机器学习(吴恩达)视频学习记录p1-p50
 纯属个人的学习记录,可能不具有加强理解的效果,但可以搭配视频食用,或许能知晓每节课大概讲的内容,从而提高学习效率!
纯属个人的学习记录,可能不具有加强理解的效果,但可以搭配视频食用,或许能知晓每节课大概讲的内容,从而提高学习效率!
由于之前都是txt记录的,所以可能比较简陋
学算法应学原理,学工程应学应用。
(因为还要自己设计算法 这也是门槛更高的原因吧 上一行转自y总) 调api 调包侠
过程中待看待理解的博客、文章、概念、疑问
后期会删除 目前边学边补充
或某个重要概念暂时理解不了,会放在这里,避免拖进度
但愿不会攒太多
正文(p1-p50)
避免太长
--------p1
web automation 网络和自动化技术发展 -->数据集(data sets)
Natural Language Processing (NLP) 自然语言处理
Computer Vision 计算机视觉
a well accepted definition 统一定义
--------p2
引用了跳棋的例子 摘录两个机器学习的定义
task 任务 -- experience经验 -- performance measure性能度量
学习算法:(无)监督学习 supervised learning 我们teach / let learn
reinforcement learing 强化学习
recommender systems 推荐系统
--------p3
supervised learning right answers given regression problem 回归问题
discrete values 离散值
Classification problem 分类问题【discrete valued output(0or1)】 举了恶性良性肿瘤的问题 离散的输出值
