按照上图所示,依次处理。我们需要先对tokens做层归一化,然后应用多头注意力机制,最后添加一个残差连接,再经过层归一化后,再经过MLP处理,最后经过残差连接,重复L次输出。
多头自注意力
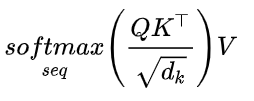
# 多头自注意力
"""
对于单个图像,我们希望每个patch都根据与其它patch的某种相似性来更新。
通过将每个patch(在这里是一个8维向量)线性映射到3个不同的向量q,k,v
然后对于单个patch,我们将计算其q向量与所有k个向量的点积,
除以这些向量维度的平方根d,对计算结果softmax激活,
最后将计算结果与不同的k向量相关联的v向量相乘。
"""
class MyMSA(nn.Module):
def __init__(self,d,n_heads = 2):
super(MyMSA, self).__init__()
self.d = d
self.n_heads = n_heads
d_head = int(d/n_heads)
self.q_mappings = [nn.Linear(d_head, d_head) for _ in range(self.n_heads)]
self.k_mappings = [nn.Linear(d_head, d_head) for _ in range(self.n_heads)]
self.v_mappings = [nn.Linear(d_head, d_head) for _ in range(self.n_heads)]
self.d_head = d_head
self.softmax = nn.Softmax(dim = -1)
def forward(self,sequences):
'''
:param sequences:(N,seq_length,token_dim)
'''
result = []
for sequence in sequences:
seq_result = []
for head in range(self.n_heads):
q_mapping = self.q_mappings[head]
k_mapping = self.k_mappings[head]
v_mapping = self.v_mappings[head]
seq = sequence[:,head * self.d_head:(head+1) * self.d_head]
q,k,v = q_mapping(seq),k_mapping(seq),v_mapping(seq)
attention = self.softmax(q @ k.T / (self.d_head ** 0.5))
seq_result.append(attention @ v)
result.append(torch.hstack(seq_result))
return torch.cat([torch.unsqueeze(r,dim=0) for r in result])
残差连接
将添加一个残差连接,它将我们的原始 (N, 50, 8) 张量添加到在 LN 和 MSA 之后获得的 (N, 50, 8)。
class MyViT(nn.Module):
def __init__(self,input_shape,n_patches=7,hidden_d = 8,n_heads = 2):
super(MyViT, self).__init__()
self.input_shape = input_shape
self.n_patches = n_patches
self.n_heads = n_heads
self.patch_size = (input_shape[1] / n_patches, input_shape[2] / n_patches)
self.hidden_d = hidden_d
'''
self.patch = (4,4)
input_shape = (1,28,28)
'''
self.input_d = int(input_shape[0] * self.patch_size[0] * self.patch_size[1]) # input_shape = 16
self.linear_mapper = nn.Linear(self.input_d,self.input_d) # 这里为什么把16维转化成8维 想不明白
self.class_token = nn.Parameter(torch.rand(1,self.hidden_d)) # 形成一个(1,8)的张量
self.ln1 = nn.LayerNorm((self.n_patches ** 2 + 1,self.hidden_d))
self.msa = MyMSA(self.hidden_d,n_heads)
def forward(self,images):
n,c,w,h = images.shape
patches = images.reshape(n,self.n_patches ** 2,self.input_d) #(n,c,w,h) --> (n,7*7,16)
tokens = self.linear_mapper(patches) # (n,49,16) --> (n,49,8)
tokens = torch.stack([torch.vstack((self.class_token,tokens[i])) for i in range(len(tokens))]) # (n,49,8) --> (n,50,8)
# 添加位置编码
tokens += get_positional_embeddings(self.n_patches **2 +1,self.hidden_d).repeat(n,1,1) # 添加的是(n,50,8)的矩阵
out = tokens + self.msa(self.ln1(tokens))
return out
LN,MLP和残差连接
class MyViT(nn.Module):
def __init__(self,input_shape,n_patches=7,hidden_d = 8,n_heads = 2):
super(MyViT, self).__init__()
self.input_shape = input_shape
self.n_patches = n_patches
self.n_heads = n_heads
self.patch_size = (input_shape[1] / n_patches, input_shape[2] / n_patches)
self.hidden_d = hidden_d
'''
self.patch = (4,4)
input_shape = (1,28,28)
'''
self.input_d = int(input_shape[0] * self.patch_size[0] * self.patch_size[1]) # input_shape = 16
self.linear_mapper = nn.Linear(self.input_d,self.input_d) # 这里为什么把16维转化成8维 想不明白
self.class_token = nn.Parameter(torch.rand(1,self.hidden_d)) # 形成一个(1,8)的张量
self.ln1 = nn.LayerNorm((self.n_patches ** 2 + 1,self.hidden_d))
self.msa = MyMSA(self.hidden_d,n_heads)
self.ln2 = nn.LayerNorm((self.n_patches ** 2 + 1,self.hidden_d))
self.enc_mlp = nn.Sequential(
nn.Linear(self.hidden_d,self.hidden_d),
nn.ReLU()
