day02
1、爬取ajax请求的数据(循环):
from urllib.request import Request,urlopen base_url = "https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start={0}&limit={1}" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36" } i = 0 while True: url = base_url.format(i*20,20) print(url) request = Request(url,headers=headers) response = urlopen(request) content = response.read().decode() if content == "[]" or content == None: # 爬取的内容为空时,就停止 break; print(content) print(i) i += 1
2、忽略证书问题:

3、proxy代理:
1) 自己创建build_opener对象,调用open方法:
from urllib.request import Request,build_opener
from fake_useragent import UserAgent
url = "http://httpbin.org/get"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36"
}
request = Request(url,headers=headers)
# 之前都是通过urlopen,里面也是创建build_opener类,再调用open方法
# 现在自己创建build_opener,调用open方法
openr = build_opener()
response = openr.open(request) # 去请求url
print(response.read().decode())

2) 代理ip:防止自己的ip被封 :
from urllib.request import Request,build_opener,ProxyHandler from fake_useragent import UserAgent url = "http://httpbin.org/get" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36" } request = Request(url,headers=headers) # proxy = ProxyHandler({"http":"username:pwd@120.27.224.41:16818"})#独享ip,花钱买 proxy = ProxyHandler({"http":"163.125.249.117:8118"}) # 免费ip openr = build_opener(proxy) response = openr.open(request) print(response.read().decode())
4、cookies:

1)、使用自己登录的cookies:
from urllib.request import HTTPCookieProcessor,Request,build_opener from fake_useragent import UserAgent url = "https://www.sxt.cn/index/user.html" headers = { "User-Agent":UserAgent().random, # 自己登录网站,拿网站返回的cookie , cookie放到请求头中 "Cookie":"UM_distinctid=1677e8c7912122-0191ed60274b72-5c10301c-e1000-1677e8c791420d; 53gid2=10689069155008; 53gid1=10689069155008; 53revisit=1544016395113; 53gid0=10689069155008; PHPSESSID=rgp2u6edmipoflg2i4ivqefp70; visitor_type=old; 53kf_72085067_from_host=www.sxt.cn; 53kf_72085067_land_page=https%253A%252F%252Fwww.sxt.cn%252Findex.html; kf_72085067_land_page_ok=1; 53kf_72085067_keyword=https%3A%2F%2Fwww.sxt.cn%2Findex%2Flogin%2Flogin.html; CNZZDATA1261969808=954793838-1544013478-https%253A%252F%252Fwww.sxt.cn%252F%7C1544071377" } request = Request(url,headers=headers) opener = build_opener() response = opener.open(request) print(response.read().decode())
2)、使用写代码登录的cookies:
from urllib.request import HTTPCookieProcessor,Request,build_opener from fake_useragent import UserAgent from urllib.parse import urlencode login_url = "https://www.sxt.cn/index/login/login" data = { "user": "17703181473", "password": "123456", } headers = { "User-Agent":UserAgent().random, } request = Request(login_url,headers=headers,data=urlencode(data).encode()) cookie = HTTPCookieProcessor() opener = build_opener(cookie) # 将返回的cookie放到opener中,下次再用这个opener请求url response = opener.open(request) user_url = "https://www.sxt.cn/index/user.html" request = Request(user_url,headers=headers) response = opener.open(request) print(response.read().decode())
3)、使用cookiejar,将cookie写到文件中:
