
【分库分表/读写分离】学习+整理
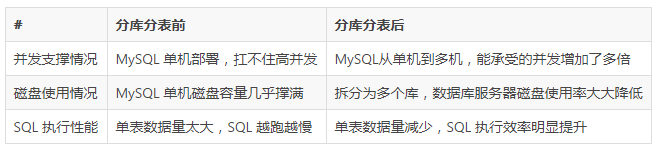
分库分表解决的好处:
举例:
页面(只有商品基本信息,没有商品详情信息):
数据库:
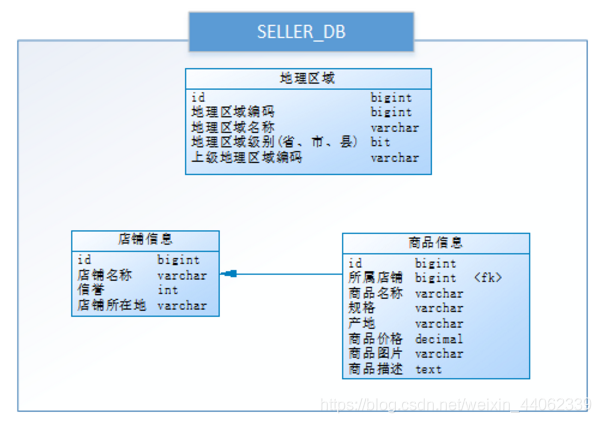
通过以下SQL能够获取到商品相关的店铺信息、地理区域信息:
1 SELECT p.*,r.[地理区域名称],s.[店铺名称],s.[信誉] 2 FROM [商品信息] p 3 LEFT JOIN [地理区域] r ON p.[产地] = r.[地理区域编码] 4 LEFT JOIN [店铺信息] s ON p.id = s.[所属店铺] 5 WHERE p.id = ?
拆分方式:
| 垂直分表 | 以字段为维度,根据冷热数据拆分(如:商品基本信息字段和商品详细信息字段) |
| 垂直分库 | |
| 水平分库 |
以业务为维度,根据不同业务拆分,专库专用(如:商品库,店铺库) 水平分表较水平分库可减少数据库实例,降低运维的成本 |
| 水平分表 |
垂直分表
将访问频次低的商品描述信息单独存放在一张表中,访问频次较高的商品基本信息单独放在一张表中。
用户在浏览商品列表时,只有对某商品感兴趣时才会查看该商品的详细描述。因此,商品信息中商品描述字段访问频次较低,且该字段存储占用空间较大,访问单个数据IO时间较长;商品信息中商品名称、商品图片、商品价格等其他字段数据访问频次较高。
由于这两种数据的特性不一样,因此他考虑将商品信息表拆分如下:
将访问频次低的商品描述信息单独存放在一张表中,访问频次较高的商品基本信息单独放在一张表中。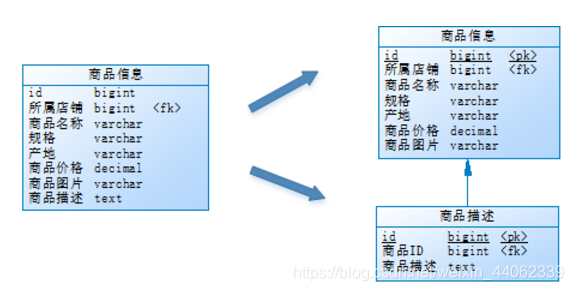
商品列表可采用以下sql:
1 SELECT p.*,r.[地理区域名称],s.[店铺名称],s.[信誉] 2 FROM [商品信息] p 3 LEFT JOIN [地理区域] r ON p.[产地] = r.[地理区域编码] 4 LEFT JOIN [店铺信息] s ON p.id = s.[所属店铺] 5 WHERE...ORDER BY...LIMIT...
需要获取商品描述时,再通过以下sql获取:
1 SELECT * 2 FROM [商品描述] 3 WHERE [商品ID] = ?
垂直分表定义:将一个表按照字段分成多表,每个表存储其中一部分字段。
它带来的提升是:
1.为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
2.充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
为什么大字段IO效率低:第一是由于数据量本身大,需要更长的读取时间;第二是跨页,页是数据库存储单位,很多查找及定位操作都是以页为单位,单页内的数据行越多数据库整体性能越好,而大字段占用空间大,单页内存储行数少,因此IO效率较低。第三,数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
一般来说,某业务实体中的各个数据项的访问频次是不一样的,部分数据项可能是占用存储空间比较大的BLOB或是TEXT。例如上例中的商品描述。所以,当表数据量很大时,可以将表按字段切开,将热门字段、冷门字段分开放置在不同库中,这些库可以放在不同的存储设备上,避免IO争抢。垂直切分带来的性能提升主要集中在热门数据的操作效率上,而且磁盘争用情况减少。
通常我们按以下原则进行垂直拆分:
- 把不常用的字段单独放在一张表;
- 把text,blob等大字段拆分出来放在附表中;
- 经常组合查询的列放在一张表中;
垂直分库
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是始终限制在一台服务器,库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
经过思考,他把原有的SELLER_DB(卖家库),分为了PRODUCT_DB(商品库)和STORE_DB(店铺库),并把这两个库分散到不同服务器,如下图: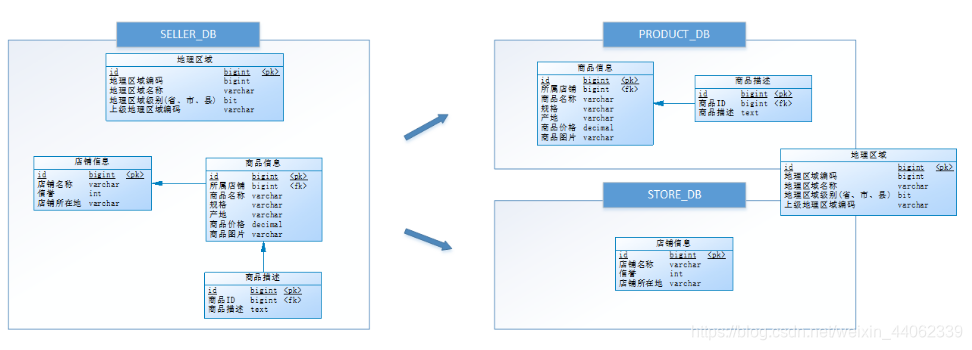
由于商品信息与商品描述业务耦合度较高,因此一起被存放在PRODUCT_DB(商品库);而店铺信息相对独立,因此单独被存放在STORE_DB(店铺库)。
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
它带来的提升是:
-
解决业务层面的耦合,业务清晰
-
能对不同业务的数据进行分级管理、维护、监控、扩展等
-
高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
水平分库
经过垂直分库后,数据库性能问题得到一定程度的解决,但是随着业务量的增长,PRODUCT_DB(商品库)单库存储数据已经超出预估。粗略估计,目前有8w店铺,每个店铺平均150个不同规格的商品,再算上增长,那商品数量得往1500w+上预估,并且PRODUCT_DB(商品库)属于访问非常频繁的资源,单台服务器已经无法支撑。此时该如何优化?
