Vision Transformer详解
Vision Transformer详解
基于计算机视觉的Transformer研究进展
计算机视觉通常涉及对图像或视频的评估,主要包括图像分类、目标检测、目标跟踪、语义分割等子任务。基于深度学习的方法在计算机视觉领域中最典型的应用就是卷积神经网络CNN。但是CNN缺乏对图像本身的全局理解,无法建模特征之间的依赖关系,从而不能充分地应用上下文信息。为了 解决这个问题,研究人员尝试将Transformer模型引用到计算机视觉任务当中,相比CNN,Transformer的自注意力机制不受局部相互作用的限制,既能挖掘长距离的依赖关系又能并行计算,可以根据不同的任务目标学习最合适的归纳偏置,在诸多视觉任务中取得了良好的效果。
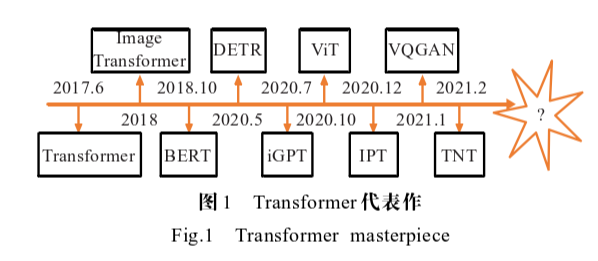
Transformer能在计算机视觉领域迅速发展的原因:
- 学习长距离依赖能力强;
- 多模态融合能力强;
- 模型更具有可解释性。

参考论文:[1]刘文婷,卢新明.基于计算机视觉的Transformer研究进展[J].计算机工程与应用,2022,58(06):1-16.
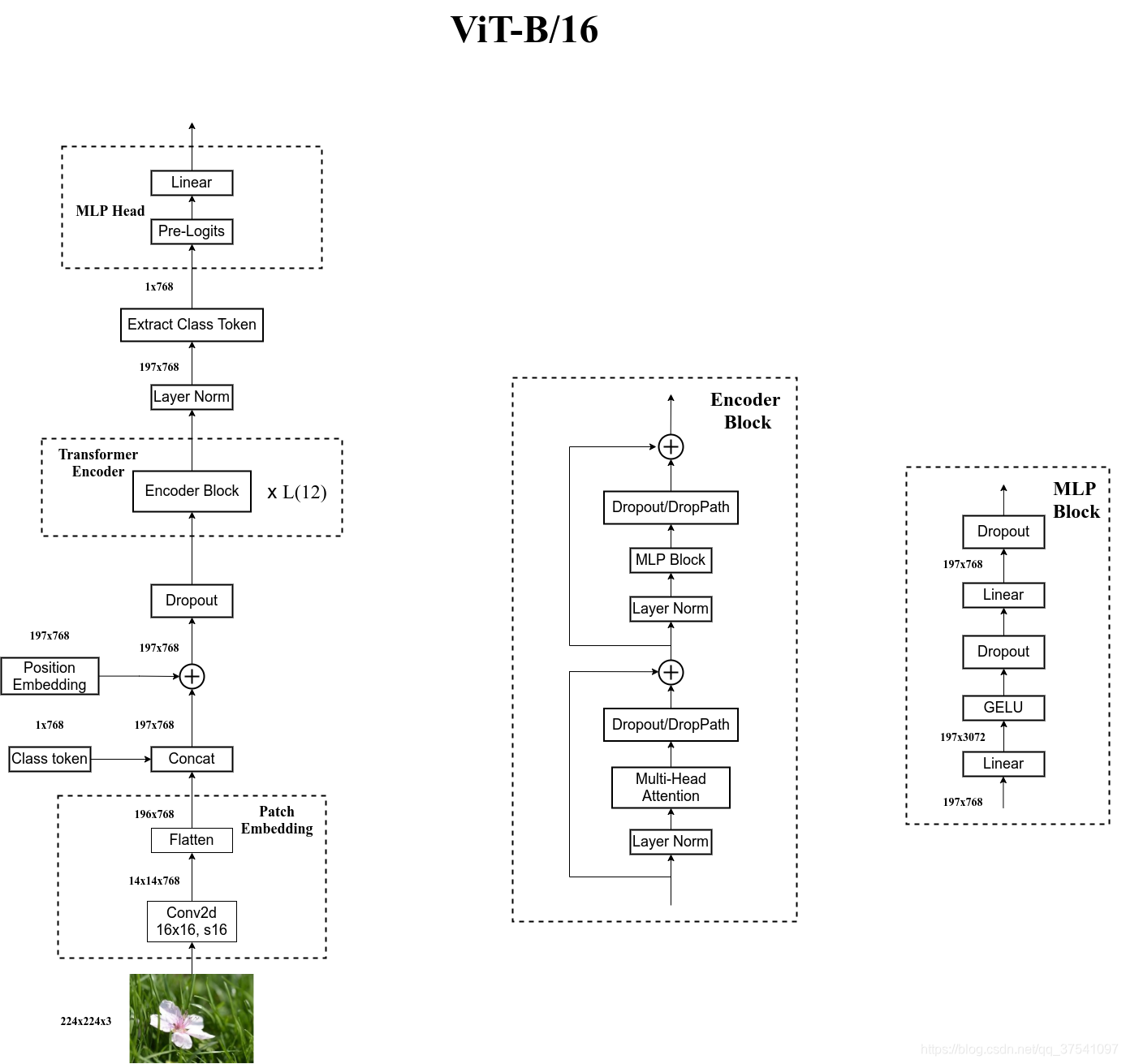
ViT模型整体框架
从上图中可以发现,ViT模型由三部分组成:
-
Linear Projection of Flattened Patches(Embedding层)
-
Transformer Encoder
-
MLP Head(用于最后分类的结构层次)
Embedding层结构详解
ViT模型是一种完全基于自注意力机制的结构。为了将图像转化成转化成Transformer结构可以处理的序列数据,引入了图像块(patch)的概念。首先将二维图像做分块处理,即将图像分成同等大小的部分,如下:
可以看到上图将一张RGB图片分成了9个相同大小的部分。为什么要这么处理呢?这是因为NLP中的Transformer输入的是一个二维的Tensor,但是图片却是三维的Tensor(都没有考虑Batch)。将三维的Tensor转化成二维的Tensor的过程成为patch_embedding。假设原图尺寸为H×W×C,每个块的大小为m×n×C,对于上图我们分成了9个patch。接着通过线性映射将每个patch映射到一维向量中,假设每个patch数据的shape为[16,16,3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
在这里就提供了一种思路:先用一些CNN模型来对图片提取特征,只要使CNN最后的输出维度为196*768,最后在送入Transformer模型中。其实这就将CNN和Transformer很好的结合在一起了。