from urllib.request import HTTPCookieProcessor, Request, build_opener from fake_useragent import UserAgent from urllib.parse import urlencode from http.cookiejar import MozillaCookieJar headers = { "User-Agent": UserAgent().random, } # 获得cookie,存进文件中 def get_cookie(): login_url = "https://www.sxt.cn/index/login/login" data = { "user": "17703181473", "password": "123456", } request = Request(login_url, headers=headers, data=urlencode(data).encode()) cookiejar = MozillaCookieJar() cookie = HTTPCookieProcessor(cookiejar) opener = build_opener(cookie) response = opener.open(request) # cookiejar:将cookie存到文件中,discard:丢弃的cookie,expires:无效的cookie cookiejar.save("cookie.txt", ignore_discard=True, ignore_expires=True) # 使用文件中cookie,进入用户界面 def use_cookie(): user_url = "https://www.sxt.cn/index/user.html" request = Request(user_url, headers=headers) cookiejar = MozillaCookieJar() # 后面两个True需要加的 cookiejar.load("cookie.txt",ignore_expires=True,ignore_discard=True) cookie = HTTPCookieProcessor(cookiejar) opener = build_opener(cookie) response = opener.open(request) print(response.read().decode()) if __name__ == "__main__": get_cookie() use_cookie()
5、URLError-捕获异常:
from urllib.request import Request,urlopen,URLError from fake_useragent import UserAgent url = "https://www.sxt.cn/index/login/login.htmls" headers = { "User-Agent":UserAgent().random } try: request = Request(url,headers=headers) response = urlopen(request) print(response.read().decode()) except URLError as e: # HTTP Error 404: Not Found # <urlopen error [Errno 11004] getaddrinfo failed> if e.args==(): # 不存在url 404 print(e.code) else: # 域名不存在 11004 print(e.args[0].errno) print("成功")
6、requests库:
1)、get请求: import requests url = "http://www.baidu.com/s" params = { "wd":"尚学堂" } response = requests.get(url,params=params) print(response.text) 2)、post请求 : import requests url = "https://www.sxt.cn/index/login/login" data = { "user": "17703181473", "password": "123456", } # data接受post数据 response = requests.post(url,data=data) print(response.text) 3)、代理: import requests from fake_useragent import UserAgent url = "http://httpbin.org/get" headers = { "User-Agent":UserAgent().random } proxy = { # 书写格式 "http":"http://124.235.135.210:80" # 独享代理 # "http":"http://user:pwd@ip:port" } # data接受post数据 response = requests.get(url,headers=headers,proxies=proxy) print(response.text) 4)、证书: import requests from fake_useragent import UserAgent url = "https://www.12306.cn/index/" headers = { "User-Agent":UserAgent().random } # 去掉红色的警告 requests.packages.urllib3.disable_warnings() # verify= False 不需要证书 response = requests.get(url,headers=headers,verify=False) response.encoding="utf-8" # 设置编码 print(response.text) 5)、cookies: import requests from fake_useragent import UserAgent session = requests.session() # 发送请求用这个 headers = { "User-Agent":UserAgent().random } login_url = "https://www.sxt.cn/index/login/login" data = { "user": "17703181473", "password": "123456", } response = session.post(login_url,headers=headers,data=data) url = "https://www.sxt.cn/index/user.html" response = session.get(url,headers=headers) # session中有cookie print(response.text)
7、re模块:

import re str = "Iss study Python3.6 Everyday" ################## 1、match#################### result = re.match("I",str) print(result.group()) # I result = re.match("\w",str) print(result.group()) # I result = re.match(".",str) print(result.group()) # I result = re.match("\D",str) # \D 非数字 print(result.group()) # I result = re.match("i",str,re.I) # re.I忽略大小写 print(result.group()) # I result = re.match("\S",str,re.I) # \S非空格 print(result.group()) # I result = re.match("\Study",str,re.I) # \S非空格 # print(result.group()) # None 匹配不到 ###############2、search 搜索一个############### str = "Iss study Python3.6 Everyday study" result2= re.search("study",str) print(result2.group()) # study result2= re.search("st\w+",str) print(result2.group()) # study result2= re.search("P\w+.\d",str) print(result2.group()) # Python3.6 ###############3、finall 找所有内容################ str = "Iss study Python3.6 Everyday" result3 = re.findall("y",str) print(result3) # [y,y,y,y] 找到所有的字符y str2 = "<div class='info' id='info' ><a href='http://www.sxt.com'>尚学堂ewew</a></div>" result3 = re.findall("<a href='http://www.sxt.com'>(.*)</a>",str2) print(result3) # [尚学堂ewew] result3 = re.findall("<a href='http://www.sxt.com'>(.+)</a>",str2) print(result3) # [尚学堂ewew] result3 = re.findall("<a href='http://www.sxt.com'>([\u4E00-\u9FA5]\w+)</a>",str2) print(result3) # [尚学堂ewew] result3 = re.findall("<a href='(.+)'>",str2) print(result3) # ['http://www.sxt.com'] ###############4、sub 替换 ######################### str3 = "<div><a href='http://www.sxt.com'>尚学堂ewew</a></div>" result4 = re.sub('<div>(.*)</div>',r"<span>\1</span>",str3) # 记得加r print(result4) # <span><a href='http://www.sxt.com'>尚学堂ewew</a></span>
8、糗事百科案例:
import requests,re from fake_useragent import UserAgent url = "https://www.qiushibaike.com/text/page/1/" response = requests.get(url) # \s+ 是 空格 infos = re.findall('<div class="content">\s+<span>\s+(.*)\s+</span>',response.text) for info in infos: info = info.replace("<br/>","") # 去除<br/> print(info) with open("duanzi.txt","a+",encoding="utf-8") as f: f.write(info+"\n\n\n")
9、BeautifulSoup4:

from bs4 import BeautifulSoup from bs4.element import Comment str = ''' <title>尚学堂</title> <div class='info div1' float='left'>Welcome to SXT</div> <div class='info' float='right'> <span>Good Good Study</span> <a href='www.bistx.cn'></a> <strong><!--没有用--></strong> </div> ''' soup = BeautifulSoup(str,"lxml") ################1、获得标签###################### print(soup.title) # <title>尚学堂</title> 获得title标签 print(soup.div) # <div class="info" float="left">Welcome to SXT</div> 默认获得第一个 ################2、获得标签的属性################# print(soup.div.attrs) # {'class': ['info'], 'float': 'left'} 默认获得第一个div的属性 print(soup.div.get("class")) # ['info'] print(soup.div["class"]) # ['info'] print(soup.a["href"]) # www.bistx.cn ################3 、获得文本 string:NavigableString对象,text:字符串str ############ print(soup.div.string) # Welcome to SXT print(type(soup.div.string)) # <class 'bs4.element.NavigableString'> print(soup.div.text) # Welcome to SXT print(type(soup.div.text)) # <class 'str'> print(soup.strong.string) # 没有用 print(type(soup.strong.string)) # <class 'bs4.element.Comment'> 注释是Comment对象 print(soup.strong.text,type(soup.strong.text)) # "" <class 'str'> if type(soup.strong.string) == Comment: # 若是Comment对象(注释) print(soup.strong.string) # 没有用 print(soup.strong.prettify()) # <strong><!--没有用--></strong> else: print(soup.strong.text) ################4 、find_all 和 find 获得标签对象、通过属性获得标签对象############# print(soup.find_all("title")) # [<title>尚学堂</title>] 获得所有的title标签 print(soup.find_all("div")) # 获得两个div <div class='info' ... </div> <div>....</div> print(soup.find_all(float="left")) # [<div class="info div1" float="left">Welcome to SXT</div>] # class 是关键字,所以加_ print(soup.find_all(class_="div1")) # [<div class="info div1" float="left">Welcome to SXT</div>] print(soup.find_all("div",attrs={"float":"left"})) # [<div class="info div1" float="left">Welcome to SXT</div>] ################5、select 选择标签 ############
