转载:如何快速处理线上故障
1. 概述
线上故障通常是指大规模的影响线上服务可用性的问题或者事件,通俗点讲就是:掉‘坑’里了,这个‘坑’就是线上故障!线上故障的处理过程可以形象地表达为:‘踩坑’、‘跳坑’、‘填坑’、‘避坑’。
线上故障的处理不仅是一项技术活,更是对技术人员/技术团队反应能力、决策能力、判定能力、组织能力的考验。面对突发的生产故障,需要快速定位问题,找到解决方案,快速实施解决方案并不是一件容易的事情。本文主要包括如下内容:线上故障处理的目标、思路、步骤、基础设施。
本文是依据平时经历的生产故障排查和处理,总结一些肤浅的方法论,以求共同探讨,共同提高,欢迎探讨。
2. 线上故障处理的目标
任何动物一旦掉进坑里,明智的做法一定是:跳坑-->填坑-->避坑,线上故障处理的过程也一样,优先级从高到低,线上故障处理的目标如下:
跳坑
‘跳坑’——快速恢复线上服务,或者将对线上服务的影响降到最低。
线上服务的可用性决定着服务者的客户利益,影响着公司的收益。一旦线上环境不可用,无法服务用户,给公司/团队带来经济利益损失的同时,更为严重的会给公司/团队带来恶劣的名声。所以一般公司都会对线上环境提出稳定性和可靠性的要求,这也是团队乃至部门的kpi。为此,遇到生产故障后的第一要务是:恢复生产服务,即使不能完全恢复线上服务,也要想尽办法将对线上服务的影响降到最低。
填坑
‘填坑’——找到问题原因,根本上解决问题。
在恢复线上服务,尽最大限度减掉对用户/公司/团队带来的影响后,我们需要彻查问题,搞清楚故障发生的根本原因,从根本上解决问题。通常情况下,‘填坑’和‘跳坑’是同步在做的,完成‘填坑’也就意味中‘跳坑’成功,但是也有一些紧急情况下的特别‘跳坑’方法,比如重启服务,或者服务降级/熔断等等,实际并未在当时完成‘填坑’,而是先采取非常规手段‘跳坑’,之后再慢慢‘填坑’。
避坑
‘避坑’——举一反三,消灭隐患。
找到了根本原因,解决了问题之后,我们需要举一反三,以此及彼,想想在这个故障排查和处理过程中,那些环节存在弱点?那些流程/规范/制度需要优化?这类问题是否在其他系统或者团队中也存在?通过这样的反思和自我批评,形成一份线上事故报告,不断完善流程,避免再次踩坑,也在团队中交流经验,共同提高。
