


数据库自增主键
最常见的方式。利用数据库,全数据库唯一。
优点:
1)简单,代码方便,性能可以接受。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
2)在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
3)在性能达不到要求的情况下,比较难于扩展。
4)如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
5)分表分库的时候会有麻烦。
优化方案:
1)针对主库单点,如果有多个Master库,则每个Master库设置的起始数字不一样,步长一样,可以是Master的个数。比如:Master1 生成的是 1,4,7,10,Master2生成的是2,5,8,11 Master3生成的是 3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
这种方式可保证id不重复。但导致id不是绝对递增,而是整体趋势上递增;其次是写入的压力仍然很大,mysql容易成为性能瓶颈。
数据库批量生成id(TDDL采用)
优点:效率高;降低数据库压力
缺点:需考虑安全性问题,防止取到重复id;如果业务需求是每次只生成一个id,性能有问题
备注:利用数据库,初始化一行数据,初始值为1,取10个id,就给该值加10,调用端取返回id值的前10个数值。以上即为批量生成id思路。
UUID
常见的方式。可以利用数据库也可以利用程序生成,一般来说全球唯一。
优点:
1)简单,代码方便。
2)生成ID性能非常好,基本不会有性能问题。
3)全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
1)没有排序,无法保证趋势递增。
2)UUID往往是使用字符串存储,查询的效率比较低。
3)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
4)传输数据量大
5)不可读。
UUID变种
1)为了解决UUID不可读,可以使用UUID to Int64的方法。即
/// <summary> /// 根据GUID获取唯一数字序列 /// </summary> public static long GuidToInt64() { byte[] bytes = Guid.NewGuid().ToByteArray(); return BitConverter.ToInt64(bytes, 0); }
2)为了解决UUID无序的问题,NHibernate在其主键生成方式中提供了Comb算法(combined guid/timestamp)。保留GUID的10个字节,用另6个字节表示GUID生成的时间(DateTime)。
/// <summary> /// Generate a new <see cref="Guid"/> using the comb algorithm. /// </summary> private Guid GenerateComb() { byte[] guidArray = Guid.NewGuid().ToByteArray(); DateTime baseDate = new DateTime(1900, 1, 1); DateTime now = DateTime.Now; // Get the days and milliseconds which will be used to build //the byte string TimeSpan days = new TimeSpan(now.Ticks - baseDate.Ticks); TimeSpan msecs = now.TimeOfDay; // Convert to a byte array // Note that SQL Server is accurate to 1/300th of a // millisecond so we divide by 3.333333 byte[] daysArray = BitConverter.GetBytes(days.Days); byte[] msecsArray = BitConverter.GetBytes((long) (msecs.TotalMilliseconds / 3.333333)); // Reverse the bytes to match SQL Servers ordering Array.Reverse(daysArray); Array.Reverse(msecsArray); // Copy the bytes into the guid Array.Copy(daysArray, daysArray.Length - 2, guidArray, guidArray.Length - 6, 2); Array.Copy(msecsArray, msecsArray.Length - 4, guidArray, guidArray.Length - 4, 4); return new Guid(guidArray); }
用上面的算法测试一下,得到如下的结果:作为比较,前面3个是使用COMB算法得出的结果,最后12个字符串是时间序(统一毫秒生成的3个UUID),过段时间如果再次生成,则12个字符串会比图示的要大。后面3个是直接生成的GUID。
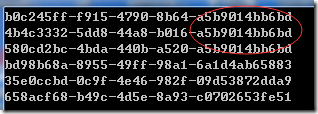
如果想把时间序放在前面,可以生成后改变12个字符串的位置,也可以修改算法类的最后两个Array.Copy。
Redis生成ID
原子操作 INCR和INCRBY
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
这个,随便负载到哪个机确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以方式单点故障的问题。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
EVAL,EVALSHA两个命令(LUA)
GitHub 地址:https://github.com/hengyunabc/redis-id-generator
依赖redis的EVAL,EVALSHA两个命令,利用redis的lua脚本执行功能,在每个节点上通过lua脚本生成唯一ID。 生成的ID是64位的:
使用41 bit来存放时间,精确到毫秒,可以使用41年。
使用12 bit来存放逻辑分片ID,最大分片ID是4095
使用10 bit来存放自增长ID,意味着每个节点,每毫秒最多可以生成1024个ID
Redis提供了TIME命令,可以取得redis服务器上的秒数和微秒数。因些lua脚本返回的是一个四元组。
second, microSecond, partition, seq
客户端要自己处理,生成最终ID。
((second * 1000 + microSecond / 1000) << (12 + 10)) + (shardId << 10) + seq;
在redis-id-generator-java目录下,有example和benchmark代码,提供了 Java客户端生成模式,其它语言只要支持redis evalsha命令就可以了。
ZK生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
很少会使用zookeeper来生成唯一ID。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境下,也不甚理想。
Stat stat = zkClient.writeData("/seq", new byte[0], -1);
nt versionAsSeq = stat.getVersion();
System.out.println(taskName + " obtain seq=" +versionAsSeq );
往指定节点写数据,每次写成功,拿到的版本号用来做唯一ID,性能不大好。
snowflake
公司用
时间戳+机器ID+自增ID
自增ID用Mysql,每个应用每次取100个ID缓存在内存。Mysql对应的行数值加100。类似TDDL 方案。
总体上保持递增。
严格递增,可以用redis做。