xy轴 Age Tumor Size 双变量 特征
如何处理无穷多的特征 支持向量机算法 SVM(哈哈,卖关子了)
利用算法来预测 回归问题 回归:目标 预测连续性输出
分类问题 : 目标 预测离散值输出
--------p4 无监督学习
unsupervised learning:都具有相同label或都没有
将数据集分为两个簇(cluster): a clustering algorithm 聚类算法
应用:大型计算机集群,人物关系网,市场客户分类,天文学星云分布分析
鸡尾酒会问题:计算机语音识别领域
svd 一行核心代码即可
[W,s,v] = svd((repmat(sum(x.x,1),size(x,1),1).x)*x');
14年的视频 采用Otcave(后期再迁移到C++/JAVA 高效)或matlab
--------p5 模型描述
回归:预测一个具体的数值输出 predict a real-valued output
小写字母m 训练样本的数量 the number of training example
x = "input" variable / features
y = "output" variable / "target" variable
x^(i) 上标i是训练集的一个索引
小写h: hypoth假设函数(早期,标准术语) function 函数
一元线性回归 (模型)
--------p6 代价函数
the cost function 代价函数
minimize 预测值和实际值的差的平方误差和 前面的1/2m 据弹幕说是为了求导时消掉平方
notation 表达
J(theta0,theta1) 代价函数 平方误差函数
--------p7 代价函数(一)
To recap回顾一下
确实没必要为了一点点额外补充去开弹幕,一堆评价讲的慢的,哈哈
本节相当简单