3. 线上故障处理的思路
依据线上故障处理的目标及目标的优先级,线上排障的第一目标是恢复线上服务或者降低对线上服务的影响,关键点在于快速二字,在‘跳坑’-‘填坑’之后,再行回溯总结,以便‘避坑’。因此,可以将线上故障处理的步骤分为:
- 故障发现
- 故障定位
- 故障排除
- 故障回溯
其中前三步是‘跳坑’行为,后面一步包含了‘填坑’和‘避坑’。
上述步骤并不是说要从上到下顺序进行,建议在不乱阵脚的情况下,并行去做,因为通常线上故障后会紧急启动故障处理程序,运维、开发、测试、产品各个角色都会参与进来,这时候分工下去,并行去做,不断汇总消息,做出判断,以求快速排障,恢复服务。这个思路类似于操作系统的fork/join设计思想,目的在于提高效率。
在无法快速找到故障原因的时候,需要果断跳过故障定位环节,直接进行故障排除,比如采用服务降级、服务器扩容等手段,确保对线上服务降到最低且可控。等到线上服务'撑'过去之后,我们再慢慢定位故障原因,根本上解决问题。
下面我们会对这四个步骤进行详细说明。
3.1 故障发现
线上故障一般可以通过如下几种途径传递到开发/运维人员手中,按照从上到下的顺序,故障的严重程度依次变高。
- 主动发现——可能是开发或者运维不经意间查看生产环境的error日志,或者例行检查监控项时,看到了一些异常的现象,进而发现了故障;
- 系统监控告警——通常包括cpu、内存、io、tcp连接数、disk、线程数、GC、连接池等各个服务器指标异常,可能是服务器出现了异常,但是业务还未受到大面积影响;
- 业务监控告警——如用户登录失败率增加,订单堆积量增大,则意味中系统的异常已经很严重,影响了业务处理;
- 关联系统故障追溯——上游系统或者下游系统的故障处理邮件/电话追溯,可能和本系统有关系,而且情况已经变得很糟糕了,需要快速定位;
- 生产事件上报——通常业务异常带来的影响传递到用户,再从用户传递到客服人员,再到技术人员手里,会存在一定时延,所以一旦有生产事件上报,这个时候严重性已经到了最高,技术人员的压力也会增大,因为会有领导的关注,产品经理的询问和催促,客户人员的焦虑带来的压力。