再次分库?但是从业务角度分析,目前情况已经无法再次垂直分库。
尝试水平分库,将店铺ID为单数的和店铺ID为双数的商品信息分别放在两个库中。
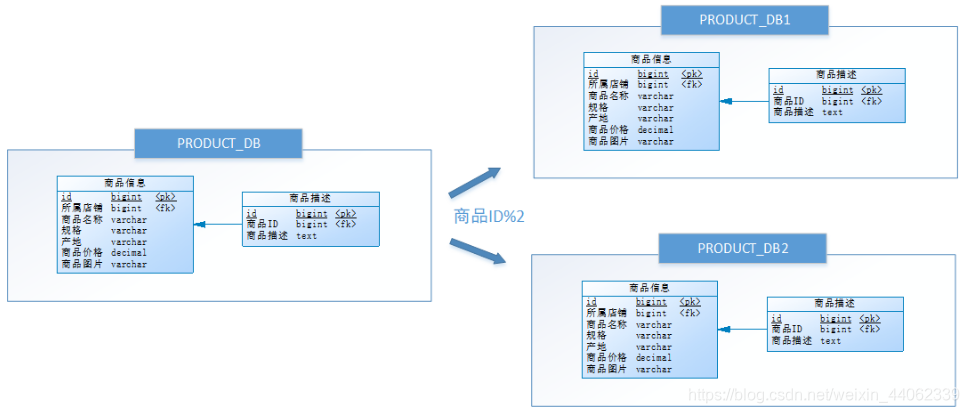
也就是说,要操作某条数据,先分析这条数据所属的店铺ID。如果店铺ID为双数,将此操作映射至RRODUCT_DB1(商品库1);如果店铺ID为单数,将操作映射至RRODUCT_DB2(商品库2)。此操作要访问数据库名称的表达式为RRODUCT_DB[店铺ID%2 + 1] 。
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
垂直分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构
它带来的提升是:
- 解决了单库大数据,高并发的性能瓶颈。
- 提高了系统的稳定性及可用性。
稳定性体现在IO冲突减少,锁定减少,可用性指某个库出问题,部分可用`
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
水平分表
按照水平分库的思路对他把PRODUCT_DB_X(商品库)内的表也可以进行水平拆分,其目的也是为解决单表数据量大的问题,如下图: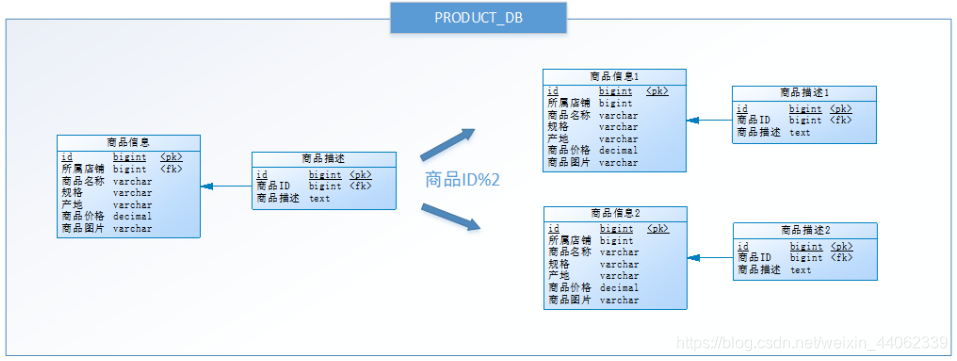
与水平分库的思路类似,不过这次操作的目标是表,商品信息及商品描述被分成了两套表。如果商品ID为双数,将此操作映射至商品信息1表;如果商品ID为单数,将操作映射至商品信息2表。此操作要访问表名称的表达式为商品信息[商品ID%2 + 1] 。
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
它带来的提升是:
-
优化单一表数据量过大而产生的性能问题
-
避免IO争抢并减少锁表的几率
库内的水平分表,解决了单一表数据量过大的问题,分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
总结
垂直分表:可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
垂直分库:可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。
水平分库:可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题(数据路由问题后边介绍)。
水平分表:可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
转:https://blog.csdn.net/weixin_44062339/article/details/100491744
分库分表引发的问题:
1、分布式事务问题:?下面要提的ShardingJDBC无法解决
2、跨节点关联查询问题:连接查询
3、跨节点分页、排序问题:合并多个查询结果之后再分页或者排序
4、主键避重问题:全局主键
5、公共表问题(如城市表):每个库都有一个公共表,分别去操作
分库分表框架-Sharding-JDBC:
Sharding-JDBC主要是操作分库和分的表。核心功能是数据分页和读写分离。透明的使用JDBC访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及其数据如何分布。

架构图:
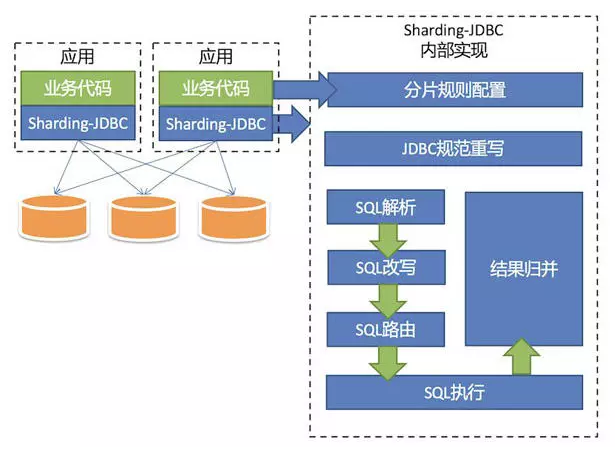
分片规则配置:
1、数据源
2、配置数据节点(库,表)
3、主键生成策略(全局主键-SNOWFLAKE雪花算法)
4、分片策略(分片键+分片算法)
基于Spring boot的规则配置
sharding.jdbc.datasource.names=test0,test1
sharding.jdbc.datasource.test0.type=org.apache.commons.dbcp2.BasicDataSource
sharding.jdbc.datasource.test0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.test0.url=jdbc:mysql://localhost:3306/test0
sharding.jdbc.datasource.test0.username=root
sharding.jdbc.datasource.test0.password=123456
sharding.jdbc.datasource.test1.type=org.apache.commons.dbcp2.BasicDataSource
sharding.jdbc.datasource.test1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.test1.url=jdbc:mysql://localhost:3306/test1
sharding.jdbc.datasource.test1.username=root
sharding.jdbc.datasource.test1.password=123456
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=test$->{0..1}.t_order$->{0..1} <!--Groovy表达式,代表$的取值为0到1-->
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order.key-generator.column=order_id
基于Spring命名空间的规则配置
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:sharding="http://shardingsphere.apache.org/schema/shardingsphere/sharding" xmlns:bean="http://www.springframework.org/schema/util" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://shardingsphere.apache.org/schema/shardingsphere/sharding http://shardingsphere.apache.org/schema/shardingsphere/sharding/sharding.xsd http://www.springframework.org/schema/util https://www.springframework.org/schema/util/spring-util.xsd" default-lazy-init="false"> <!-- 配置多数据源 --> <bean id="db_test_0" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close" primary="false"> <property name="driverClassName" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://${jdbc.sharding.addr}/db_test_0?