)
def forward(self,images):
n,c,w,h = images.shape
patches = images.reshape(n,self.n_patches ** 2,self.input_d) #(n,c,w,h) --> (n,7*7,16)
tokens = self.linear_mapper(patches) # (n,49,16) --> (n,49,8)
tokens = torch.stack([torch.vstack((self.class_token,tokens[i])) for i in range(len(tokens))]) # (n,49,8) --> (n,50,8)
# 添加位置编码
tokens += get_positional_embeddings(self.n_patches **2 +1,self.hidden_d).repeat(n,1,1) # 添加的是(n,50,8)的矩阵
out = tokens + self.msa(self.ln1(tokens))
out = out + self.enc_mlp(self.ln2(out))
return out
分类MLP
最后,我们可以从 N 个序列中只提取分类标记(第一个标记),与添加分类标签的位置对应,并使用每个标记得到 N 个分类。
由于我们决定每个标记是一个 8 维向量,并且由于我们有 10 个可能的数字,我们可以将分类 MLP 实现为一个简单的 8x10 矩阵,并使用 SoftMax 函数激活。
class MyViT(nn.Module):
def __init__(self,input_shape,n_patches=7,hidden_d = 8,n_heads = 2,out_d = 10):
super(MyViT, self).__init__()
self.input_shape = input_shape
self.n_patches = n_patches
self.n_heads = n_heads
assert input_shape[1] % n_patches == 0, "Input shape not entirely divisible by number of patches"
assert input_shape[2] % n_patches == 0, "Input shape not entirely divisible by number of patches"
self.patch_size = (input_shape[1] / n_patches, input_shape[2] / n_patches)
self.hidden_d = hidden_d
'''
self.patch = (4,4)
input_shape = (1,28,28)
'''
self.input_d = int(input_shape[0] * self.patch_size[0] * self.patch_size[1]) # input_shape = 16
self.linear_mapper = nn.Linear(self.input_d,self.hidden_d) # 这里为什么把16维转化成8维 想不明白
self.class_token = nn.Parameter(torch.rand(1,self.hidden_d)) # 形成一个(1,8)的张量
self.ln1 = nn.LayerNorm((self.n_patches ** 2 + 1,self.hidden_d))
self.msa = MyMSA(self.hidden_d,n_heads)
self.ln2 = nn.LayerNorm((self.n_patches ** 2 + 1,self.hidden_d))
self.enc_mlp = nn.Sequential(
nn.Linear(self.hidden_d,self.hidden_d),
nn.ReLU()
)
self.mlp = nn.Sequential(
nn.Linear(self.hidden_d,out_d),
nn.Softmax(dim = -1)
)
def forward(self,images):
n,c,w,h = images.shape
patches = images.reshape(n,self.n_patches ** 2,self.input_d) #(n,c,w,h) --> (n,7*7,16)
tokens = self.linear_mapper(patches) # (n,49,16) --> (n,49,8)
tokens = torch.stack([torch.vstack((self.class_token, tokens[i])) for i in range(len(tokens))]) # (n,49,8) --> (n,50,8)
# 添加位置编码
tokens += get_positional_embeddings(self.n_patches **2 +1,self.hidden_d).repeat(n,1,1) # 添加的是(n,50,8)的矩阵
out = tokens + self.msa(self.ln1(tokens))
out = out + self.enc_mlp(self.ln2(out))
out = out[:,0]
return self.mlp(out)
总
# 导入的包
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import torch.optim as optim
np.random.seed(0)
torch.manual_seed(0)
# 根据正余弦获取位置编码
def get_positional_embeddings(sequence_length,d):
result = torch.ones(sequence_length,d)
for i in range(sequence_length):
for j in range(d):
result[i][j] = np.sin(i/(10000**(j/d))) if j %2==0 else np.cos(i/(10000**((j-1)/d)))
return result
# 多头自注意力
"""
对于单个图像,我们希望每个patch都根据与其它patch的某种相似性来更新。
通过将每个patch(在这里是一个8维向量)线性映射到3个不同的向量q,k,v
然后对于单个patch,我们将计算其q向量与所有k个向量的点积,
除以这些向量维度的平方根d,对计算结果softmax激活,
最后将计算结果与不同的k向量相关联的v向量相乘。
"""
class MyMSA(nn.Module):
def __init__(self,d,n_heads = 2):
super(MyMSA, self).__init__()
self.d = d
self.n_heads = n_heads
assert d % n_heads == 0, f"Can't divide dimension {d} into {n_heads} heads"
d_head = int(d/n_heads)
self.q_mappings = [nn.Linear(d_head, d_head) for _ in range(self.n_heads)]
self.k_mappings = [nn.Linear(d_head, d_head) for _ in range(self.n_heads)]
self.v_mappings = [nn.Linear(d_head, d_head) for _ in range(self.n_heads)]
self.d_head = d_head
self.softmax = nn.Softmax(dim = -1)