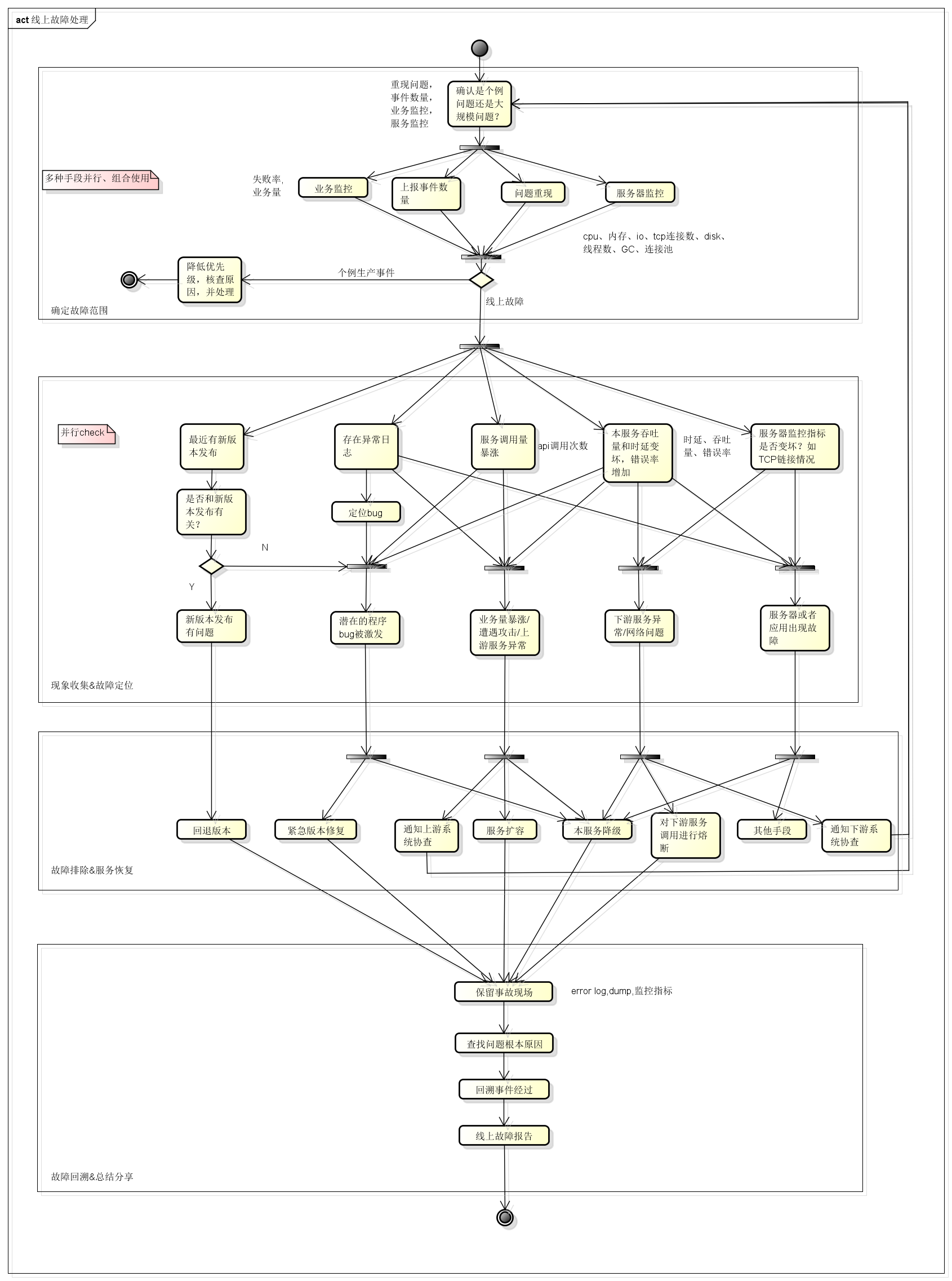
上述途径传递过来的信息仅仅只是线上故障苗头,并非一定就发生了大规模的线上故障,所以首先需要确认的是这是不是一次线上故障?还是只是个例生产问题?是否和本系统有关系?一般来讲:‘系统监控告警’和‘业务监控告警’的情况下,大部分都和本系统有关,且可能是线上故障;而‘主动发现’和‘生产事件上报’则需要做甄别,可以根据上报事件个数或者问题复现的方式来评估是否是大规模线上故障,或者跟踪日志信息或者特定用户问题追溯来确定。至于‘关联系统故障追溯’的情况,首先不要慌,先从宏观上确定本系统服务正常,一般可以检查是否有服务器监控报警,是否有业务监控报警等来确定,如果上游或者下游提供了日志,可以通过日志进行追踪,从而确定本系统是否存在故障。
因此在得到一些线上故障苗头之后,可以通过以下途径确定是否是线上故障:业务监控告警、上报事件个数、问题重现、服务器监控等。这些途径可以并行进行,灵活组合,有时候一个手段就能确定,有时候需要组合多个手段予以判定。
3.2 故障定位
一旦确定是线上故障后,我们需要快速定位故障点,找到问题原因,以便对症下药,快速排除故障。
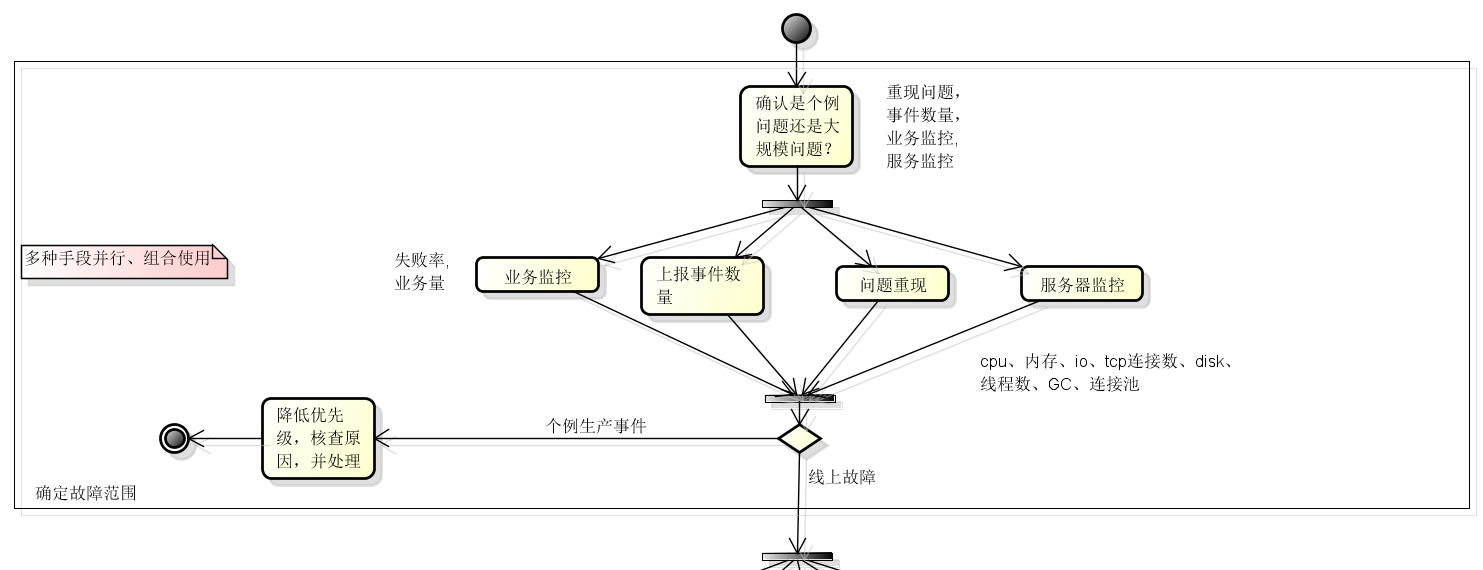
故障定位是一个不断‘收集信息--假设--验证--尝试’的循环过程,基本思路:拿到线上信息,产生怀疑点,拿到更详细的信息,进行推理验证,必要时刻,找到可行的验证措施,进行可控的尝试,或者在测试环境进行业务测试重现,性能测试重现。
可能存在的怀疑点有:
- 新版本发布有问题
- 潜在的程序bug被激发,比如在访问量暴增的情况下,并发bug被激发
- 业务量暴涨
- 遭遇攻击,如活动期间羊毛党刷积分等
- 上游服务调用异常,如上游系统升级httpclient后,将长连接改为短连接
- 下游服务异常,下游服务宕机
- 网络问题
- 服务器故障,如磁盘满,内存爆掉等
- 应用故障
- 数据库故障
为此,可以通过如下几方面收集信息,以便支撑你的怀疑点:
- 最近新版本的发布情况
