


高并发系统之限流特技(开涛)
概述
高并发的处理有三个比较常用的手段,缓存、降级、限流。缓存的使用相信很多开发者都很了解了,诸如redis,memcache等工具都会活跃在我们的系统当中。但是假如在某一时间段内出现了远超预想的流量访问到系统,例如在搞秒杀活动之类的,这样一来我们应该如何保护业务系统呢?
在参加一些秒杀活动的时候,我们可以看到,有时候会有 系统繁忙,请稍后再试
或者 请稍等 的提示,那这个系统就很可能是使用了限流的手段。
限流是限制系统的输入和输出流量,以达到保护系统的目的。而限流的实现主要是依靠限流算法,限流算法主要有4种:
1、固定时间窗口(计数器);
2、滑动时间窗口;
3、令牌桶算法;
4、漏桶算法;
计数器
思路
计数器法是限流算法里最简单也是最容易实现的一种算法。比如我们规定,对于A接口来说,我们1分钟的访问次数不能超过100个。那么我们可以这么做:
在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个 请求的间隔时间还在1分钟之内,那么说明请求数过多;如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter。伪代码如下:
public class CounterDemo { public long timeStamp = getNowTime(); public int reqCount = 0; public final int limit = 100; // 时间窗口内最大请求数 public final long interval = 1000; // 时间窗口ms public boolean grant() { long now = getNowTime(); if (now < timeStamp + interval) { // 在时间窗口内 reqCount++; // 判断当前时间窗口内是否超过最大请求控制数 return reqCount <= limit; } else { timeStamp = now; // 超时后重置 reqCount = 1; return true; } } }
缺点
1.假设有一个恶意用户,他在0:59时,瞬间发送了100个请求,并且1:00又瞬间发送了100个请求,那么其实这个用户在 1秒里面,瞬间发送了200个请求。我们刚才规定的是1分钟最多100个请求,也就是每秒钟最多1.7个请求,用户通过在时间窗口的重置节点处突发请求,可以瞬间超过我们的速率限制。用户有可能通过算法的这个漏洞,瞬间压垮我们的应用。
2.如果我在单位时间1s内的前10ms,已经通过了100个请求,那后面的990ms,只能眼巴巴的把请求拒绝,我们把这种现象称为“突刺现象”
聪明的朋友可能已经看出来了,刚才的问题其实是因为我们统计的精度太低。那么如何很好地处理这个问题呢?或者说,如何将临界问题的影响降低呢?我们可以看下面的滑动窗口算法。
滑动窗口
这个名称要跟TCP的窗口滑动区分开来,但是理解之后会发现其实也是有点相似。
计数器算法对流量的限制比较粗放,而滑动时间窗口的算法则是对流量进行更加平稳的控制。上面的计数器的单位时间是1分钟,而在使用滑动时间窗口,可以把1分钟分成6格,每格时间长度是10s,每一格又各自管理一个计数器,单位时间用一个长度为60s的窗口描述。一个请求进入系统,对应的时间格子的计数器便会+1,而每过10s,这个窗口便会向右滑动一格。只要窗口包括的所有格子的计数器总和超过限流上限,便会拒绝后面的请求。
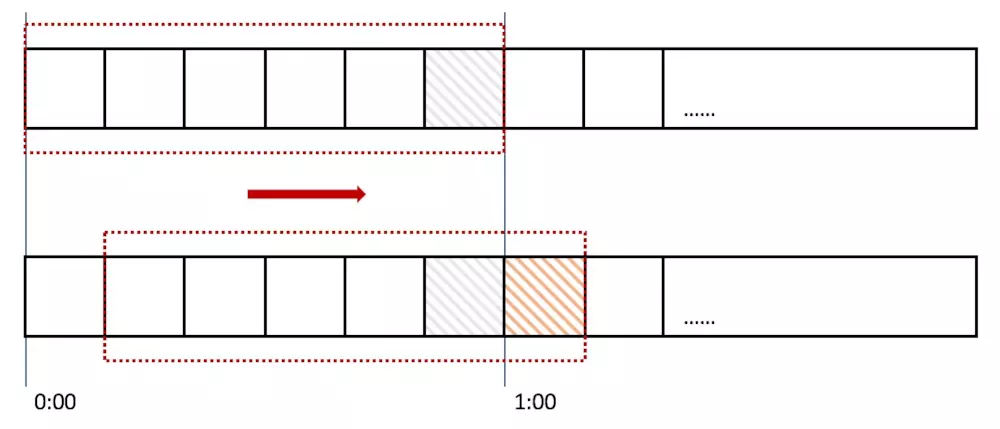
那么滑动窗口怎么解决刚才的临界问题的呢?我们可以看上图,0:59到达的100个请求会落在灰色的格子中,而1:00到达的请求会落在橘黄色的格 子中。当时间到达1:00时,我们的窗口会往右移动一格,那么此时时间窗口内的总请求数量一共是200个,超过了限定的100个,所以此时能够检测出来触 发了限流。
我再来回顾一下刚才的计数器算法,我们可以发现,计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,所以只有1格。
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
漏桶算法
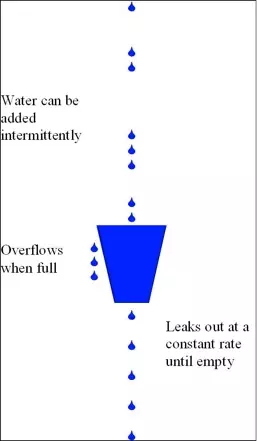
为了消除"突刺现象",可以采用漏桶算法实现限流,漏桶算法这个名字就很形象,算法内部有一个容器,类似生活用到的漏斗,当请求进来时,相当于水倒入漏斗,然后从下端小口慢慢匀速的流出。不管上面流量多大,下面流出的速度始终保持不变。
不管服务调用方多么不稳定,通过漏桶算法进行限流,每10毫秒处理一次请求。因为处理的速度是固定的,请求进来的速度是未知的,可能突然进来很多请求,没来得及处理的请求就先放在桶里,既然是个桶,肯定是有容量上限,如果桶满了,那么新进来的请求就丢弃。
伪代码:
public class LeakyDemo { public long timeStamp = getNowTime(); public int capacity; // 桶的容量 public int rate; // 水漏出的速度 public int water; // 当前水量(当前累积请求数) public boolean grant() { long now = getNowTime(); water = max(0, water - (now - timeStamp) * rate); // 先执行漏水,计算剩余水量 timeStamp = now; if ((water + 1) < capacity) { // 尝试加水,并且水还未满 water += 1; return true; } else { // 水满,拒绝加水 return false; } } }
令牌桶算法
令牌桶算法比漏桶算法稍显复杂。首先,我们有一个固定容量的桶,桶里存放着令牌(token)。桶一开始是空的,token以 一个固定的速率r往桶里填充,直到达到桶的容量,多余的令牌将会被丢弃。每当一个请求过来时,就会尝试从桶里移除一个令牌,如果没有令牌的话,请求无法通过。
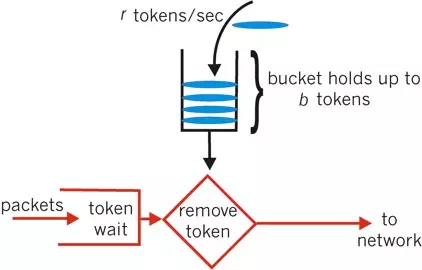
在时间点刷新的临界点上,只要剩余token足够,令牌桶算法会允许对应数量的请求通过,而后刷新时间因为token不足,流量也会被限制在外,这样就比较好的控制了瞬时流量。因此,令牌桶算法也被广泛使用。
伪代码:
public class TokenBucketDemo { public long timeStamp = getNowTime(); public int capacity; // 桶的容量 public int rate; // 令牌放入速度 public int tokens; // 当前令牌数量 public boolean grant() { long now = getNowTime(); // 先添加令牌 tokens = min(capacity, tokens + (now - timeStamp) * rate); timeStamp = now; if (tokens < 1) { // 若不到1个令牌,则拒绝 return false; } else { // 还有令牌,领取令牌 tokens -= 1; return true; } } }
单机限流方案总结
计数器 VS 滑动窗口
计数器算法是最简单的算法,可以看成是滑动窗口的低精度实现。滑动窗口由于需要存储多份的计数器(每一个格子存一份),所以滑动窗口在实现上需要更多的存储空间。也就是说,如果滑动窗口的精度越高,需要的存储空间就越大。
漏桶算法 VS 令牌桶算法
漏桶算法和令牌桶算法最明显的区别是令牌桶算法允许流量一定程度的突发。因为默认的令牌桶算法,取走token是不需要耗费时间的,也就是说,假设桶内有100个token时,那么可以瞬间允许100个请求通过。
令牌桶算法由于实现简单,且允许某些流量的突发,对用户友好,所以被业界采用地较多。当然我们需要具体情况具体分析,只有最合适的算法,没有最优的算法。
分布式限流
分布式限流最关键的是要将限流服务做成原子化,而解决方案可以使使用redis+lua或者nginx+lua技术进行实现,通过这两种技术可以实现的高并发和高性能。
redis+lua
首先我们来使用redis+lua实现时间窗内某个接口的请求数限流,实现了该功能后可以改造为限流总并发/请求数和限制总资源数。Lua本身就是一种编程语言,也可以使用它实现复杂的令牌桶或漏桶算法。
-- --lua 下标从 1 开始 -- 限流 key local key = KEYS[1] -- 限流大小 local limit = tonumber(ARGV[1]) local MINUTES = "MINUTES" -- 获取当前流量大小 local curentLimit = tonumber(redis.call('get', key) or "0") local m = ARGV[2] if curentLimit + 1 > limit then -- 达到限流大小 返回 return 0; else -- 没有达到阈值 value + 1 redis.call("INCRBY", key, 1) if m == MINUTES then redis.call("EXPIRE", key, 120) else redis.call("EXPIRE", key, 2) end return curentLimit + 1 end