--------p8 代价函数(二)
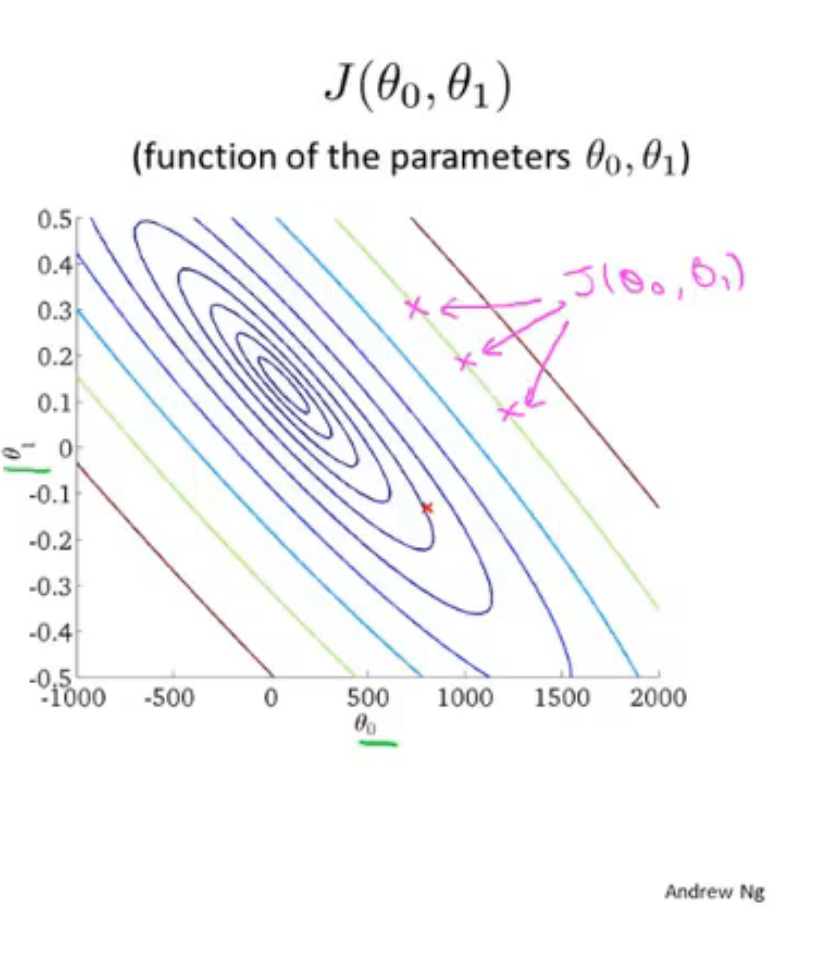
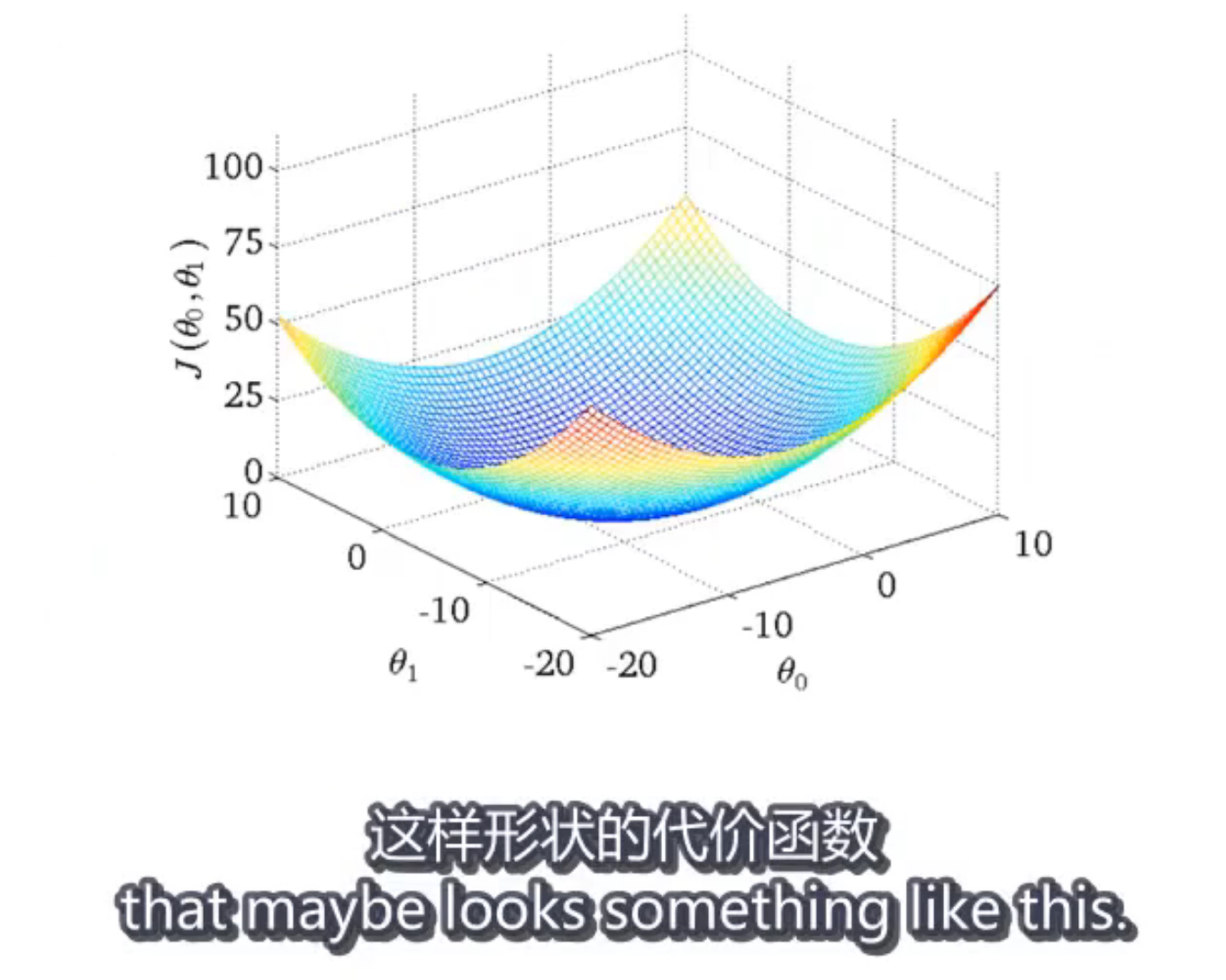
麻烦,不知道怎么设置图注 就先这样居中and分隔符吧 本来想着分隔符不多余回车可以加粗,但这样会加入目录中,其实也行但不想
呜 改个颜色 居中还得写代码 还是不熟悉操作 跟typora有差异 大概吧 找不到该颜色的鼠标操作或快捷键 font color='red' 尖括号双标签
等高线表示 J 两参数作为x,y轴 椭圆线上的J值相等
相当于从上朝下看这个碗 盆地 中间是最小的
我们真正想要的是高效的算法:自动寻找代价函数J最小值 对应的theta0,1
--------p9 梯度下降

用它最小化任意函数J arbitrary任意的
a local minimum 局部最小值
希望大家能把这个图像想象成一座山
确实 高数里有梯度这个概念
局部最优解 呜 一下子就想到了贪心
convergen 收敛
:=赋值
a learning rate学习率 以多大幅度更新参数
simultaneous update同步更新 实现算法
--------p10 梯度下降知识点总结
就课程目的而言,偏导数符号与d/d theta 1 完全一样
以y=x*x 图像为例, o1=o1-a(postive number) 故向左移 o1=o1-a(negative number) 增大 故向右移
上面一行用于解释偏导数的意义
如果a学习率太大,那么梯度下降可能越过最低点 甚至无法收敛、发散 视频中不震荡的原因,或许是:导数在变大
如果已经在局部最优点 梯度下降将不改变参数的值 导数为0 嗐,我还以为到左右都有可能呢
--------p11 线性回归的梯度下降

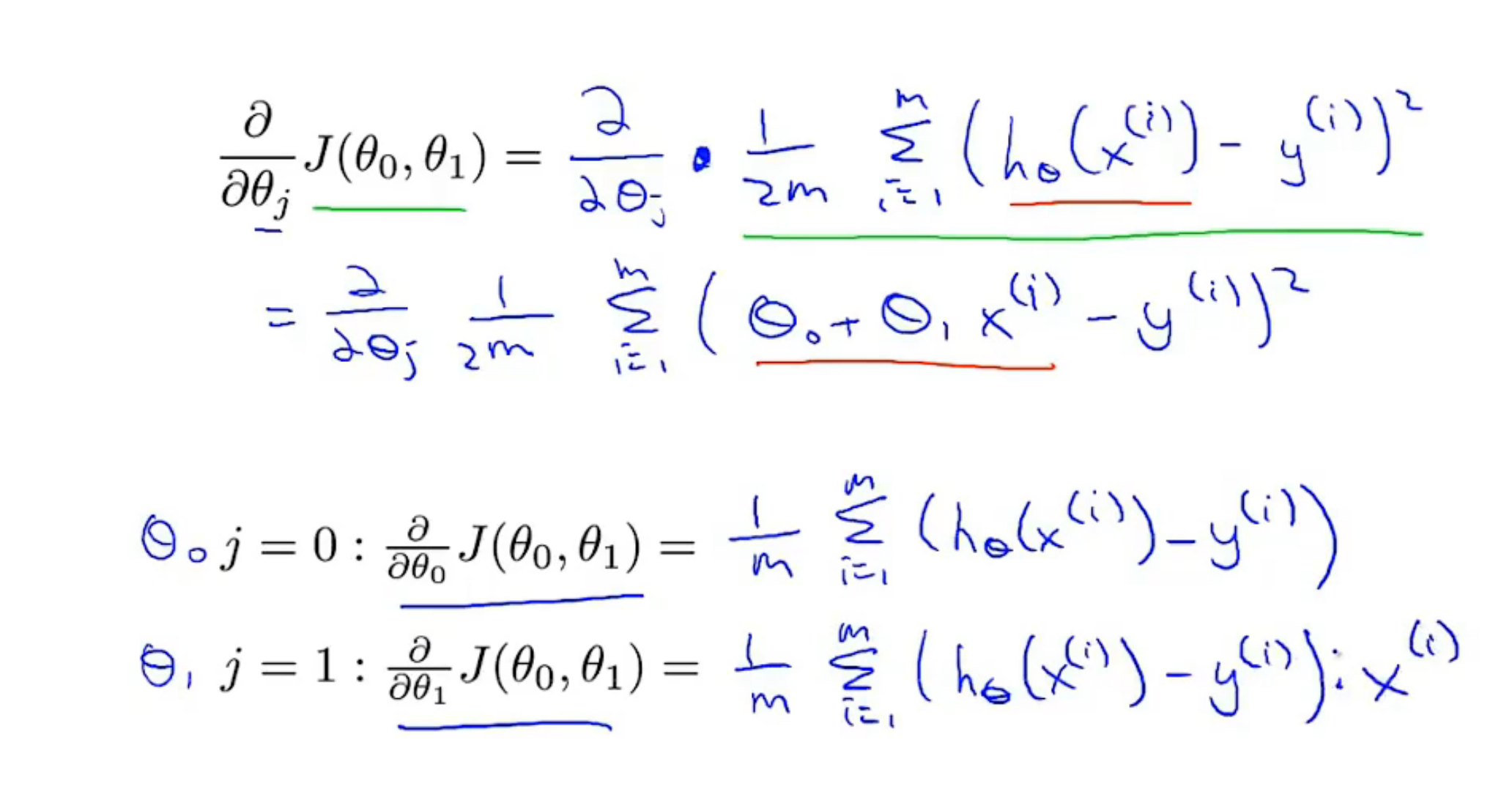
