Transformer笔记
Transformer模型笔记
在transformer模型提出之前,在NLP任务中常用的是RNN网络结构。transformer基于Self-Attention结构取代了RNN网络结构,相比RNN,其最大的优点便是可以并行运算,加快了运算速度。
Encoder-Decoder架构
Encoder-Decoder并不是具体的模型,而是一个通用的框架。所谓编码就是将输入序列转化成一个固定长度的向量,解码就是将之前的固定向量在转化出输出序列。不同任务可以选择不同的编码器和解码器。Encoder-Decoder是一个End-to-End的学习算法,以机器翻译为例,可以将中文翻译成英文。这样的模型也称为Seq2Seq。seq2seq模型强调目的,不特指具体的方法,seq2seq使用的具体方法基本都是属于Encoder-Decoder模型的范畴。
所谓Encoder-Decoder模型是一种应用于Seq2seq问题的模型。seq2seq就是根据一个输入序列x,来生成另一个输出序列y。seq2seq有很多的应用,例如翻译,文档摘取,问答系统等等。在翻译中,输入序列是待翻译的文本,输出序列是翻译后的文本;在问答系统中,输入序列是提出的问题,而输出序列是答案。为了解决seq2seq问题,有人提出了encoder-decoder模型,也就是编码-解码模型。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
具体实现Encoder-Decoder框架时,编码器和解码器都不是固定的,可选的有CNN、RNN、BiRNN、GRU、LSTM等等。并且可以具体问题具体组合,比如说,你在编码时使用BiRNN,解码时使用RNN,或者在编码时使用RNN,解码时使用LSTM等等。
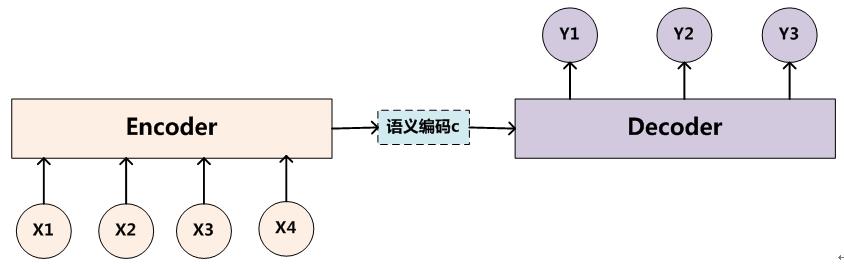
假设现在解码器和编码器都是RNN的组合。在RNN中,当前时间的隐藏状态和当前时间输入决定的,公式如下:

获得了各个时间段的隐藏状态后,再将隐藏层的信息汇总,生成最后的语义向量:
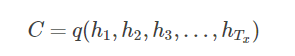
一种简单的方法是将最后的隐藏层作为语义向量C:
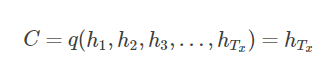
解码阶段可以看成是编码的逆过程。这个阶段,我们要根据给定的语义向量C和之前已经生成的输出序列来预测下一个输出的单词,即:
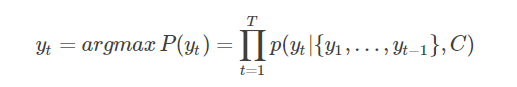
在RNN中可以简化成:
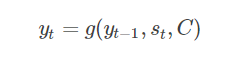
其中y表示上个时间段的输入,C表示之前提过的语义向量,其中s是输出RNN的隐藏层,而g则可以是一个非线性的多层的神经网络,产生词典中各个词语属于yt的概率。
Encoder-Decoder模型虽然非常经典,但是局限性也非常大。最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量C。也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码的准确度自然也就要打个折扣了
为了解决上诉中信息过长导致信息丢失的问题,引入了Attention模型。
Attention模型
Attention的原理
Attention模型的提出是为了解决信息过长导致信息丢失的问题,所以这种模型在输出的时候还会产生一个"注意力范围"表示接下来输出的时候应该重点关注输入序列中的哪些部分,然后根据这部分来产生下一个输出。如下图所示:
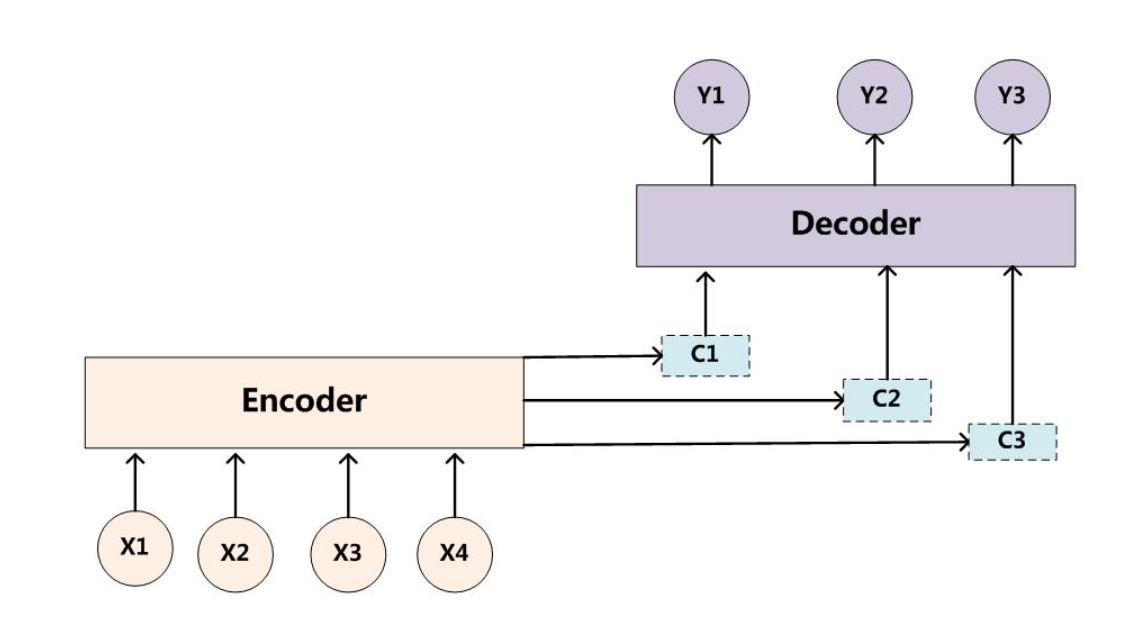
观察上图可以发现,解码器和编码器之间的连接由单个固定语义向量变成了多个向量,这就是Attention的特点所在。
那么问题出现了,如何计算Ci呢?如何判断每次解码时候注意力应该放在哪里呢?