如此我们得到了196*768维的Tensor(后称该Tensor为x),接下来应该使用一个维度为1*768维的Class Token来和x进行合并操作,输出结果为197*768维的Tensor。为什么要添加Class Token?如果不添加Class Token,直接将196*768维的Tensor输入到Encoder中,我们输出同样是196*768,即196个1*768维的向量,这时候我们应该拿哪个向量来当作最后的输出向量进而进行物体分类任务呢?这我们是很难确定的。所以我们干脆在输入Encode前就加上一个1*768维的向量(这个1维向量放在196*768维向量前面),这样在输出时向量的维度就会是197*768,然后我们只需要通过切片的方式获得第一个1*768维向量并将其送入分类头进行分类即可。在代码中这个Class token是一个可学习的向量,初始为全0的1*768维向量。
Class token和x拼接后,输出的尺寸为197*768(后称为y),此时我们应该在Tensor中添加位置编码向量position Embedding,其维度应该为197*768。在Transformer中,位置编码使用的是正弦位置编码,在这里我们将位置编码向量设置为一个可学习的向量,初始为全0的197*768维的向量。将其与y做相加,然后将其输入Encoder网络中。
Transformer Encoder
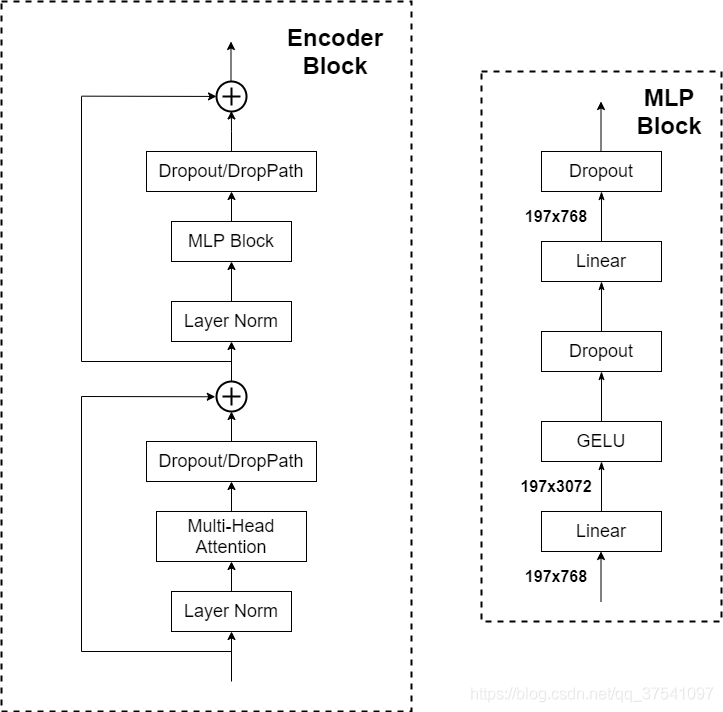
输入的Tensor经过L次Encoder结构,该结构如同Transformer模型中一致。MLP Block,如图右侧所示,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]。使用DropPath效果会好一些。
MLP Head详解
经过encoder结构后,输出的维度维197*768,此时我们会通过切片的方式提取出Class token的信息,其维度为1*768。接着会拿这个1*768维的Class token经过MLP Head层。
其中Pre-Logits这部分是可选的,其就是一个全连接层加上一个tanh激活函数,具体我们会在下一篇代码实战部分进行讲解。Linear就用于分类了,输出节点个数为我们任务的类别数。
总结
我们发现,当在小数据集ImageNet上做预训练时,VIT的模型架构效果普遍低于BiT【注:BiT是用ResNet搭建的结构】;当在中等数据集ImageNet-21k上做预训练时,VIT的模型架构基本位于BiT最好和最差的之间;而当在大数据集JFT-300M上做预训练时,VIT的模型架构最好的效果已经超过了BiT。
这个实验告诉我们什么呢?——VIT模型需要在大数据集上进行预训练,在大数据集上预训练的效果会比卷积神经网络的上限高!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号