梯度下降+代价函数-->线性回归的算法(用直线模型拟合数据)
Don't worry about it.哈哈
关于o1 o2 的求解没看懂(j=1 2 j是θ下标) 看式子懂了 一个用上面的求导,另一个用下面的(一次函数代入代价函数中)
凸函数 碗状函数 弓形 局部最优解==全局最优解
Batch 梯度下降 遍历look at整个训练集的样本
--------p12 3.1矩阵和向量
据说是线性代数学的不错第3章可以跳过,那就先跳过
--------p18 4.1多功能 最后的一般略懵,但可能是不知道用途吧
4个特征 x^(2)就表示第二行的特征 是一个四维向量
vector 向量
x^(i)_j(j是下标):第i个训练样本中第j个特征量的值
定义额外的第0个特征向量
向量内积 转置
多元线性回归
hθ(x)=θTx(T是上标)= θ0x0+θ1x1+θ2x2+…+θnxn (惯例 使x(i)_0=1 约定)
把上述的参数看为一个n+1维的θ向量
--------p19 4.2多元梯度下降法
如何设定假设的参数
数学也没啥特别能去记的
--------p20 4.3多元梯度下降法演练-特征缩放
gradient descent梯度下降 的 实用技巧
保证 不同的特征取值在相近的范围scale -->能更快地收敛
例如两个特征地范围差距非常大 画出的椭圆(J(θ)的等值线)会十分瘦长(忽略θ0)
例如 房屋面积范围a<=2000 卧室个数b 1~5
特征缩放即为 a/=2000 b/=5
通常 把特征的取值约束到-1~+1的范围 a little bigger is fine
-0.0001 小数点后一堆0念哦哦哦
均值归一化 normalization
标准化 减去平均值后再除 如常见的房屋面积为1000 卧室数量为2 x1=(size-1000)/2000