现假设基于Attention实现的机器翻译来翻译“Tom chase Jerry”-“汤姆追逐杰瑞”来回答这个问题。当翻译“杰瑞”的时候,为了体现出输入序列中英文对于当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(chase,0.2)(Jerry,0.5)。这个表示在翻译杰瑞时,注意力机制分配给不同单词的注意力大小。理解AM模型的关键就在于,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型变化的Ci。
由于这里是手动给出的概率分布,那么计算机如何计算出模型所需要的输入句子单词注意力分配概率分布值呢?

以普通的RNN-RNN,Encoder-Decoder结构为例,上图中EOS作为Decoder的初始符。将输入EOS和初始S0通过RNN生成h(eos),然后分别计算h(eos)与h1,h2....的相关性f1,f2....,如下图所示:

Attention机制的本质思想
对Attention机制的抽象,可以归结为两个过程,第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。
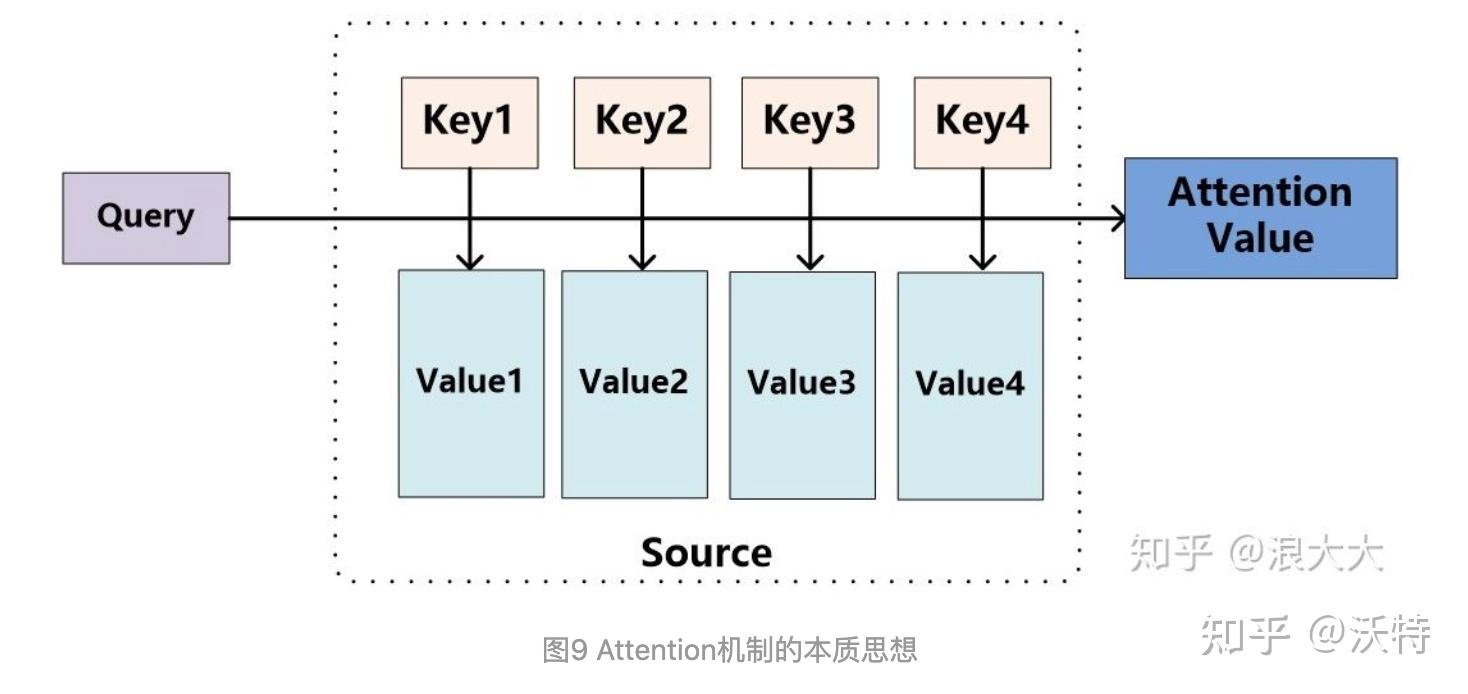
