哈希表
哈希表是根据关键码值而直接进行访问的数据结构。(Hash的原意是杂凑)
它通过把关键码值映射到表中一个位置(哈希地址)来访问记录,以加快查找的速度。
优点:速度快(插入和查找)
缺点:基于数组,不能有序的遍历
哈希函数(即这个映射函数)是一个映像,因此哈希函数的设定很灵活,只要使得任何关键字由此所得的哈希函数值都落在哈希表长允许范围内即可。
对于不同的关键字,可能得到同一哈希地址,这种现象叫做哈希冲突,而且,一般而言,哈希冲突是不能完全避免的,只能尽可能的去减少。
为了减少哈希冲突,我们应该构造合理的哈希函数和设定一种处理冲突的方法。
哈希函数的构造方法:
①直接定址法:取关键字或关键字的某个线性函数值为哈希地址。
Hash(key) = key 或者 Hash(key) = a × key + b。
但是,该方法产生的哈希表会造成空间大量的浪费,因此这种方法适应性并不强。
比如:
Hash(key) = key

Hash(key) = key-1980
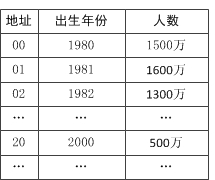
②数字分析法:
假设关机子是以r为基的数,而且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位为组成哈希地址,至于选取数位,原则上是使得到的哈希地址尽量避免产生冲突,选取位数的数据近乎随机。也可以取其中的几位与另外几位的叠加求和后舍去进位作为哈希地址。
再次强调一下,它只适合于所有关键字值已知的情况。
③平方取中法:取关键字平方,然后根据可使用空间的大小,选取平方数中间几位为哈希地址。。
这是一种较常用的构造哈希函数的方法。
Hash(key) = key² 中间几位
因为这种方法的原理是通过取平方扩大差别,平方值的中间几位和这个数的每一位都相关,则对不同的关键字得到的哈希函数值不易产生冲突,由此产生的哈希地址也较为均匀。
④折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
适用于关键字位数很多,而且关键字中每一位上数字分布大致均匀的情况。
⑤除留余数法:取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。
Hash(key) = key MOD p , p≤m
这是一种最简单、最常用的构造哈希函数的方法。
而且在此方法中,对p的选择非常重要,一般是选择不大于表长m的最大质数或不包含小于20的质因数的合数。
⑥随机数法:选择一个随机函数,取关键字的随机函数值作为它的哈希地址。
Hash(key) = random(key)
通常,当关键字长度不等时才用此法构造哈希函数较恰当。
处理哈希冲突的方法:
①开放定址法:
Hi = (Hash(key) + di) MOD m i=1,2....,k(k≤m-1)
m为哈希表长,di为增量序列
对于增量序列的选择有以下三种方法:
a. 线性探测再散列:di=1,2,3,....,m-1
b. 二次探测再散列:di=1²,-1²,2²,-2²,3²,....,±k²(k≤m/2)
c. 伪随机探测再散列:di=伪随机数序列
②再哈希法:很少用
Hi = RHi (key)
RH均是不同的哈希函数,当在冲突时,计算另一个哈希函数的地址,直到不发生冲突,这种方法不易产生“聚集”,但是增加了计算的时间,故很少用。
③链地址法:将所有关键字为同义词的记录存储在同一线性链表中。
把一个哈希值产生冲突关键字放进一个链表里面,当某个哈希值产生冲突了,就把这个关键字放到这个哈希值槽的链表里面。

④建立一个公共溢出区:
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
&:

基于以上提到的两部分,哈希查找的过程即给你一个key值,根据设定的哈希函数去求得哈希地址。
if 在这个位置上没有记录,则查找不成功;
else,if关键字和给定值相等,就查找成功;
else,根虎处理冲突的方法去找“下一地址”,知道哈希表的某个位置空了或者表中所填记录的关键字等于给定值时为止。
在查找过程中需和给定值进行比较的关键字个数取决于下列三个因素:哈希函数、处理冲突的方法、哈希表的装填因子。
在处理冲突方法相同的哈希表中,其平均查找长度依赖于哈希表的装填因子:α=表中填入的记录数/哈希表的长度。
表中已填入的记录越多,再填记录时,发生冲突的可能性就越大。
转载请注明地址:https://www.cnblogs.com/fangxiaoqi/
觉得有帮助的话可以点一下推荐,thanks
相关习题:(写好之后会把链接插上)
- HDU 1280
- HDU 1425
- HDU 3833
- HDU 1496
- HDU 2648
- HDU 2027
- POJ 1200
- POJ 3320
- HDU 6161
- HDU 6046
- HDU 4334
- HDU 1880
- HDU 5782