- 本服务的异常/error日志
- 本服务的调用量变化情况,是否存在暴涨?
- 本服务的吞吐量,是否出现下降?
- 本服务的时延,是否出现突然增大?
- 服务器TCP的链接情况,是否存在大量的CLOSE_WAIT?
- 服务器的cpu使用率,是否突然飙升?
- 服务器的disk,磁盘空间是否已经用完?
- 服务器的内存,内存是否爆掉?
- 数据库或者存储是否挂掉?
很多故障并不是由于单一原因造成的,而是多个条件同时满足时才出现的,所以,需要多收集信息,综合得到的信息,产生怀疑点,快速推理和验证,最后找到问题点,定位到故障。这个过程中可以集合大家的力量,并行去check各个点,并快速反馈信息。
由于组合情况众多,这里只将明显的故障定位场景列出,更多的需要总结归纳:
- 发布了最新版本,且故障最早出现时间在版本发布之后,很大程度上时由于新版本发布带来的问题,可能是bug,也可能是部署出现问题;
- 未发布新版本,业务访问量猛增,服务时延增大,吞吐量先上升后下降,到最后服务直接不可用,可能原因是:业务量暴涨/遭遇攻击/上游服务异常调用;
- 未发布新版本,部分服务失败,服务错误率增加,业务访问量增加,可能原因是业务访问量增大激发了潜在的并发bug,或者出现了io瓶颈等;
- 业务访问量并未增加,但是服务时延下降,吞吐量下降,服务错误率增加,且服务器TCP的CLOSE_WAIT增大,这时候需要怀疑下游依赖服务是否异常。
- 业务访问量并未增加,服务大范围不可用,日志中出现大量数据库错,很明显数据库可能出现问题,或者应用的数据库连接池出现问题。
不一而足,需要逐步积累。下图是对上面描述的总结。
故障定位的初期,一般会先通过邮件+电话的方式进行沟通,如果几分钟之后事态变糟糕,且没有眉目,则需要紧急启动会议形式的联合排障,所有相关人员需要放下手头事情,集中到一个特定会议室进行联合排障。这样的好处也在于能够迅速共享信息,快速做出决策。联合排障人员通常会包括:开发、运维、测试、产品,主力应当是开发和运维,测试和产品需要帮忙快速确认一些东西,如复现问题,或者确认业务逻辑等。