将Source中的构成元素想象成是有一系列的<key,value>数据构成(对应上面的例子,key和value是相等的,都是Decoder的输出h)。此时给定Target中的某个元素Query(对应上面例子中的hi),通过计算Query和各个key的相似性或者相关性,得到每个key对应value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。而计算query和key的相似性,一般用点积、Cosine相似性(余弦相似度)进行计算。点积不必多说,而余弦相似度计算公式如下:
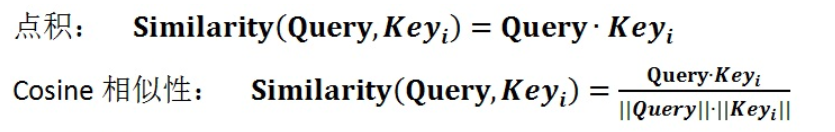
计算出相似性后用softMax进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布。得到概率分布就进行与value的加权求和,就得到了Attention的值。
Attention机制的本质思想一言以概之就是:"Attention机制就是对不同计算纬度加权求和"。
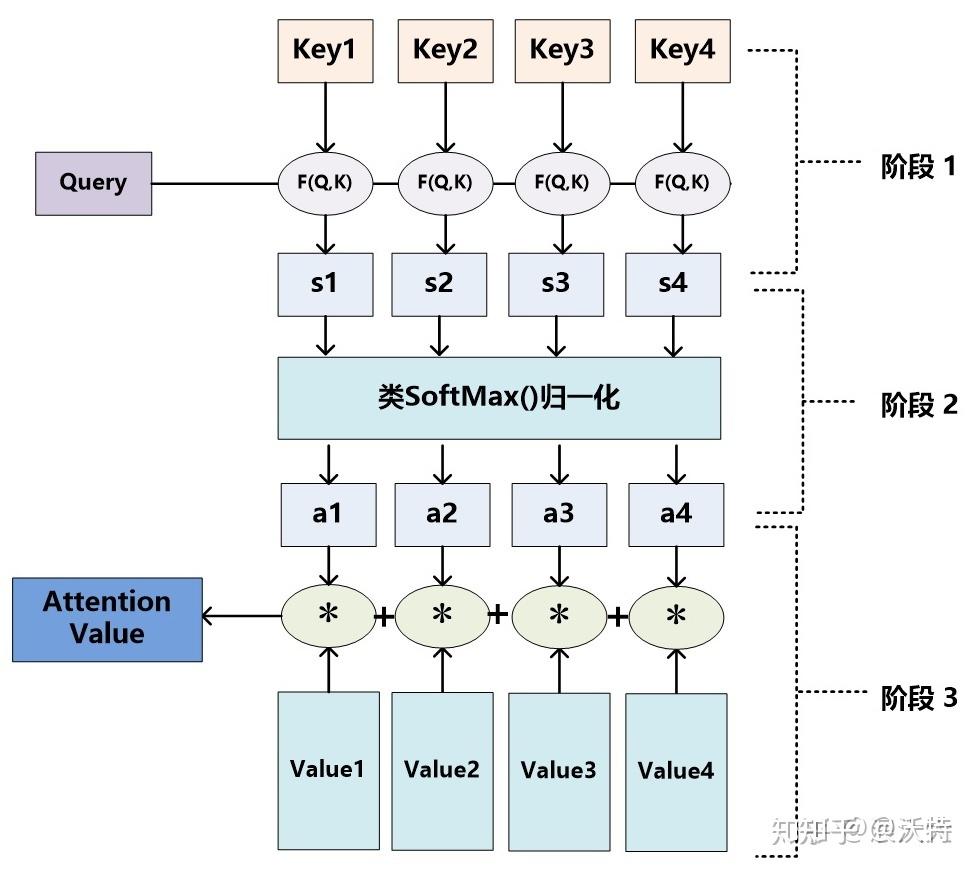
阶段1:Query与每一个Key计算相似性得到相似性评分s
阶段2:将s评分进行softmax转换成[0,1]之间的概率分布
阶段3:将[a1,a2,a3…an]作为权值矩阵对Value进行加权求和得到最后的Attention值
那么Attention如何准确将注意力放在关注的地方呢?
