

sqlserver行转列 pivot
PIVOT函数的格式如下 PIVOT(<聚合函数>([聚合列值]) FOR [行转列前的列名] IN([行转列后的列名1],[行转列后的列名2],[行转列后的列名3],.......[行转列后的列名N])) <聚合函数>就是我们使用的SUM,COUNT,AVG等Sql聚合函数,也就是行转列后计算列的聚合方式。 [聚合列值]要进行聚合的列名 [行转列前的列名]这个就是需要将行转换为列的列名。 [行转列后的列名]这里需要声明将行的值转换为列后的列名,因为转换后的列名其实就是转换前行的值,所以上面格式中的[行转列后的列名1],[行转列后的列名2],[行转列后的列名3],......[行转列后的列名N]其实就是[行转列前的列名]每一行的值
查询表数据如图,查询每门分数都大于80分的人姓名: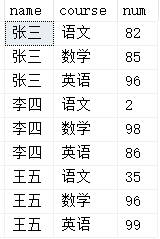
1)用exist关键字查询
select distinct name from Table_CourseNum a where exists(select 1 from Table_CourseNum where name=a.name and course='语文' and num>80) and exists(select 1 from Table_CourseNum where name=a.name and course='数学' and num>80) and exists(select 1 from Table_CourseNum where name=a.name and course='英语' and num>80)
2)第一种方法感觉比较偏,有想过用partition by分组排序函数

select * from ( select ROW_NUMBER() over(partition by Name order by num desc) cnt,* from Table_CourseNum where num>80 ) a where a.cnt=(select count(0) from (select distinct course from Table_CourseNum) t) --和下边写法差不多 select * from ( select name,count(0) cnt from Table_CourseNum where num>80 group by name ) a where a.cnt>=(select count(0) from (select distinct course from Table_CourseNum) t)
3)第三种写法就行转列了
select * from ( select * from Table_CourseNum pivot(sum(num) for course in ([语文],[数学],[英语])) t ) a where 语文>80 and 数学>80 and 英语>80
参考partitionby:https://www.cnblogs.com/zhangchengye/p/5473860.html
参考pivot:https://www.cnblogs.com/net-study/p/10396368.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决
· 提示词工程——AI应用必不可少的技术