从上面可以看到,故障定位过程中,追求‘快速’二字,为此多项事情是并行去做的。为了避免出现群龙无首的慌乱局面,需要有一个主心骨坐镇,把握排障的方向并最终做出决策,这个人是master,需要冷静沉着,且要能调度尽可能多的资源,所以技术leader或者运维leader会比较合适。这个类似于分布式系统的设计思路。
另外,在故障定位过程中,获得的线上一线信息需要通过某种形式记录下来,邮件往来是一种比较好的方式,在完成通信和信息共享的基础上,也无形中保留了现场。其他的信息包括:error log,dump文件,服务器各个指标的状态值等等。
3.3 故障排除
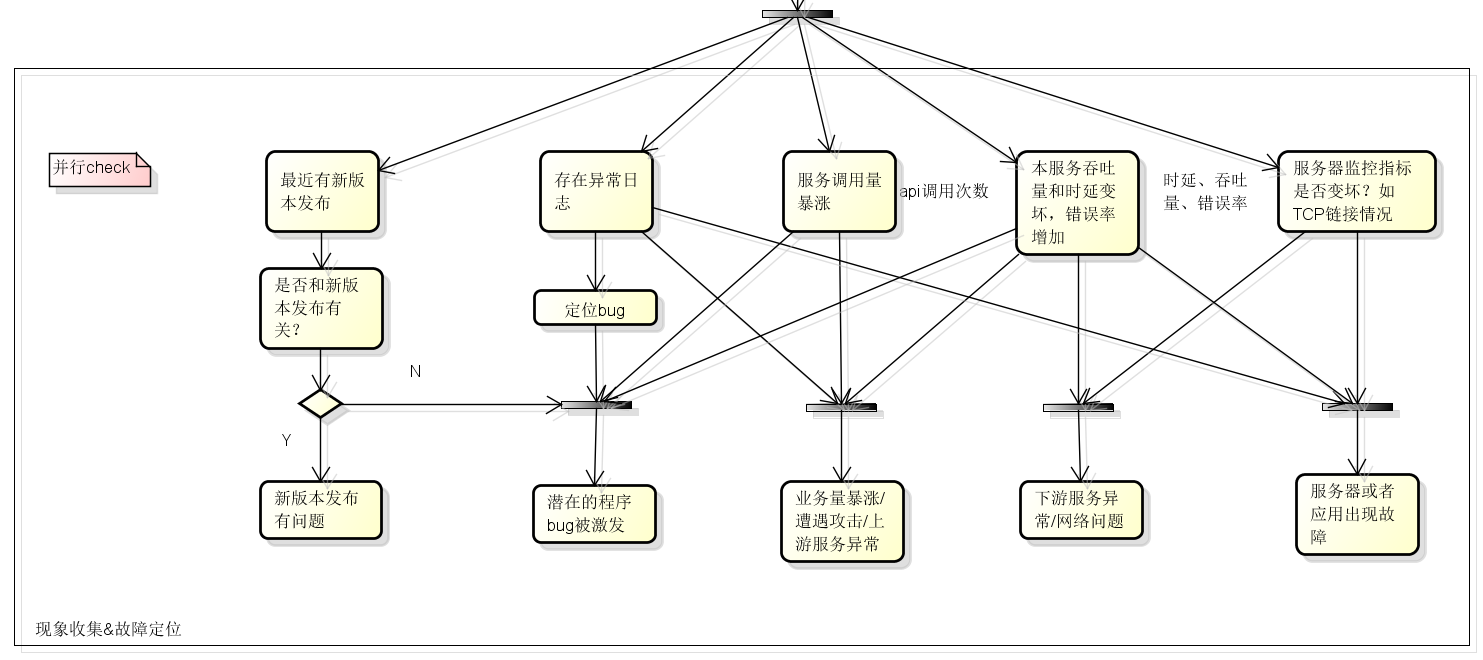
一旦定位到故障原因,对症下药地排除故障就不是什么难事了,具体的措施可以参考下图中的总结:

这里需要特别指出一个特别的场景:无法定位故障的情况下如何迅速排除故障。
很多时候无法及时找到故障原因,必须直接进入故障排除,这时候的思路就在于:尽最大可能降低线上服务影响了。可以采用的手段有如下几项:
- 服务降级——定位到某些服务有异常,但不清楚异常出现的原因,直接将这些服务降级,确保其他服务不受影响;
- 服务紧急扩容——无法定位到是哪些服务造成的,服务器资源彪升,扛不住压力时,紧急扩容服务器;比如恶意攻击、营销活动,秒杀等场景带来的突发情况;
- 回退版本——有新版本发布,但是不能迅速确定是否和新版本有关系,先做版本回退,确保线上服务回到上一个稳定版本。
还是那句话,故障排除的原则是:确保线上服务快速恢复,不能完全恢复的情况下,确保线上服务尽可能少地受到影响。
3.4 故障回溯
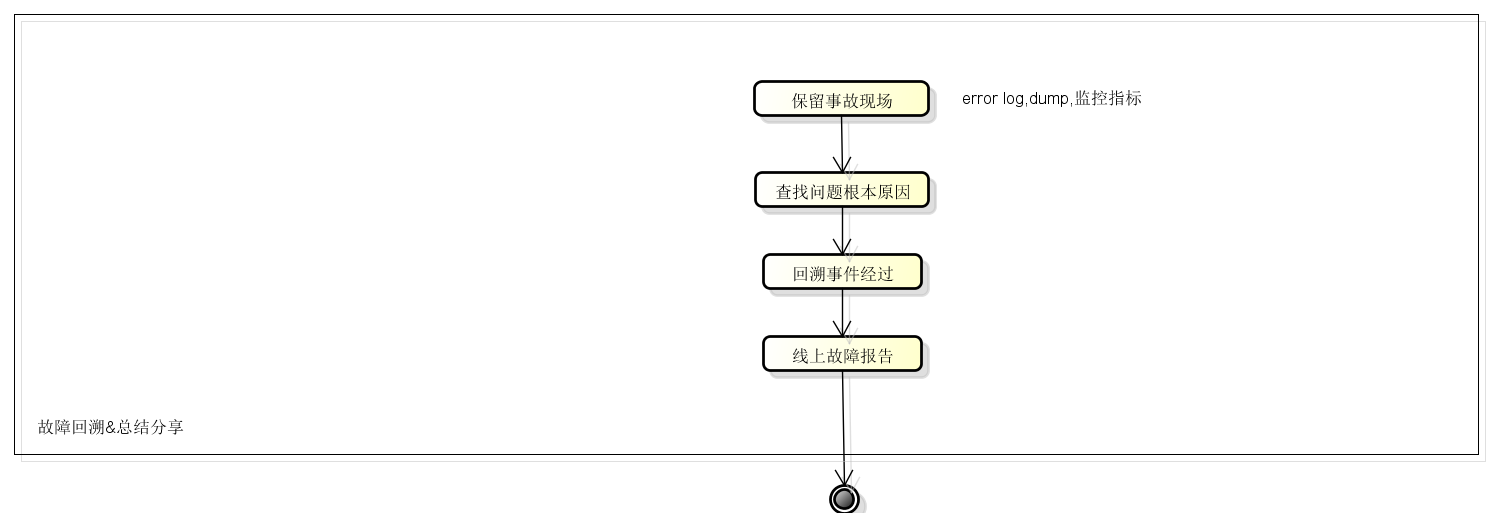
故障回溯的目的是在故障排除后,冷静地回溯整个线上故障的发现/定位/排除过程,找出流程中/架构中/制度中的缺陷,并将该缺陷消灭掉,同时推而广之到其他系统。在‘跳坑’--‘填坑’之后,我们需要通过故障回溯的过程达到‘避坑’的效果,即要保证自己能‘避坑’,也保证团队/公司能够避开类似的坑。
故障回溯的过程,因人因团队而异,最重要的是要有严肃的‘形式’和最终的产出物。之所以提到严肃的‘形式’,是因为线上故障无小事,一定要让大家牢记在心。