x1=(x1-u1)/s1 u1是训练集特征x1的平均值 s1为max-min(这个即可) 或标准差
--------p21 4.4多元梯度下降法演练-学习率
alpha α
debug(调试) choose learning rate α
x轴梯度下降算法的迭代次数 y轴J(θ) 每一步迭代后J(θ)都应该下降
自动收敛测试 tell you 梯度下降算法是否已经收敛 找一个合适的阈值(但不好确定,不如看曲线图),例如一次迭代后J(θ)变化小于1e-3即可判断收敛
若上升图像或下降后又上升循环的图像 通常选择较小的α
to choose α ,try 3X bigger(三的倍数) 0.001 0.003 0.01~~
--------p22 4.5特征和多项式回归
转化:定义一个新特征 例如房屋价格与房屋的长和宽相关,而这两个特征可以相乘合并为面积作为单特征
阶数过高会过拟合,导致不精准 哈哈,对这个有一定体会 之前的知乎问题,问一个数列的规律(男朋友发的什么意思) 下面就一本正经地用多项式分析 哈哈
设计不同的特征 如房屋价格与面积 若用二次函数最后会下降 三次函数或一次函数+根号x(最后的上升更加平缓)
--------p23 4.6正规函数(区别于迭代方法的直接求法) 没看懂式子
m是训练样本数量 n是特征数量数 n+1 化成矩阵x,y
西瓜55p θ=(XT*X)-1 * X^T*y 没讲证明 还有就是自己再线性代数上的知识残缺
弹幕中一直提到最小二乘法
不需要特征缩放
the cost of inverting the matrix逆矩阵计算 O(n^3)特征数量1e4用梯度下降 不然慢
矩阵求逆 高斯消元法
对于线性回归模型 正规方程法可以替代梯度
--------p24 4.7正规方程在矩阵不可逆情况下的解决方法
optional material 选学材料(不可逆情况少见) 较深
不可逆矩阵 称为 奇异或退化矩阵 singular or degenerate matrices
求逆 pinv(pseudo-inverse)伪逆 inv
不可逆(计算机上来说):1.一个特征可用另一个特征表示,则有一个多余 (如换单位) 行列式里两行成比例(线性相关) 则结果为0
2.too many features m>=n 特征太多但训练样本太少 解决方法:delete some features,or use regularization正则化
--------p25 4.8导师的编程小技巧
首先,我想实践,但不想学这两个软件,matlab倒还能接受; 不知道还能做吗,回头查
--------p26 5.1基本操作
https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes
跳过这一章吧 上面的是python作业 (大佬改的)大佬笔记:https://zhuanlan.zhihu.com/p/43478657
https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes 哈哈 同一个人,可看知乎(上一行)
--------p31 5.6矢量 ******
听6.1弹幕讲这节或许有用
计算两个向量的内积 转置其中一个向量 直接乘(见截屏) 从循环转到矩阵运算 数值线性代数库
theta.transpose()*x;
完蛋,第二个的转变没有看懂,以后学了学线性代数再看吧
--------p32 6.1分类
y {0,1} 0:"Negative Class(无)" 1:"Postive Class"
想起来一个函数,忘叫什么了在左边是-1 右边是1 大概
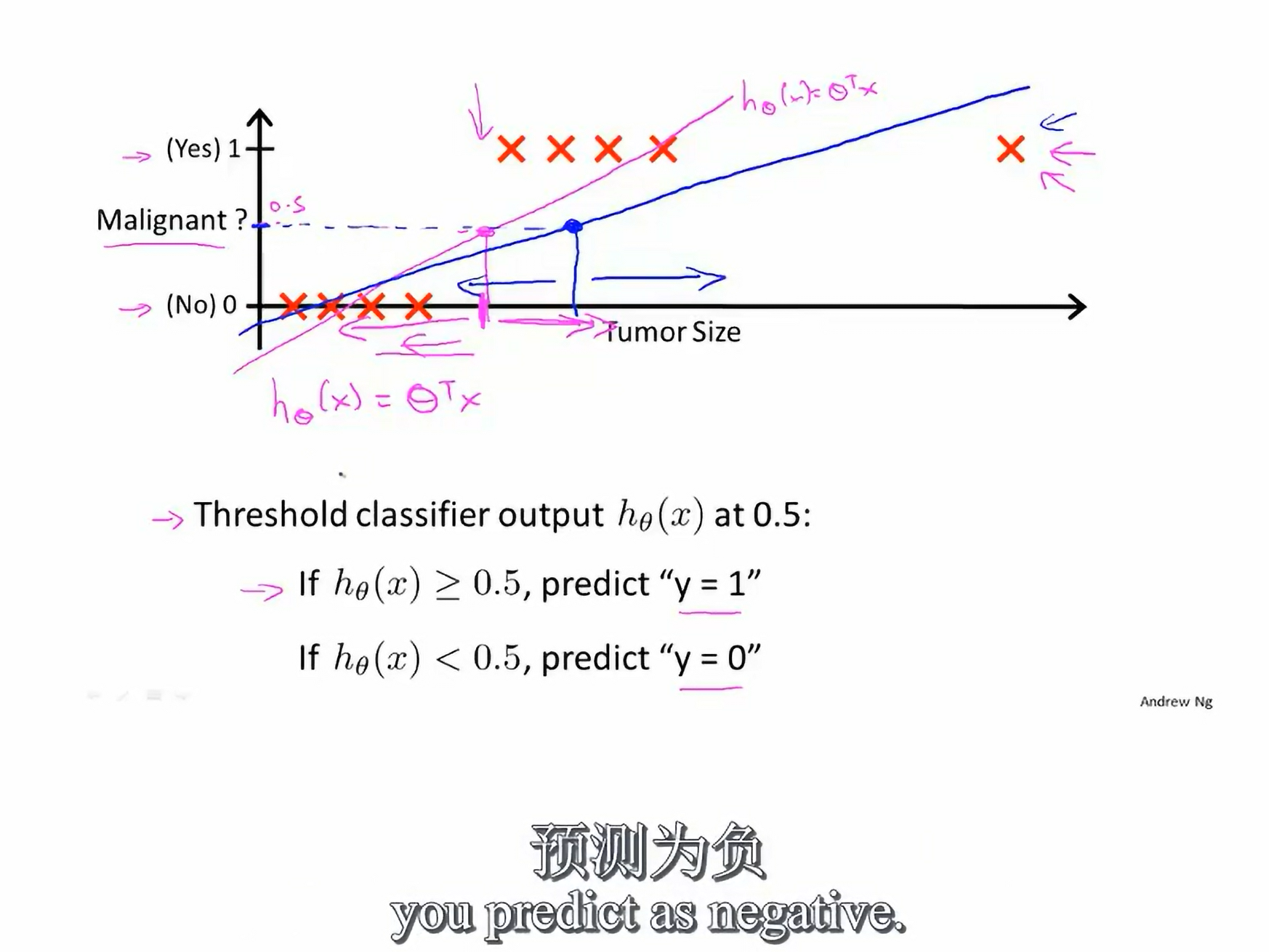
所以把线性回归运用到分类问题里,不是一个好主意