- 对于RNN的输出计算注意程度,通过计算最终时刻的向量与任意i时刻向量的权重,通过softmax计算出注意力偏向分数,如果对于某一个序列特别注意,那么计算出的偏向注意分数会较大;
- 将每个时刻对于最后输出的注意力分数进行加权,计算出每个时刻i向量应该赋予多少注意力;
- Decoder每个时刻都会将阶段3部分的注意力权重输入到Decoder中,此时Decoder中的输入有:经过注意力加权的隐藏层向量,Encoder的输出向量,以及Decoder上一时刻的隐向量
- Decoder通过不断迭代,Decoder可以输出最终翻译的序列。
Attention优缺点
优点:
1.速度快。Attention机制不再依赖于RNN,解决了RNN不能并行计算的问题。这里需要说明一下,基于Attention机制的seq2seq模型,因为是有监督的训练,所以咱们在训练的时候,在decoder阶段并不是说预测出了一个词,然后再把这个词作为下一个输入,因为有监督训练,咱们已经有了target的数据,所以是可以并行输入的,可以并行计算decoder的每一个输出,但是再做预测的时候,是没有target数据地,这个时候就需要基于上一个时间节点的预测值来当做下一个时间节点decoder的输入。所以节省的是训练的时间。
2.效果好。效果好主要就是因为注意力机制,能够获取到局部的重要信息,能够抓住重点。
缺点:
1.只能在Decoder阶段实现并行运算,Encoder部分依旧采用的是RNN,LSTM这些按照顺序编码的模型,Encoder部分还是无法实现并行运算,不够完美。
2.就是因为Encoder部分目前仍旧依赖于RNN,所以对于中长距离之间,两个词相互之间的关系没有办法很好的获取。
Self-Attention模型
为了改进Attention的缺点,更加完美的Self-Attention出现了。在一般任务的Encoder-Decoder框架中,输入source和输出Target内容是不一样的。以中英机器翻译为例,source是英文句子,Target是中文句子,Attention机制发生在source和Target所有元素之间。而Self-Attention指的不是Target和Source之间的Attention机制,而是Source内部元素之间和Target内部元素之间发送的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力机制。具体计算过程与Attention一样,但是计算对象发送了变化,相当是Query=key=Value。
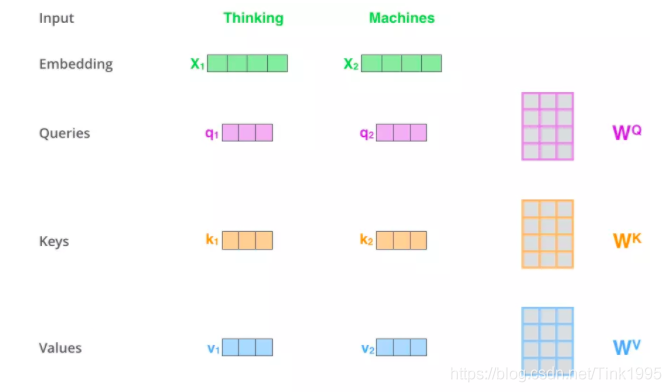