def forward(self,sequences):
'''
:param sequences:(N,seq_length,token_dim)
'''
result = []
for sequence in sequences:
seq_result = []
for head in range(self.n_heads):
q_mapping = self.q_mappings[head]
k_mapping = self.k_mappings[head]
v_mapping = self.v_mappings[head]
seq = sequence[:,head * self.d_head:(head+1) * self.d_head]
q,k,v = q_mapping(seq),k_mapping(seq),v_mapping(seq)
attention = self.softmax(q @ k.T / (self.d_head ** 0.5))
seq_result.append(attention @ v)
result.append(torch.hstack(seq_result))
return torch.cat([torch.unsqueeze(r,dim=0) for r in result])
class MyViT(nn.Module):
def __init__(self,input_shape,n_patches=7,hidden_d = 8,n_heads = 2,out_d = 10):
super(MyViT, self).__init__()
self.input_shape = input_shape
self.n_patches = n_patches
self.n_heads = n_heads
assert input_shape[1] % n_patches == 0, "Input shape not entirely divisible by number of patches"
assert input_shape[2] % n_patches == 0, "Input shape not entirely divisible by number of patches"
self.patch_size = (input_shape[1] / n_patches, input_shape[2] / n_patches)
self.hidden_d = hidden_d
'''
self.patch = (4,4)
input_shape = (1,28,28)
'''
self.input_d = int(input_shape[0] * self.patch_size[0] * self.patch_size[1]) # input_shape = 16
self.linear_mapper = nn.Linear(self.input_d,self.hidden_d) # 这里为什么把16维转化成8维 想不明白
self.class_token = nn.Parameter(torch.rand(1,self.hidden_d)) # 形成一个(1,8)的张量
self.ln1 = nn.LayerNorm((self.n_patches ** 2 + 1,self.hidden_d))
self.msa = MyMSA(self.hidden_d,n_heads)
self.ln2 = nn.LayerNorm((self.n_patches ** 2 + 1,self.hidden_d))
self.enc_mlp = nn.Sequential(
nn.Linear(self.hidden_d,self.hidden_d),
nn.ReLU()
)
self.mlp = nn.Sequential(
nn.Linear(self.hidden_d,out_d),
nn.Softmax(dim = -1)
)
def forward(self,images):
n,c,w,h = images.shape
patches = images.reshape(n,self.n_patches ** 2,self.input_d) #(n,c,w,h) --> (n,7*7,16)
tokens = self.linear_mapper(patches) # (n,49,16) --> (n,49,8)
tokens = torch.stack([torch.vstack((self.class_token, tokens[i])) for i in range(len(tokens))]) # (n,49,8) --> (n,50,8)
# 添加位置编码
tokens += get_positional_embeddings(self.n_patches **2 +1,self.hidden_d).repeat(n,1,1) # 添加的是(n,50,8)的矩阵
out = tokens + self.msa(self.ln1(tokens))
out = out + self.enc_mlp(self.ln2(out))
out = out[:,0]
return self.mlp(out)
def main():
transform = ToTensor()
train_set= MNIST(root='./../datasets',train=True,download=False,transform=transform)
test_set = MNIST(root='./../datasets',train=False,download=False,transform=transform)
train_loader = DataLoader(train_set,shuffle=True,batch_size=16)
test_loader = DataLoader(test_set,shuffle=False,batch_size=16)
model = MyViT((1,28,28),n_patches=7,hidden_d=20,n_heads=2,out_d=10)
N_EPOCHS = 1
LR = 0.01
optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.99)
criterion = nn.CrossEntropyLoss()
for epoch in range(N_EPOCHS):
train_loss = 0.0
for batch in train_loader:
x,y = batch
y_hat = model(x)
loss = criterion(y_hat,y)/len(x)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(1)
print(f"Epoch {epoch + 1}/{N_EPOCHS} loss: {train_loss:.2f}")
# Test loop
correct, total = 0, 0
test_loss = 0.0
for batch in test_loader:
x, y = batch
y_hat = model(x)
loss = criterion(y_hat, y) / len(x)
test_loss += loss
correct += torch.sum(torch.argmax(y_hat, dim=1) == y).item()
total += len(x)
print(f"Test loss: {test_loss:.2f}")
print(f"Test accuracy: {correct / total * 100:.2f}%")
if __name__ == '__main__':
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号