:它的这个证明真的很妙,简洁易懂 阈值 起始点和终点的中点形成直线,与阈值点相交,会偏移,导致不一定分类成功
线性回归 可能会使结果>1或<0

logistic回归算法 不要被回归迷惑 本质是分类算法
--------p33 6.2假设陈述
sigmoid function == logistic function g(z) = 1/(1+e^(-z)) hθ(x) = g(θ^T*x) want: 0<=hθ(x)<=1
感觉看了这么久视频,还是停留在简单概念层面 有点慢了!
--------p34 6.3决策界限 decision boundary
我们不是用训练集来定义的决策边界,我们用训练集来拟合参数θ
--------p35 6.4代价函数
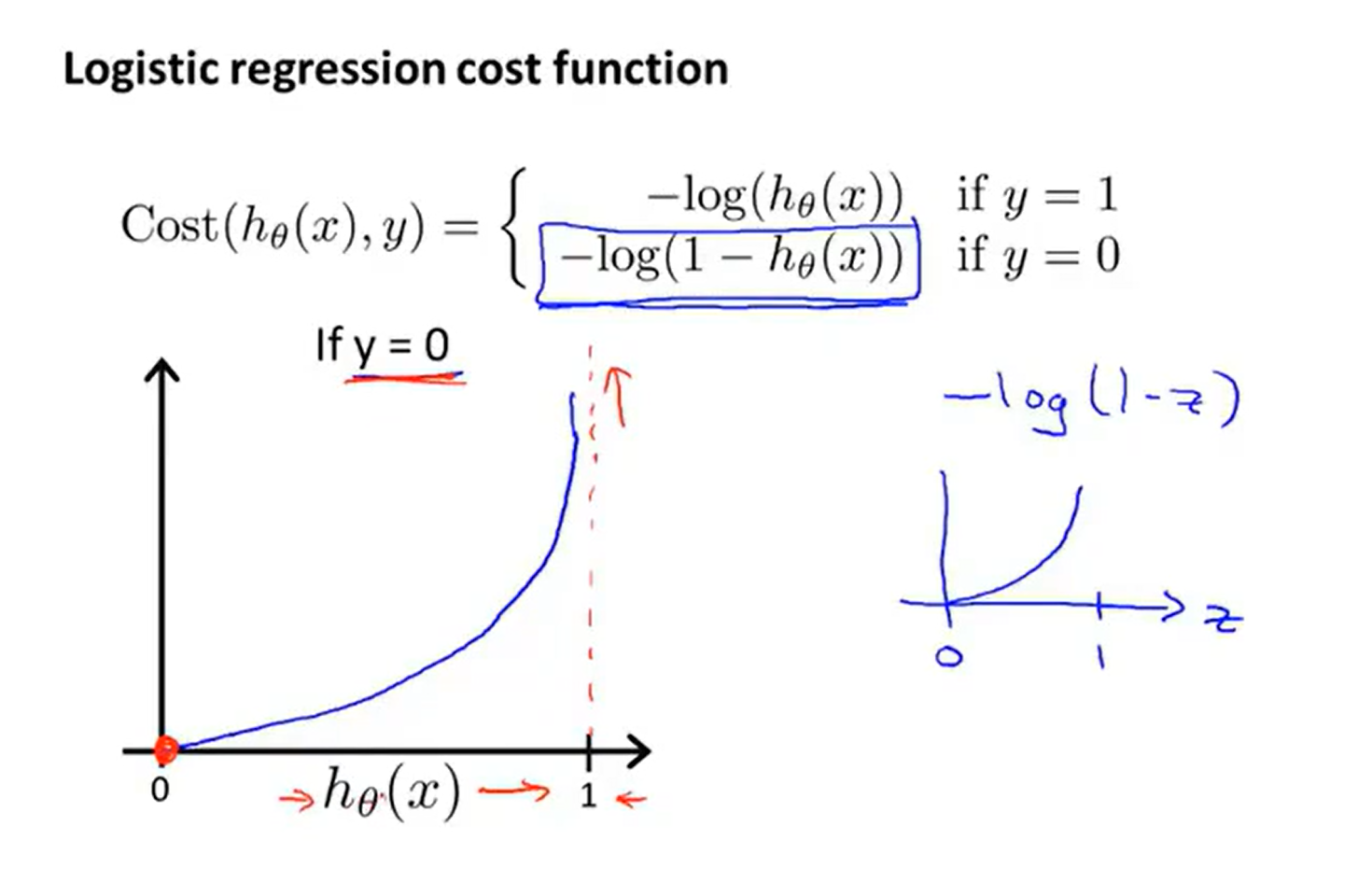
拟合logistic回归模型的参数θ
凸函数:https://www.jianshu.com/p/4883280f666f 即f′′(x)≥0 ,则f(x)是凸函数。 Hessian矩阵的正定性
--------p36 6.5简化代价函数与梯度下降
交叉熵函数
最大似然估计
视频中的代价函数求导:https://blog.csdn.net/JUNJUN_ZHAO/article/details/78564557
没看懂 代入θj的更新公式
线性回归 和 logistic回归 更新公式一致,但本质(定义)不同
--------p37 6.6高级优化
Conjugate gradient共轭梯度法 BFGS L-BFGS 高等数值计算 看弹幕就不学了
线搜索算法
讲述了octave中运行算法的过程
--------p38 6.7多元分类 一对多
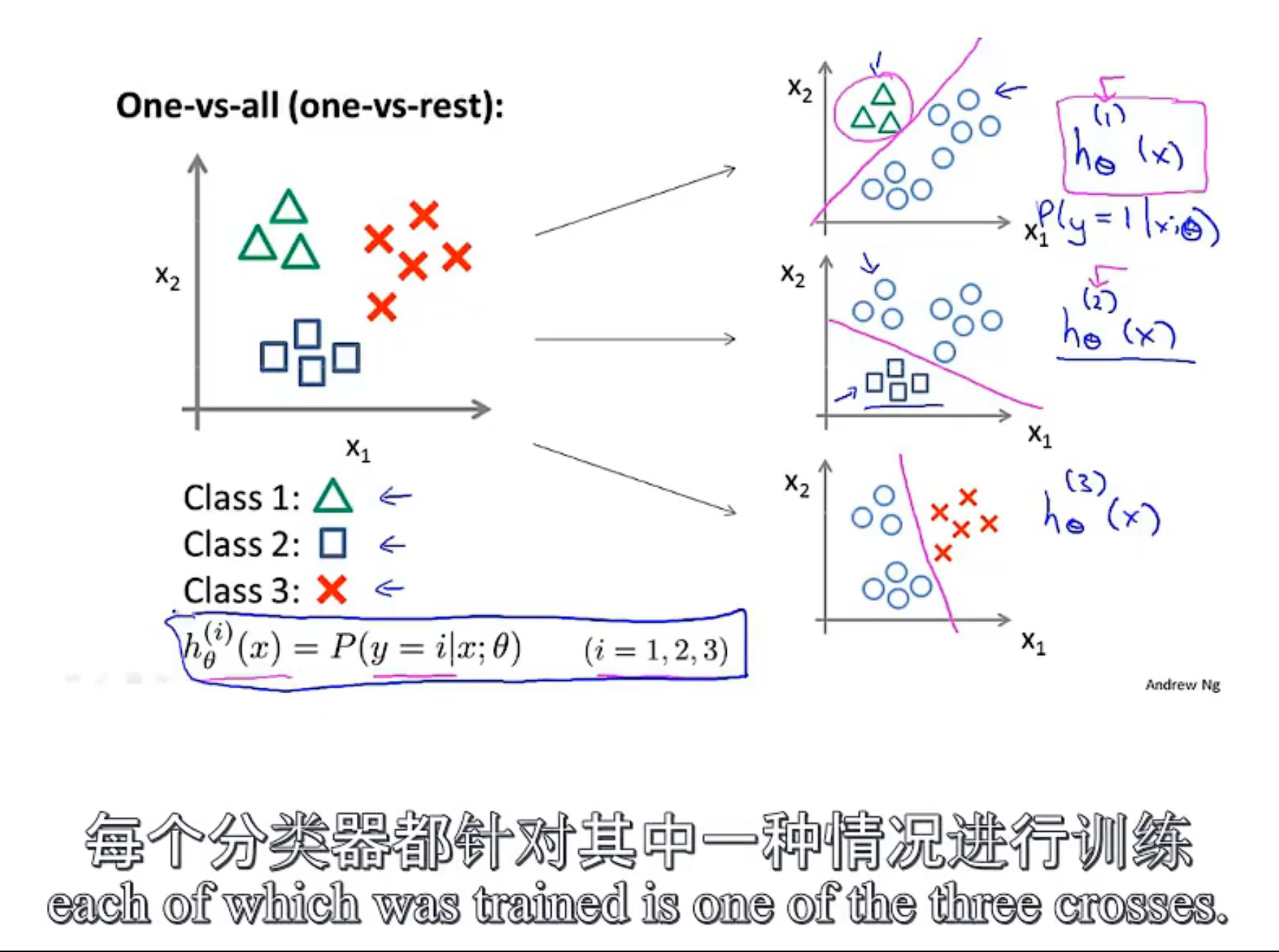