如下是Java中判断是否需要限流的代码:
public static boolean acquire() throws Exception { String luaScript = Files.toString(new File("limit.lua"), Charset.defaultCharset()); Jedis jedis = new Jedis("192.168.147.52", 6379); String key = "ip:" + System.currentTimeMillis() / 1000; // 此处将当前时间戳取秒数 Stringlimit = "3"; // 限流大小 return (Long) jedis.eval(luaScript, Lists.newArrayList(key), Lists.newArrayList(limit)) > 1; }
因为Redis的限制(Lua中有写操作不能使用带随机性质的读操作,如TIME)不能在Redis Lua中使用TIME获取时间戳,因此只好从应用获取然后传入,在某些极端情况下(机器时钟不准的情况下),限流会存在一些小问题。
https://github.com/crossoverJie/distributed-redis-tool(使用拦截器封装成注解)
Nginx+Lua


local locks = require "resty.lock" local function acquire() local lock =locks:new("locks") local elapsed, err =lock:lock("limit_key") --互斥锁 local limit_counter =ngx.shared.limit_counter --计数器 local key = "ip:" ..os.time() local limit = 5 --限流大小 local current =limit_counter:get(key) if current ~= nil and current + 1> limit then --如果超出限流大小 lock:unlock() return 0 end if current == nil then limit_counter:set(key, 1, 1) --第一次需要设置过期时间,设置key的值为1,过期时间为1秒 else limit_counter:incr(key, 1) --第二次开始加1即可 end lock:unlock() return 1 end ngx.print(acquire())
实现中我们需要使用lua-resty-lock互斥锁模块来解决原子性问题(在实际工程中使用时请考虑获取锁的超时问题),并使用ngx.shared.DICT共享字典来实现计数器。如果需要限流则返回0,否则返回1。使用时需要先定义两个共享字典(分别用来存放锁和计数器数据):
http {
……
lua_shared_dict locks 10m;
lua_shared_dict limit_counter 10m;
}
有人会纠结如果应用并发量非常大那么redis或者nginx是不是能抗得住;不过这个问题要从多方面考虑:你的流量是不是真的有这么大,是不是可以通过一致性哈希将分布式限流进行分片,是不是可以当并发量太大降级为应用级限流;对策非常多,可以根据实际情况调节;像在京东使用Redis+Lua来限流抢购流量,一般流量是没有问题的。
接入层限流(Nginx)
对于分布式限流目前遇到的场景是业务上的限流,而不是流量入口的限流;流量入口限流应该在接入层完成,而接入层笔者一般使用Nginx。
接入层通常指请求流量的入口,该层的主要目的有:负载均衡、非法请求过滤、请求聚合、缓存、降级、限流、A/B测试、服务质量监控等等,可以参考笔者写的《使用Nginx+Lua(OpenResty)开发高性能Web应用》。
对于Nginx接入层限流可以使用Nginx自带了两个模块:连接数限流模块ngx_http_limit_conn_module和漏桶算法实现的请求限流模块ngx_http_limit_req_module。还可以使用OpenResty提供的Lua限流模块lua-resty-limit-traffic进行更复杂的限流场景。
limit_conn用来对某个KEY对应的总的网络连接数进行限流,可以按照如IP、域名维度进行限流。limit_req用来对某个KEY对应的请求的平均速率进行限流,并有两种用法:平滑模式(delay)和允许突发模式(nodelay)。