10、etree之xpath:
# 下载xpath谷歌插件:用于写xpath语句,不用每次运行代码测试 import requests from lxml import etree url = "https://www.qidian.com/rank/yuepiao?style=1" response = requests.get(url) e = etree.HTML(response.text) bookNames = e.xpath("//h4/a/text()") authors = e.xpath("//p[@class='author']/a[1]/text()") # for num in range(len(bookNames)): # print(bookNames[num]+":"+authors[num]) # 这个方法也可以同时输出书名和作者 for name,author in zip(bookNames,authors): print(name+":"+author) # 1、在scrapy中用到xpath: item_list= response.xpath(" //div[@id='content-list']/div[@class='item']") # 2、beautifulsoup用到find和find_all: soup = BeautifulSoup(response1.text,"html.parser") div = soup.find(name="div",attrs={"id":"auto-channel-lazyload-article"}) print(soup.find_all(class_="div1")) # 3、re用到findall: result3 = re.findall("<a href='http://www.sxt.com'>(.*)</a>",str2) print(result3) # [尚学堂ewew]
11、数据提取之pyquery:
pip3 install pyquery from pyquery import PyQuery as pq import requests from fake_useragent import UserAgent url="http://www.xicidaili.com/nn" headers={ "User-Agent":UserAgent().random } response = requests.get(url,headers=headers) doc = pq(response.text) trs = doc("#ip_list tr") # 找id为ip_list标签下的所有tr for num in range(1,len(trs)): ip = trs.eq(num).find("td").eq(1).text() # 注意是eq,不是[num] port = trs.eq(num).find("td").eq(2).text() type = trs.eq(num).find("td").eq(5).text() print(ip+":"+port+":"+type)
12、数据提取之jsonpath:


1)、json的dumps和load函数:
import json str = '{"name":"无名之辈"}' ################1、loads : 将json字符串转换为#json对象############# obj = json.loads(str) print(obj,type(obj)) # {'name': '无名之辈'} <class 'dict'> ################2、dumps : 将json对象转换为json字符串############## result2 = json.dumps(obj,ensure_ascii=False) print(result2,type(result2)) # {"name": "无名之辈"} <class 'str'> ##############3、dump 将json对象存进文件中,编码需要的################## json.dump(obj,open("movie.txt","w",encoding="utf-8"),ensure_ascii=False) ##############3、dump 将文件中的json字符串转换为json对象,编码需要######### str3 = json.load(open("movie.txt",encoding="utf-8")) print(str3,type(str3)) # {'name': '无名之辈'} <class 'dict'>
2)、JsonPath:
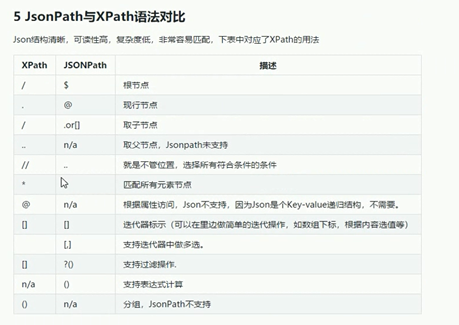
安装模块:pip3 install JsonPath
from jsonpath import jsonpath import requests,json # 拉勾网的所有市的信息 url="https://www.lagou.com/lbs/getAllCitySearchLabels.json" response = requests.get(url) names = jsonpath(json.loads(response.text),"$..name") # 必须加$ codes = jsonpath(json.loads(response.text),"$..code") for code,name in zip(codes,names): print(code+":"+name)
补充: response.text、response.content与response.json: 1、response.json:返回的是json格式数据; 2、返回的数据类型 : response.text :返回的是一个 unicode 型的文本数据; response.content :返回的是 bytes 型的二进制数据 ; 也就是说如果想取文本数据可以通过response.text 如果想取图片,文件,则可以通过 response.content; 3、数据编码 : response.content :返回的是二进制响应内容 ; response.text : 则是默认”iso-8859-1”编码,服务器不指定的话是根据网页的响应来猜测编码。
。。。。。。。。。。。。。。。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号