至于如何达到‘严肃’,可以参考如下形式:
- 可以和kpi挂钩。慎用,可能会伤害到技术人员的心,造成‘懒政’现象——“多干多出事,少干少出事”出现;
- 可以实施追责制度。同上;
- 还可以进行邮件或者会议形式的讨论,广而告之。
总之,故障回溯的最终的目标不是为了追责,更重要的是让大家长记性,避免后续再次踩坑,而且线上故障报告的产出物一定要有,一方面是经验的积累,便于分享,另一方面也让当事人撸清楚事件过程,吃一堑长一智。
可以参考的一个流程如下:
4.线上故障处理的‘后勤保障’
前面谈了线上故障处理的目标、思路和步骤,回过头来看下,要快速准确地定位和排除线上故障,需要很多基础设施支撑,它们是线上故障处理的‘后勤保障’。结合上面的内容归纳总结如下:
完善的监控/告警体系
通过告警,能让我们迅速知道自己的服务出了问题,通过监控可以从时间维度进行对比分析,找到可疑点,进而定位故障。
监控通常分为:
- 服务器监控——针对操作系统资源使用情况(比如cpu使用率、内容使用率、磁盘空间、io、network等),容器健康程度(内存使用情况、线程数、GC情况等),application健康程度的(服务的可访问性等);
- 服务监控——包括吞吐量、时延等,这些指标至少包括:最大值、平均值,通过这些指标可以判断单个服务的变化情况和健康程度;
- 业务监控——包括访问量、错误率等,一个业务场景往往会包含多个服务调用,因此通过业务监控,可以发现一些关联问题。
告警方面,需要根据实际情况和业务场景进行阈值设定,告警阈值的设定是一个动态调整的过程。
监控系统最基本的需要保证:按照时间序列进行统计、对比。
完善的日志trace体系
在线上故障处理过程中,日志尤其重要,通过日志能够定位到问题或者bug细节。在分布式架构的系统中,多实例的部署导致日志分散在多台机器上,靠人肉查看耗时费力,效率低下;另一方面,业务发展壮大后,业务系统越来越多,系统间依赖越来越多,各个业务系统的日志需要通过唯一的标识串联起来,否则会出现信息断层的问题,日志变得无用。所以完善的日志trace系统非常必要。