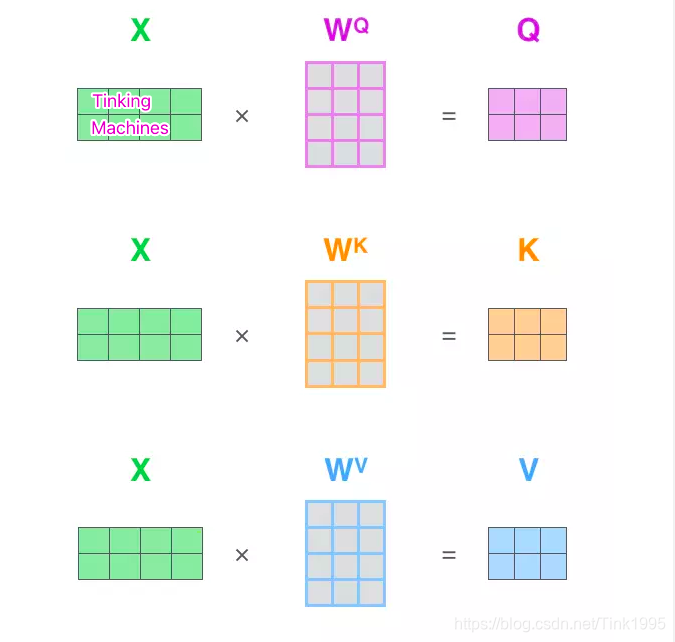
假如输入序列是“Thinking Machines”,embedding是对应添加过位置编码之后的词向量,然后词向量通过三个权值矩阵W转变成为计算Attention值所需的Query,Keys,Values向量。

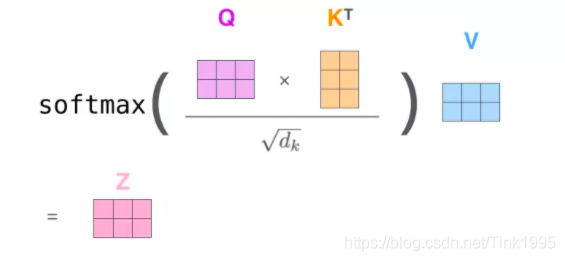

例如上图是self-attention的一个例子:
我们想知道这句话中的its,在这句话里its指代的是什么,与哪一些单词相关,那么就可以将its作为Query,然后将这一句话作为Key和Value来计算attention值,找到与这句话中its最相关的单词。通过self-attention我们发现its在这句话中与之最相关的是Law和application,通过我们分析语句意思也十分吻合。
如此引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。正好弥补了attention机制的两个缺点,这就是为何Self Attention逐渐被广泛使用的主要原因。
Transformer原理
如果将Transformer模型看作一个黑盒,在机器翻译任务中,就是将一种语言的一个句子作为输入,然后目标语言作为输出。如果打开Transformer黑盒,那么Transformer本质上就是一个Encoder-Decoder架构。
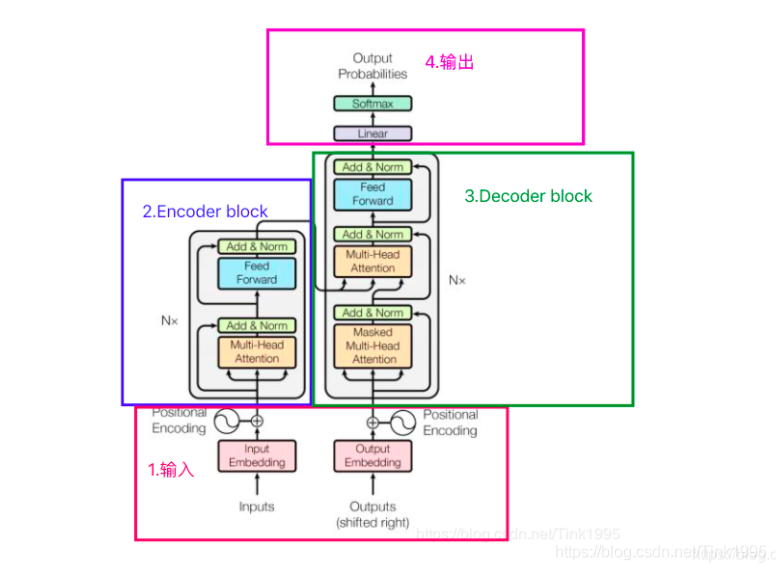
Transformer整体结构
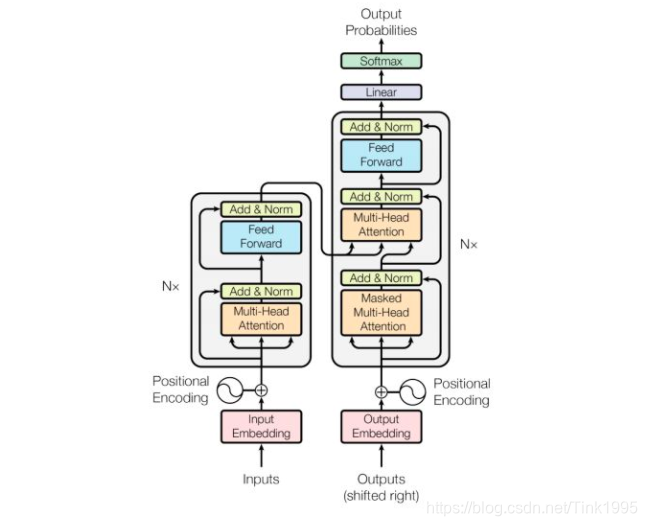
第一眼看这个图,肯定看不懂。接下来一步一步拆解这个图。
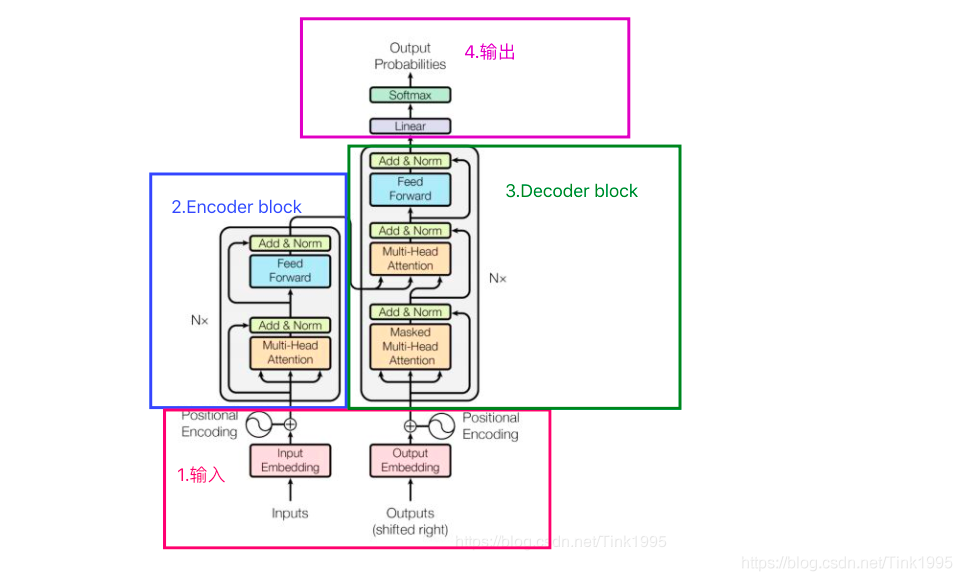
Transformer的结构图拆解开来就是图上四个部分,其中最重要的就是Encoder-Decoder部分,显然Transformer是一个基于Encoder-Decoder框架的模型。接下来逐步介绍各个部分。
Transformer的inputs输入
Transformer输入是一个序列数据,以中英机器翻译“Tom chase Jerry”-“汤姆追逐杰瑞”为例:Encoder的inputs就是“Tom chase Jerry”分词后的词向量。词向量可以是word2vec、GloVe,one-hot编码。

我们注意到,输入inputs embedding后需要给每个word的词向量添加位置编码positional encoding,为什么需要添加位置编码呢?
首先咱们知道,一句话中同一个词,如果词语出现位置不同,意思可能发生翻天覆地的变化,就比如:我欠他100W 和 他欠我100W。这两句话的意思一个地狱一个天堂。可见获取词语出现在句子中的位置信息是一件很重要的事情。但是咱们的Transformer 的是完全基于self-Attention地,而self-attention是不能获取词语位置信息地,就算打乱一句话中词语的位置,每个词还是能与其他词之间计算attention值,就相当于是一个功能强大的词袋模型,对结果没有任何影响。所以在我们输入的时候需要给每一个词向量添加位置编码。
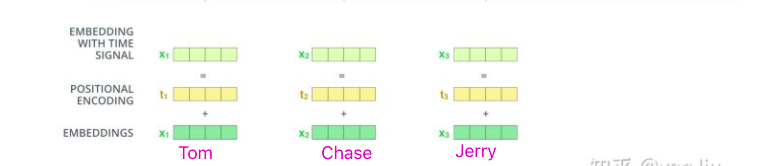
那么positional encoding如何获取呢?
- 通过数据训练得到positional encoding,类似训练学习词向量。Google在之后的bert中的positional encoding便是通过训练得到的。
- 《Attention Is All You Need》论文中Transformer使用的是正余弦位置编码。 位置编码通过使用不同频率的正弦、余弦函数生成,然后和对应的位置的词向量相加,位置向量维度必须和词向量的维度保持一致。
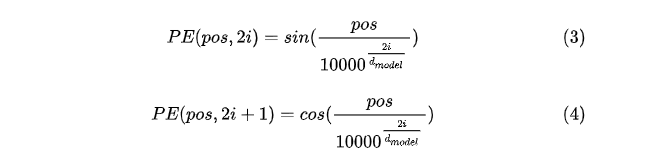
公式解释:pos表示单词在句子中的位置;dmodel表示词向量的维度;2i和2i+1表示奇偶性。至于上面公式怎么得到的,其实不重要。
那么为什么将positional encoding与词向量相加而不是拼接呢?
其实都可以,选择相加而不是拼接主要原因是效率问题。拼接之后维度变大,训练起来相对慢一些,所以选择相加。
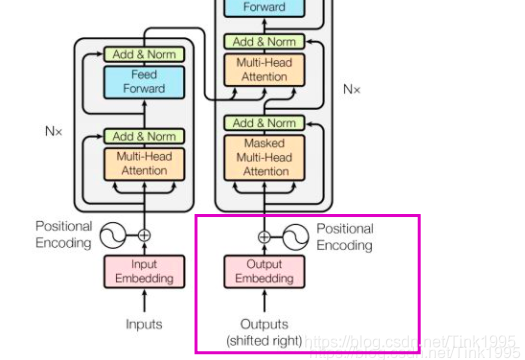
Transformer中的Decoder的输入与Encoder的输入处理方法一致。只是一个接受Source数据,一个接受Target数据。对应中英机器翻译例子,Encoder接收的英文,Decoder接收的是英文对应的中文。Decoder只有在监督训练的时候才会接收Target数据,进行预测的时候不会接收数据。
Transformer的Encoder
Encoder block是由6个Encoder堆叠而成,Nx=6。从Encoder内部结构可以看出,一个Encoder由Multi-Head Attention和全连接神经网络Feed Forward Network构成。
Multi-Head Attention
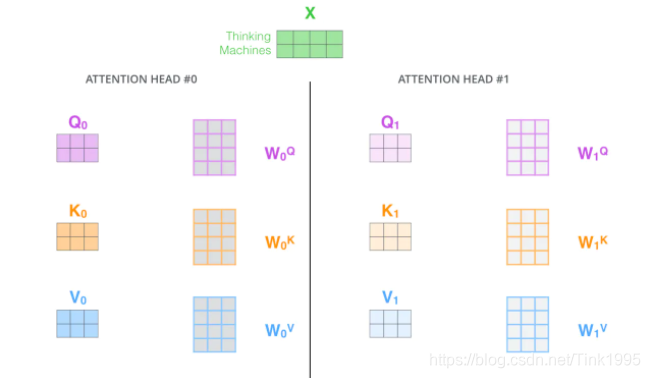
Multi-Head Attention就是在self-attention的基础上,对输入的embedding矩阵,self-attention只使用了一组W来进行变换得到Query、Keys、Values。而Multi-Head Attention使用多组W得到多组Query、Keys和Values,然后每组分别计算得到一个Z矩阵,最后将得到的多个矩阵进行拼接。Transformer里面使用了8组不同的W。
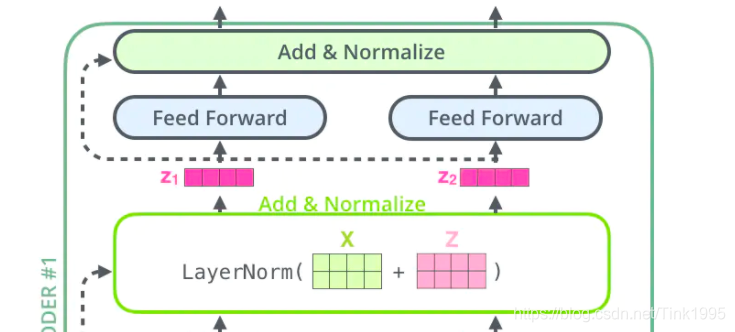
Add&Normalize
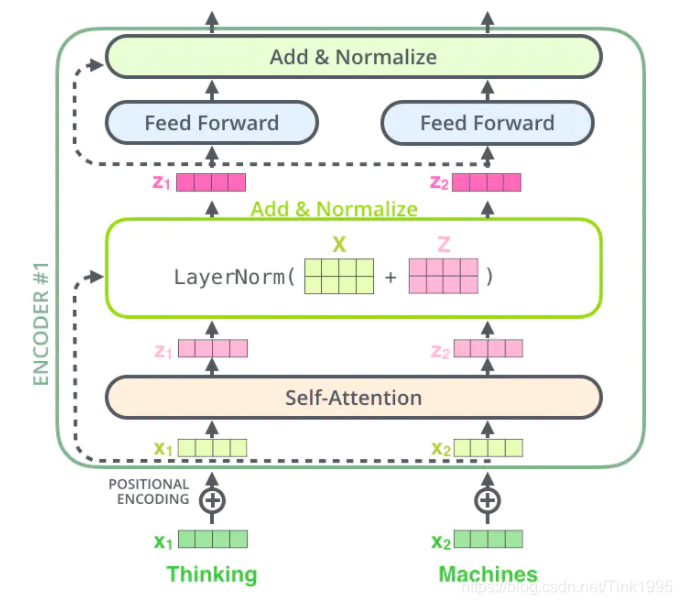
从上图中可以看到,在经过Multi-Head Attention得到矩阵后,并没有直接传入全连接神经网络FNN,而是经过了一步:Add&Normalize。
Add
Add就是在Z的基础上加了一个残差块X,加入残差块X的目的是为了防止在神经网络训练中发生退化问题,退化的意思就是深度神经网络通过增加网络的层数,Loss逐渐减小,然后趋于稳定达到饱和,然后再继续增加网络层数,Loss反而增大。为什么深度神经网络会发生退化?为什么添加残差块能够防止退化问题?残差块是什么?
ResNet残差神经网络:
为什么深度神经网络会发生退化?举个例子,假如某个神经网络的最优网络层数是18层,但是我们在设计的时候并不知道到底多少层是最优解,本着层数越深越好的理念,我们设计了32层,那么32层神经网络中有14层其实是多余的,我们要达到18层神经网络的最优效果,必须保证这多出来的14层网络必须进行恒等映射,恒等映射的意思就是说,输入什么,输出就是什么,可以理解为F(x)=x这样的函数,因为只有进行了这样的恒等映射咱们才能保证这多出来的14层神经网络不会影响我们最优的效果。但是神经网络的参数都是训练出来的,想要保证训练出来的参数能够和精确的完成F(x)=x的恒等映射其实是很困难的。多余的层数较少还好,对效果没有太大的影响,但是多余层数一多,对结果就会有比较大的影响。这时候就提出了ResNet残差神经网络来解决神经网络退化的问题。
残差块是什么?
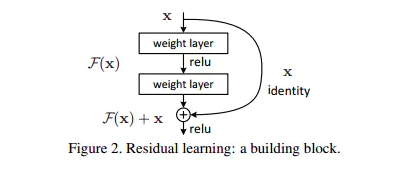
上图就是构造的一个残差块,可以看到X是这一层残差块的输入,也称作F(X)为残差,X为输入值,F(X)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,F(X)加入了这一层输入值X,然后再进行激活后输出。在第二层输出值激活前加入X,这条路径称作shortcut连接。
为什么添加了残差块能防止神经网络退化问题呢?
咱们再来看看添加了残差块后,咱们之前说的要完成恒等映射的函数变成什么样子了。是不是就变成h(X)=F(X)+X,我们要让h(X)=X,那么是不是相当于只需要让F(X)=0就可以了。神经网络通过训练变成0是比变成X容易很多地,因为大家都知道咱们一般初始化神经网络的参数的时候就是设置的[0,1]之间的随机数。所以经过网络变换后很容易接近于0。
并且ReLU能够将负数激活为0,过滤了负数的线性变化,也能够更快的使得F(x)=0。这样当网络自己决定哪些网络层为冗余层时,使用ResNet的网络很大程度上解决了学习恒等映射的问题,用学习残差F(x)=0更新该冗余层的参数来代替学习h(x)=x更新冗余层的参数。
这样当网络自行决定了哪些层为冗余层后,通过学习残差F(x)=0来让该层网络恒等映射上一层的输入,使得有了这些冗余层的网络效果与没有这些冗余层的网络效果相同,这样很大程度上解决了网络的退化问题。
到这里,关于Add中为什么需要加上一个X,要进行残差网络中的shortcut。Transformer中加上的X也就是Multi-Head Attention的输入,X矩阵。
Normalize
为什么要进行Normalize呢?在神经网络进行训练之前,都需要对于输入数据进行Normalize归一化,目的有二:1、能加快训练速度。2、提高训练的稳定性。
为什么使用Layer Normalization(LN)而不使用Batch Normalization(BN)呢?