分为多个分类器,其余设为负(每次判断是否是某个样本) 最后再比较每个点的概率来预测属于哪个
--------p39 7.1过拟合问题
哈哈,终于到了
up主推荐
之前高三看B站科普视频看到过 up主:KnowingAI知智(视频很短
再推荐一个up主 3Blue1Brown 相对较长 硬核知识 据说讲的深入浅出 只看过几个视频
high bias 高偏差 欠拟合
high variance 高方差 过拟合 波动
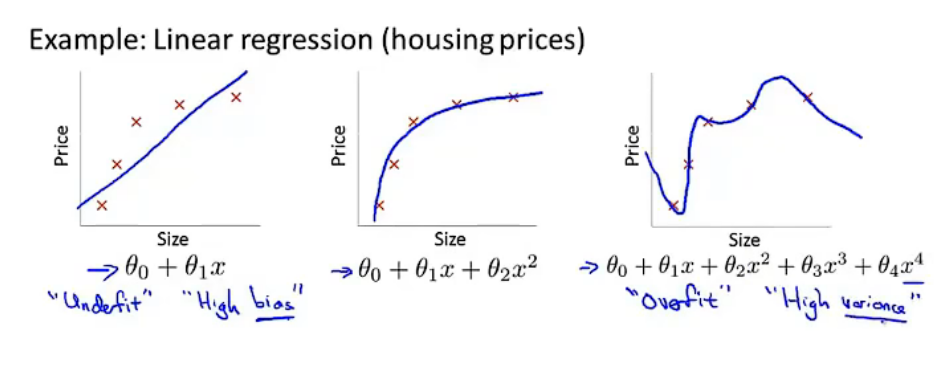
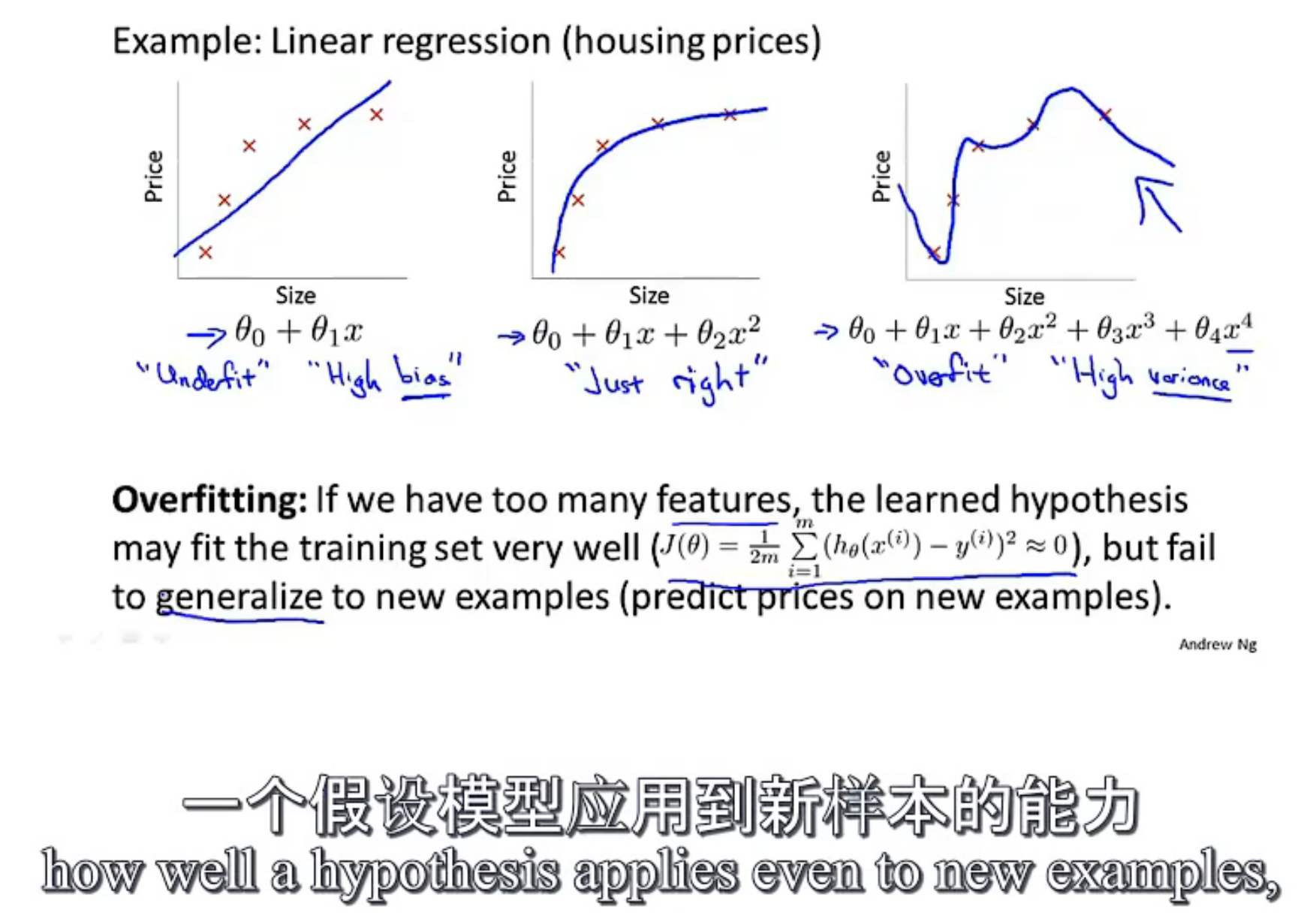
过拟合会导致泛化(上图字幕即为解释)能力弱
直男,暖男,舔狗的区别(弹幕)
哈哈,这例子和弹幕绝了,5参数,四阶多项式
可以画热力图,知道变量之间的相关性,把两两相关性较高的去掉一个,也可以用PCA等降维
人工选择减少变量 正则化
--------p40 7.2代价函数
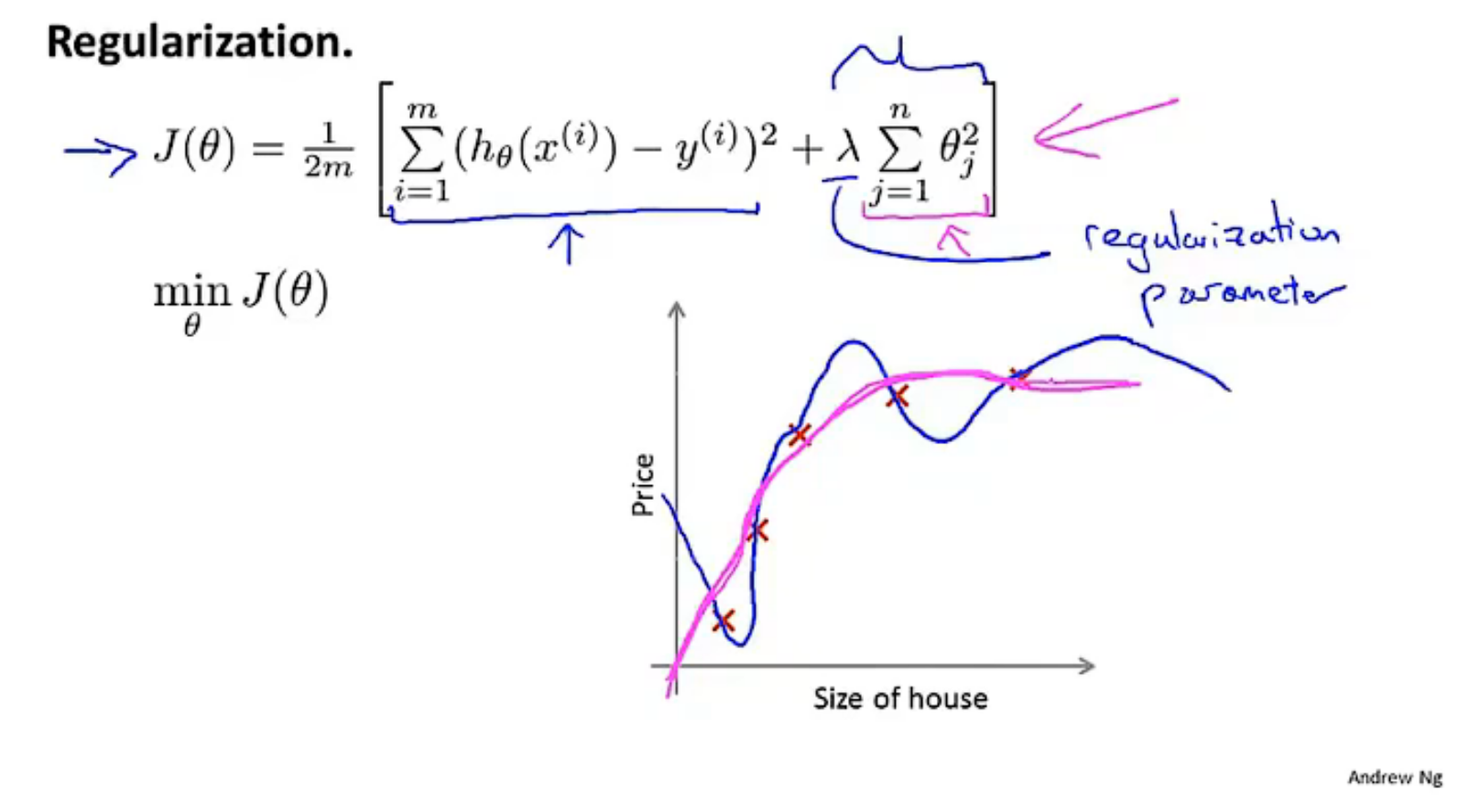

如果λ(lambda)太大 会导致每个θ太小 最终成为水平线
自己用博客记录后,图片的引入更多了,要是能方便地调整大小,如放在左边占一般就更好了
--------p41 7.3线性回归的正则化
拟合线性回归时:梯度下降、正规方程


数学好难
不可逆,奇异,退化
--------p42 7.4Logistic回归的正则化
附录
术语单词
state-of-the-art 前沿的
implement 实现
term 术语
let's say 假设说
svm 支持向量机
LDA 线性判别降维算法
RNN 循环神经网络
CNN 卷积神经网络
我是懒蛋,后来遇到的新词就直接放在每节课里了,后期总结或完善 并加入解释、链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号