日志trace体系的几个关键点:
- 有唯一的标识串联上下游系统日志
- 能自动收集分布式应用日志
- 日志收集时延不能超过10分钟(具体时间试实际情况而定,如果时延太长,日志没有多大意义)
- 支持多种形式的查询/过滤/统计等
- 可以看到时间序列上的变化趋势
推荐使用开源的日志架构:logstash+elasticsearch+kibana。
完善的故障处理机制
线上故障处理的要点在于快速,所以需要有完善便捷的事件流转机制和故障处理机制来保证:生产事件能快速推送到相关责任人进行联合排除,保证事件排查过程中快速共享信息,快速完成决策。
对于事件上报,一般的公司会有专用的通道给到一线客服人员,客户人员填报工单,上报事件,关键点在于事件处理中担任‘路由’角色的人员,他需要对业务系统比较熟悉,对于上报的问题能快速确定相关的业务系统和负责人,并通知到对方,这个角色既要熟知业务,也要熟知系统架构和组织架构,这个角色一般会交由专门人员处理,称之为‘二线’人员,或者由运维人员兼职。
排查生产事件/故障时,推荐进行集中版本,便于快速共享信息,同时需要有一个master,以便把握大的方向,并快速完成决策。
5.总结
以上,对线上故障处理的目标、思路、步骤及基础设施进行了讨论,先总结如下:
- 线上排障的第一目标是恢复线上服务或者降低对线上服务的影响,关键点在于快速二字,在‘跳坑’-‘填坑’之后,需要总结以便‘避坑’。
- 一切的流程或者手段都是为‘快速’二字服务的,所以线上故障是最高优先级的任务,任何人需要第一时间予以响应;同时,尽早地反馈故障问题,尽早地集结各个角色,群策群力地进行排障值得提倡;这个过程中,需要有一位有‘威望’的master坐镇,主持大局;在保证有序推进的情况下,尽可能地并行地收集信息,进行尝试。这个有点分布式架构的味道了,master坐镇,slave并行干活,提高效率。
- 必须要有一个‘严肃’的形式让当事人及旁观者‘吃一堑长一智’,线上故障处理报告是必须的产出物。
- 为了更加高效的处理线上故障,需要有完善的基础设施支撑:监控/告警体系、日志trace体系、事件流转机制。
对于线上排障的流程整理了一个大图,如下: