


转载:https://www.iteye.com/topic/713770
模版模式
定义
在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模板方法可以使得子类在不改变算法结构的情况下,重新定义算法的某些步骤。
一般用抽象类实现。(也可以回调,比如jdbcTemplate的实现)
通俗点的理解就是 :完成一件事情,有固定的数个步骤,但是每个步骤根据对象的不同,而实现细节不同;就可以在父类中定义一个完成该事情的总方法,按照完成事件需要的步骤去调用其每个步骤的实现方法。每个步骤的具体实现,由子类完成。
UML
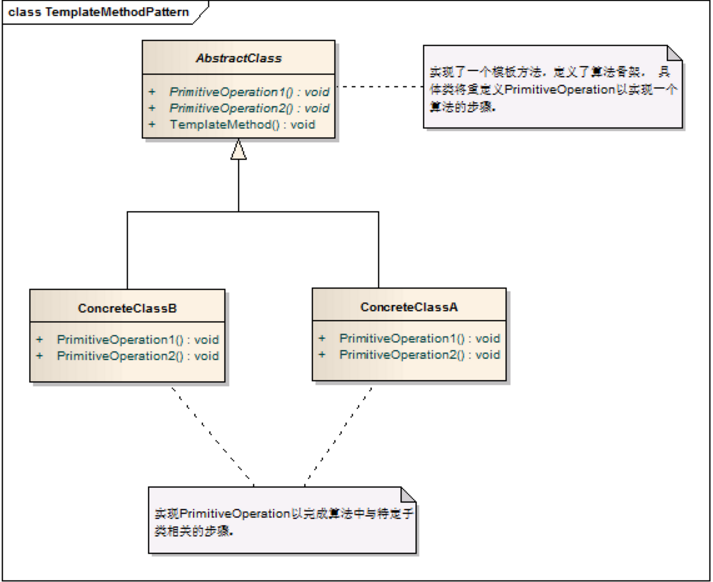
抽象父类(AbstractClass):实现了模板方法,定义了算法的骨架。
具体类(ConcreteClass):实现抽象类中的抽象方法,即不同的对象的具体实现细节。
举例
模板方法(template method)就在spring中被大量使用,如:jdbcTemplate,hibernateTemplate,JndiTemplate以及一些包围的包装等都无疑使用了模板模式,但spring并不是单纯使用了模板方法,而是在此基础上做了创新,配合callback(回调)一起使用,用得极其灵活。
父类是抽象类
public abstract class TemplatePattern { //模板方法 public final void templateMethod(){ method1(); method2();//勾子方法 method3();//抽象方法 } private void method1(){ System.out.println("父类实现业务逻辑"); } public void method2(){ System.out.println("父类默认实现,子类可覆盖"); } protected abstract void method3();//子类负责实现业务逻辑 }
父类中有三个方法,分别是method1(),method2()和method3()。
method1()是私有方法,有且只能由父类实现逻辑,由于方法是private的,所以只能父类调用。
method2()是所谓的勾子方法。父类提供默认实现,如果子类觉得有必要定制,则可以覆盖父类的默认实现。
method3()是子类必须实现的方法,即制定的步骤。
由此可看出,算法的流程执行顺序是由父类掌控的,子类只能配合。
第一个子类
public class TemplatePatternImpl extends TemplatePattern { @Override protected void method3() { System.out.println("method3()在子类TemplatePatternImpl中实现了!!"); } } //这个子类只覆盖了必须覆盖的方法 //test TemplatePattern t1 = new TemplatePatternImpl(); t1.templateMethod(); console: 父类实现业务逻辑 父类默认实现,子类可覆盖 method3()在子类TemplatePatternImpl中实现了!!
第二个子类,实现勾子方法
public class TemplatePatternImpl2 extends TemplatePattern { @Override protected void method3() { System.out.println("method3()在子类TemplatePatternImpl2中实现了!!"); } /* (non-Javadoc) * @see com.jak.pattern.template.example.TemplatePattern#method2() */ @Override public void method2() { System.out.println("子类TemplatePatternImpl2覆盖了父类的method2()方法!!"); } } //test TemplatePattern t2 = new TemplatePatternImpl2(); t2.templateMethod(); console: 父类实现业务逻辑 子类TemplatePatternImpl2覆盖了父类的method2()方法!! method3()在子类TemplatePatternImpl2中实现了!!
spring中的例子(模板模式与回调)JdbcTemplate
经典JDBC代码


public List<User> query() { List<User> userList = new ArrayList<User>(); String sql = "select * from User"; Connection con = null; PreparedStatement pst = null; ResultSet rs = null; try { con = HsqldbUtil.getConnection(); pst = con.prepareStatement(sql); rs = pst.executeQuery(); User user = null; while (rs.next()) { user = new User(); user.setId(rs.getInt("id")); user.setUserName(rs.getString("user_name")); user.setBirth(rs.getDate("birth")); user.setCreateDate(rs.getDate("create_date")); userList.add(user); } } catch (SQLException e) { e.printStackTrace(); }finally{ if(rs != null){ try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } try { pst.close(); } catch (SQLException e) { e.printStackTrace(); } try { if(!con.isClosed()){ try { con.close(); } catch (SQLException e) { e.printStackTrace(); } } } catch (SQLException e) { e.printStackTrace(); } } return userList; }
上面的代码要若干年前可能是一段十分经典的,还可能被作为example被推广。但时过境迁,倘若哪位程序员现在再在自己的程序中出现以上代码,不是说明该公司的开发框架管理混乱,就说明这位程序员水平太“高”了。
我们试想,一个简单的查询,就要做这么一大堆事情,而且还要处理异常,我们不防来梳理一下:
1、获取connection
2、获取statement
3、获取resultset
4、遍历resultset并封装成集合
5、依次关闭connection,statement,resultset,而且还要考虑各种异常
6、.....
啊~~~~ 我快要晕了,在面向对象编程的年代里,这样的代码简直不能上人容忍。试想,上面我们只是做了一张表的查询,如果我们要做第2张表,第3张表呢,又是一堆重复的代码:
1、获取connection
2、获取statement
3、获取resultset
4、遍历resultset并封装成集合
5、依次关闭connection,statement,resultset,而且还要考虑各种异常
6、.....
这时候,使用模板模式的时机到了!!!
通过观察我们发现上面步骤中大多数都是重复的,可复用的,只有在遍历ResultSet并封装成集合的这一步骤是可定制的,因为每张表都映射不同的java bean。这部分代码是没有办法复用的,只能定制。
抽象父类实现
public abstract class JdbcTemplate { //template method public final Object execute(String sql) throws SQLException{ Connection con = HsqldbUtil.getConnection(); Statement stmt = null; try { stmt = con.createStatement(); ResultSet rs = stmt.executeQuery(sql); Object result = doInStatement(rs);//abstract method return result; } catch (SQLException ex) { ex.printStackTrace(); throw ex; } finally { try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); } try { if(!con.isClosed()){ try { con.close(); } catch (SQLException e) { e.printStackTrace(); } } } catch (SQLException e) { e.printStackTrace(); } } } //implements in subclass protected abstract Object doInStatement(ResultSet rs); }
在上面这个抽象类中,封装了SUN JDBC API的主要流程,而遍历ResultSet这一步骤则放到抽象方法doInStatement()中,由子类负责实现。
好,我们来定义一个子类,并继承上面的父类
public class JdbcTemplateUserImpl extends JdbcTemplate { @Override protected Object doInStatement(ResultSet rs) { List<User> userList = new ArrayList<User>(); try { User user = null; while (rs.next()) { user = new User(); user.setId(rs.getInt("id")); user.setUserName(rs.getString("user_name")); user.setBirth(rs.getDate("birth")); user.setCreateDate(rs.getDate("create_date")); userList.add(user); } return userList; } catch (SQLException e) { e.printStackTrace(); return null; } } }
由代码可见,我们在doInStatement()方法中,对ResultSet进行了遍历,最后并返回。
//test String sql = "select * from User"; JdbcTemplate jt = new JdbcTemplateUserImpl(); List<User> userList = (List<User>) jt.execute(sql);
回调实现
试想,如果我每次用jdbcTemplate时,都要继承一下上面的父类,是不是有些不方面呢?
那就让我们甩掉abstract这顶帽子吧,这时,就该callback(回调)上场了。
所谓回调,就是方法参数中传递一个接口,父类在调用此方法时,必须调用方法中传递的接口的实现类。
定义一个回调接口
public interface StatementCallback { Object doInStatement(Statement stmt) throws SQLException; }
改一下上面的方法签名
private final Object execute(StatementCallback action) throws SQLException
里面的获取数据方式也要做如下修改
Object result = action.doInStatement(stmt);//abstract method
稍微封装一下
public Object query(StatementCallback stmt) throws SQLException{ return execute(stmt); }
OK,大功告成!
我们来写一个测试类Test.java测试一下吧:
这时候,访问有两种方式,一种是内部类的方式,一种是匿名方式。
内部类的方式
//内部类方式 public Object query(final String sql) throws SQLException { class QueryStatementCallback implements StatementCallback { public Object doInStatement(Statement stmt) throws SQLException { ResultSet rs = stmt.executeQuery(sql); List<User> userList = new ArrayList<User>(); User user = null; while (rs.next()) { user = new User(); user.setId(rs.getInt("id")); user.setUserName(rs.getString("user_name")); user.setBirth(rs.getDate("birth")); user.setCreateDate(rs.getDate("create_date")); userList.add(user); } return userList; } } JdbcTemplate jt = new JdbcTemplate(); return jt.query(new QueryStatementCallback()); }
在调用jdbcTemplate.query()方法时,传一个StatementCallBack()的实例过去,也就是我们的内部类。
匿名方式
//匿名类方式 public Object query2(final String sql) throws Exception{ JdbcTemplate jt = new JdbcTemplate(); return jt.query(new StatementCallback() { public Object doInStatement(Statement stmt) throws SQLException { ResultSet rs = stmt.executeQuery(sql); List<User> userList = new ArrayList<User>(); User user = null; while (rs.next()) { user = new User(); user.setId(rs.getInt("id")); user.setUserName(rs.getString("user_name")); user.setBirth(rs.getDate("birth")); user.setCreateDate(rs.getDate("create_date")); userList.add(user); } return userList; } }); }
相比之下,这种方法更为简洁。
为什么spring不用传统的模板方法,而加之以Callback进行配合呢?
试想,如果父类中有10个抽象方法,而继承它的所有子类则要将这10个抽象方法全部实现,子类显得非常臃肿。而有时候某个子类只需要定制父类中的某一个方法该怎么办呢?这个时候就要用到Callback回调了。
离spring jdbcTemplate再近一点
上面这种方式基本上实现了模板方法+回调模式。但离spring的jdbcTemplate还有些距离。
我们可以再深入一些。。。
我们上面虽然实现了模板方法+回调模式,但相对于Spring的JdbcTemplate则显得有些“丑陋”。Spring引入了RowMapper和ResultSetExtractor的概念。
RowMapper接口负责处理某一行的数据,例如,我们可以在mapRow方法里对某一行记录进行操作,或封装成entity。
ResultSetExtractor是数据集抽取器,负责遍历ResultSet并根据RowMapper里的规则对数据进行处理。
RowMapper和ResultSetExtractor区别是,RowMapper是处理某一行数据,返回一个实体对象。而ResultSetExtractor是处理一个数据集合,返回一个对象集合。
当然,上面所述仅仅是Spring JdbcTemplte实现的基本原理,Spring JdbcTemplate内部还做了更多的事情,比如,把所有的基本操作都封装到JdbcOperations接口内,以及采用JdbcAccessor来管理DataSource和转换异常等。