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull" /> <property name="username" value="${jdbc.sharding.username}" /> <property name="password" value="${jdbc.sharding.password}" /> <property name="initialSize" value="${druid.initialSize}"/> <property name="maxActive" value="${druid.maxActive}"/> <property name="maxWait" value="${druid.maxWait}"/> <property name="validationQuery" value="SELECT 'x'" /> <property name="testWhileIdle" value="true" /> <property name="timeBetweenEvictionRunsMillis" value="60000 " /> <property name="testOnBorrow" value="false" /> <property name="testOnReturn" value="false" /> </bean> <bean id="db_test_1" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close" primary="false"> <property name="driverClassName" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://${jdbc.sharding.addr}/db_test_1?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull" /> <property name="username" value="${jdbc.sharding.username}" /> <property name="password" value="${jdbc.sharding.password}" /> <property name="initialSize" value="${druid.initialSize}"/> <property name="maxActive" value="${druid.maxActive}"/> <property name="maxWait" value="${druid.maxWait}"/> <property name="validationQuery" value="SELECT 'x'" /> <property name="testWhileIdle" value="true" /> <property name="timeBetweenEvictionRunsMillis" value="60000 " /> <property name="testOnBorrow" value="false" /> <property name="testOnReturn" value="false" /> </bean> <bean id="db_test_2" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close" primary="false"> <property name="driverClassName" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://${jdbc.sharding.addr}/db_test_2?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull" /> <property name="username" value="${jdbc.sharding.username}" /> <property name="password" value="${jdbc.sharding.password}" /> <property name="initialSize" value="${druid.initialSize}"/> <property name="maxActive" value="${druid.maxActive}"/> <property name="maxWait" value="${druid.maxWait}"/> <property name="validationQuery" value="SELECT 'x'" /> <property name="testWhileIdle" value="true" /> <property name="timeBetweenEvictionRunsMillis" value="60000 " /> <property name="testOnBorrow" value="false" /> <property name="testOnReturn" value="false" /> </bean> <!-- 配置分库分表策略,库表各有一个分片策略文件 --> <bean id="dataSourceStrategy" class="com.fangyan.test.dal.strategy.DataSourceStrategy"/> <bean id="dataTableStrategy" class="com.fangyan.test.dal.strategy.DataTableStrategy"/> <sharding:standard-strategy id="databaseStrategy" sharding-column="f_user_id" precise-algorithm-ref="dataSourceStrategy"/> <sharding:standard-strategy id="orderTableStrategy" sharding-column="f_user_id" precise-algorithm-ref="dataTableStrategy"/> <!-- sharding数据源,分三个库,每个库中又分15个表 --> <sharding:data-source id="shardingDataSource"> <sharding:sharding-rule data-source-names="db_test_0,db_test_1,db_test_2"> <sharding:table-rules> <sharding:table-rule logic-table="t_order_info" key-generator-ref="keyGenerator" actual-data-nodes="db_test_$->{0..2}.t_order_$->{0..15}" database-strategy-ref="databaseStrategy" table-strategy-ref="orderTableStrategy" /> </sharding:table-rules> </sharding:sharding-rule> <sharding:props> <prop key="sql.show">false</prop> </sharding:props> </sharding:data-source> <!-- 雪花算法ID生成器,自定义的主键生成器 --> <sharding:key-generator id="keyGenerator" column="order_id" type="SIMPLE" /> </beans>
基于yml的规则配置
spring:
shardingsphere:
datasource: ## 略......
sharding:
tables:
t_order:
## 指定 t_order表的 数据分布情况,配置数据节点
actual-data-nodes: m1.t_order_$->{1..2}
## 指定t_order表的主键列,以及主键生成策略为SNOWFLAKE
key-generator:
column: order_id
## 指定分片策略类型
type: SIMPLE
## 指定t_order的分片策略: 设置分片键和分片算法
table-strategy:
inline:
sharding-column: order_id
## 根据order_id % 2 + 1 的结果,指定t_order的实际表
algorithm-expression: t_order_$->{order_id % 2 +1}
sharding-jdbc提供了两种主键生成策略UUID、SNOWFLAKE ,默认使用SNOWFLAKE,还抽离出分布式主键生成器的接口org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator,方便用户自行实现自定义的自增主键生成器。
自定义主键生成器
public class SimpleShardingKeyGenerator implements ShardingKeyGenerator { private AtomicLong atomic = new AtomicLong(0); @Getter @Setter private Properties properties = new Properties(); @Override public Comparable<?> generateKey() { return atomic.incrementAndGet(); } @Override public String getType() { //声明类型 return "SIMPLE"; } }
新增:新增的时候,主键不用赋值了,由雪花算法自动生成
查询:当查询的数据涉及多个库表,真实的查询sql会在多个库表中查询,执行了多次查询。
执行流程分析:
1、解析SQL,获取分片键对应的字段的值
2、通过分片策略计算分片值确定库表(逻辑表解析成真实表,并且解析到对应的数据源和表上。)
3、根据分片值改写SQL,改写后的SQL是要执行的真实SQL
4、执行改写后的真实SQL
5、将SQL的执行结果合并返回
结果归并:遍历、排序、分组、分页、聚合
1、内存归并:所有结果集在内存中进行合并
2、流水式归并:一边处理,一边归并
3、装饰者归并:对归并结果集增强
基本概念:
绑定表:分片键相同的两个表互为绑定表关系(如:商品基本信息表及详细信息表)。绑定表查询不会笛卡尔积,查询效率高。
广播表:公共表
广播路由:没有分片键,所有的库表都执行SQL
读写分离 :
一句话概括,读写分离是为了解决数据库读的瓶颈问题的。数据库包含主库和从库,主库负责写,从库负责读。
Sharding-JDBC只负责Sql路由,不负责主从库之间的数据同步。mysql提供主从数据同步机制。
为什么要做主从复制:
- 在业务复杂的系统中,有这么一个情景,有一句sql语句需要锁表,导致暂时不能使用读的服务,那么就很影响运行中的业务,使用主从复制,让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运行。
- 做数据的热备,主库宕机后能够及时替换主库,保证业务可用性。
- 架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
MySQL主从复制的流程

- 主库db的更新事件(update、insert、delete)被写到binlog
- 主库创建一个binlog dump thread,把binlog的内容发送到从库
- 从库启动并发起连接,连接到主库
- 从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
- 从库启动之后,创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
MySQL主从复制的原理
MySQL主从复制是一个异步的复制过程,主库发送更新事件到从库,从库读取更新记录,并执行更新记录,使得从库的内容与主库保持一致。
binlog:binary log,主库中保存所有更新事件日志的二进制文件。binlog是数据库服务启动的一刻起,保存数据库所有变更记录(数据库结构和内容)的文件。在主库中,只要有更新事件出现,就会被依次地写入到binlog中,之后会推送到从库中作为从库进行复制的数据源。
binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。 对于每一个即将发送给从库的sql事件,binlog输出线程会将其锁住。一旦该事件被线程读取完之后,该锁会被释放,即使在该事件完全发送到从库的时候,该锁也会被释放。
在从库中,当复制开始时,从库就会创建从库I/O线程和从库的SQL线程进行复制处理。
从库I/O线程:当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。 从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relay log文件。
从库的SQL线程:从库创建一个SQL线程,这个线程读取从库I/O线程写到relay log的更新事件并执行。
综上所述,可知:
对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
从库通过创建两个独立的线程,使得在进行复制时,从库的读和写进行了分离。因此,即使负责执行的线程运行较慢,负责读取更新语句的线程并不会因此变得缓慢。比如说,如果从库有一段时间没运行了,当它在此启动的时候,尽管它的SQL线程执行比较慢,它的I/O线程可以快速地从主库里读取所有的binlog内容。这样一来,即使从库在SQL线程执行完所有读取到的语句前停止运行了,I/O线程也至少完全读取了所有的内容,并将其安全地备份在从库本地的relay log,随时准备在从库下一次启动的时候执行语句。
转:https://blog.csdn.net/zai_xia/article/details/90379016
mysql主从同步配置(Windows):
【我的电脑】-右键>【管理】->【服务】->可以找到【mysql】的服务(主从是分开的两个服务)
1、停止mysql服务
2、复制一份mysql安装包作为从库,修改my.ini文件:
①修改port:port=3307
②设置mysql安装目录:basedir=D:\mysql-5.7.25-s1
③设置mysql数据的存放目录:datadir=D:\mysql-5.7.25-s1\data
3、将从库安装为Windows服务:(注意配置文件位置)
进入从库的bin目录下,打开dos命令窗口(shift+右键->在此处打开命令窗口),执行下面的命令:
mysqld install mysqls1 --defaults-file="my.ini文件位置"
mysqls1为自定义的服务名称
4、修改主从库的my.ini文件?
5、重启服务?
6、授权主从复制专用账号?
测试步骤:修改主库数据,从库自动更新修改。
水平分库:根据user_id分库,根据order_id分表
分配策略:
inline:行表达式分片,groovy表达式
standard:标准分片
complex:复合分片
hint:
none:不分片
创建数据库,表结构都相同。
测试查询订单:sql中无user_id,有order_id时,每个库都会执行,表会按表分片算法匹配执行
sql中有user_id,无order_id时,库会按库分片算法匹配执行,每个表都会执行
sql中有user_id,有order_id时,先按库分配算法匹配库,然后去库下面按表分片算法匹配表执行
sql中无user_id,无order_id时,会广播路由,每个库的每个表都会执行
垂直分库:用户信息抽取出来单独一个库
配置:
新建数据源
配置数据节点
配置分配策略
公共表 :如字典表,每个数据库都创建一份,Sharding-JDBC会维护,会给每个库下的公共表发sql执行。
配置:broadcast-tables 每个数据源都会执行sql
字段关联查询测试:
Sharding-JDBC读写分离
1、增加从库的数据源
2、配置主从数据源
3、增加从库数据节点
案例:
1、添加商品
2、商品分页查询
3、商品统计
系统设计时,对数据库垂直分库
数据源配置到所有主从上
配置主从关系
分库策略(水平)
分表策略
绑定表配置-避免笛卡尔积
日志配置
添加成功后,主键会被Sharding-JDBC自动赋值
绑定表是数据方式配置的
Sharding-JDBC会改了我们的分页sql。分页时,如果主键是自增的,可以使用Where id> XX and id <= XX
商品总数:
商品分组:要加order by这样才会流式归并,order by 字段与group by 要是同一个字段。如果没有order by会进行内存归并。
Sharding-JDBC有不执行的sql,开发后需自己测试确认下。