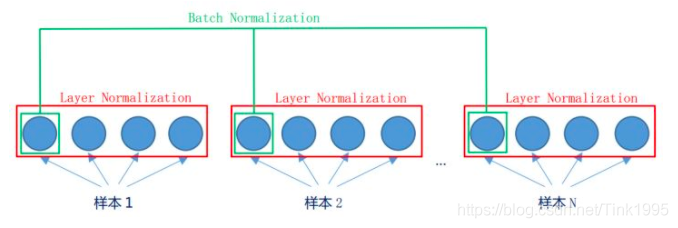
先看图,LN是在同一个样本中不同神经元之间进行归一化,而BN是在同一个batch中不同样本之间的同一位置的神经元之间进行归一化。
BN是对于相同的维度进行归一化,但是NLP中输入的都是词向量,一个300维的词向量,单独去分析它的每一维是没有意义地,在每一维上进行归一化也是适合地,因此这里选用的是LN。
Feed-Forward Networks
全连接公式如下:
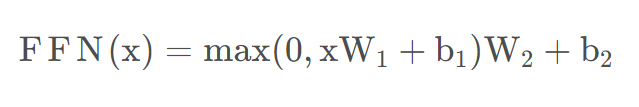
这里的全连接层是一个两层的神经网络,先线性变化,然后ReLU非线性,再线性变化。这里的 x是Multi-Head Attention的输出Z。经过全连接层后再经过Add&Normalize(同上面的Normalize),输入下一个Encoder中,经过6个Encoder后输入到Decoder中。
Transformer的Decoder
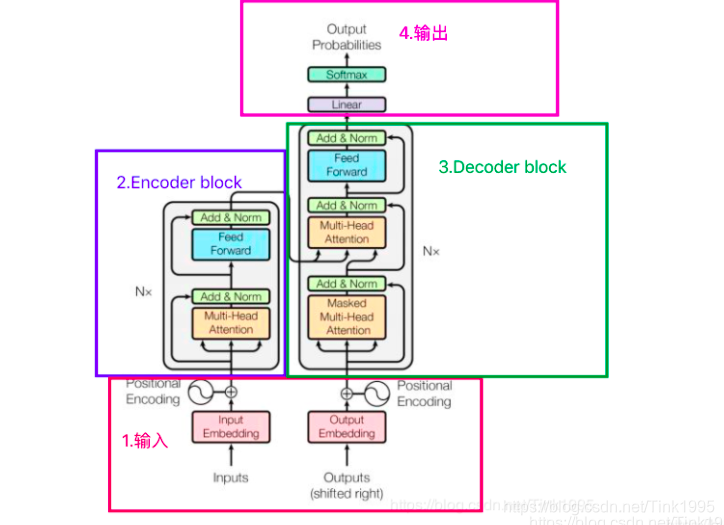
Decoder block也是由6个decoder堆叠而成,Nx=6。上图3中的灰框部分就是一个decoder的内部结构,从图中我们可以看出一个decoder由Masked Multi-Head Attention,Multi-Head Attention 和 全连接神经网络FNN构成。比Encoder多了一个Masked Multi-Head Attention,其他的结构与encoder相同。
Transformer Decoder的输入
Decoder的输入分为两类:
- 一种是训练时的输入。训练时的输入就是已经准备好的Target数据。
- 一种是预测时的输入。一开始输入的是起始符,然后每次输入是上一时刻Transformer的输入。
Masked Multi-Head Attention
与Encoder的Multi-Head Attention计算原理一样,只是多加了一个mask码。mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。为什么需要添加这两种mask码呢?
- padding mask:因为每个批次输入序列长度是不一样,也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0! - sequence mask:sequence mask 是为了使得 decoder 不能看见未来的信息。对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。这在训练的时候有效,因为训练的时候每次我们是将target数据完整输入进decoder中地,预测时不需要,预测的时候我们只能得到前一时刻预测出的输出。那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
基于Encoder-Decoder的Multi-Head Attention
Encoder中的Multi-Head Attention是基于Self-Attention地,Decoder中的第二个Multi-Head Attention就只是基于Attention,它的输入Quer来自于Masked Multi-Head Attention的输出,Keys和Values来自于Encoder中最后一层的输出。
为啥Decoder中要搞两个Multi-Head Attention呢?
个人理解是第一个Masked Multi-Head Attention是为了得到之前已经预测输出的信息,相当于记录当前时刻的输入之间的信息的意思。第二个Multi-Head Attention是为了通过当前输入的信息得到下一时刻的信息,也就是输出的信息,是为了表示当前的输入与经过encoder提取过的特征向量之间的关系来预测输出。
经过了第二个Multi-Head Attention之后的Feed Forward Network与Encoder中一样,然后就是输出进入下一个decoder,如此经过6层decoder之后到达最后的输出层。
Transformer的输出
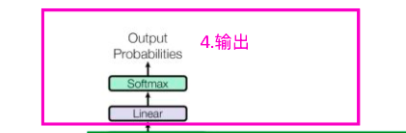
Output如图中所示,首先经过一次线性变换,然后Softmax得到输出的概率分布,然后通过词典,输出概率最大的对应的单词作为我们的预测输出。
Transformer优缺点
优点:
1.效果好
2.可以并行训练,速度快
3.很好地解决了长距离依赖的问题
缺点:
1.完全基于self-attention,对于词语位置之间的信息有一定的丢失,虽然加入了positional encoding来解决这个问题,但也还存在着可以优化的地方。
疑问
-
Transformer模型怎么用代码实现?
-
Transformer怎么用在计算机视觉方面?
-
Transformer怎么解决我的问题?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号