1. 协成函数
yield表达式形式的应用:


1 # #用法:先定义函数,给yield传值,使用是第一阶段:初始化,第二阶段:给yield传值 2 def eater(name): 3 print('%s 说:我开动啦' %name) 4 food_list=[] 5 while True: 6 food=yield food_list 7 food_list.append(food) #['骨头','菜汤'] 8 print('%s eat %s' %(name,food)) 9 10 11 def producer(): 12 alex_g=eater('alex') 13 #第一阶段:初始化 14 next(alex_g) 15 #第二阶段:给yield传值 16 while True: 17 food=input('>>: ').strip() 18 if not food:continue 19 print(alex_g.send(food)) 20 21 #解决初始化问题 22 def init(func): 23 def wrapper(*args,**kwargs): 24 g=func(*args,**kwargs) 25 next(g) 26 return g 27 return wrapper 28 29 @init 30 def eater(name): 31 print('%s 说:我开动啦' %name) 32 food_list=[] 33 while True: 34 food=yield food_list 35 food_list.append(food) #['骨头','菜汤'] 36 print('%s eat %s' %(name,food)) 37 38 def producer(): 39 alex_g=eater('alex') 40 # #第一阶段:初始化 41 # next(alex_g) 42 # #第二阶段:给yield传值 43 while True: 44 food=input('>>: ').strip() 45 if not food:continue 46 print(alex_g.send(food)) 47 producer()
2. 递归
递归调用:在调用一个函数的过程中,直接或间接地调用了函数本身。
递归的执行分为两个阶段:1.递归,2.回溯
递归效率低,需要在进入下一次递归时保留当前的状态,解决的方法是尾递归,即在函数的最后一步(而非最后一行)调用自己,但是python又没有尾递归,且对递归层级做了限制。
1. 必须有一个明确的结束条件。
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧,由于栈的大小不是无线的,所以,递归调用的次数过多,会导致栈溢)
1 #直接 2 def func(): 3 print('from func') 4 func() 5 6 func() 7 8 #间接 9 def foo(): 10 print('from foo') 11 12 def bar(): 13 print('from bar') 14 foo() 15 16 bar() 17 18 def age(n): 19 if n == 1: 20 return 18 21 return age(n-1)+2 22 23 print(age(5)) 24 25 l =[1, 2, [3, [4, 5, 6, [7, 8, [9, 10, [11, 12, 13, [14, 15,[16,[17,]],19]]]]]]] 26 27 def search(l): 28 for item in l: 29 if type(item) is list: 30 search(item) 31 else: 32 print(item) 33 34 search(l)
二分法
1 # #二分法 2 l = [1,2,5,7,10,31,44,47,56,99,102,130,240] 3 def binary_search(l,num): 4 print(l) #[10, 31] 5 if len(l) > 1: 6 mid_index=len(l)//2 #1 7 if num > l[mid_index]: 8 #in the right 9 l=l[mid_index:] #l=[31] 10 binary_search(l,num) 11 elif num < l[mid_index]: 12 #in the left 13 l=l[:mid_index] 14 binary_search(l,num) 15 else: 16 print('find it') 17 else: 18 if l[0] == num: 19 print('find it') 20 else: 21 print('not exist') 22 return 23 24 binary_search(l,32) 25 26 #二分法 27 l = [1,2,5,7,10,31,44,47,56,99,102,130,240] 28 def binary_search(l,num): 29 print(l) 30 if len(l) == 1: 31 if l[0] == num: 32 print('find it') 33 else: 34 print('not exists') 35 return 36 mid_index=len(l)//2 37 mid_value=l[mid_index] 38 if num == mid_value: 39 print('find it') 40 return 41 if num > mid_value: 42 l=l[mid_index:] 43 if num < mid_value: 44 l=l[:mid_index] 45 binary_search(l,num) 46 47 binary_search(l,32)
3. 面向编程过程
面向过程:核心是过程,过程即解决问题的步骤,基于面向过程去设计程序就像是在设计。
优点:程序结构清晰,可以把复杂的问题简单化,流程化。
缺点:可扩展性差,一条流水线只是用来解决一个问题。
应用场景:linux内核,git,httpd,shell脚本。
1 #grep -rl 'error' /dir/ 2 import os 3 def init(func): 4 def wrapper(*args,**kwargs): 5 g=func(*args,**kwargs) 6 next(g) 7 return g 8 return wrapper 9 10 #第一阶段:找到所有文件的绝对路径 11 @init 12 def search(target): 13 while True: 14 filepath=yield 15 g=os.walk(filepath) 16 for pardir,_,files in g: 17 for file in files: 18 abspath=r'%s\%s' %(pardir,file) 19 target.send(abspath) 20 # search(r'C:\Users\Administrator\PycharmProjects\python18期周末班\day5\aaa') 21 # g=search() 22 # g.send(r'C:\Python27') 23 24 #第二阶段:打开文件 25 @init 26 def opener(target): 27 while True: 28 abspath=yield 29 with open(abspath,'rb') as f: 30 target.send((abspath,f)) 31 32 #第三阶段:循环读出每一行内容 33 @init 34 def cat(target): 35 while True: 36 abspath,f=yield #(abspath,f) 37 for line in f: 38 res=target.send((abspath,line)) 39 if res:break 40 41 #第四阶段:过滤 42 @init 43 def grep(pattern,target): 44 tag=False 45 while True: 46 abspath,line=yield tag 47 tag=False 48 if pattern in line: 49 target.send(abspath) 50 tag=True 51 52 #第五阶段:打印该行属于的文件名 53 @init 54 def printer(): 55 while True: 56 abspath=yield 57 print(abspath) 58 59 g = search(opener(cat(grep('os'.encode('utf-8'), printer())))) 60 # g.send(r'C:\Users\Administrator\PycharmProjects\python18期周末班\day5\aaa') 61 62 g.send(r'C:\Users\Administrator\PycharmProjects\python18期周末班') 63 #a1.txt,a2.txt,b1.txt
4、匿名函数(lambda)
匿名函数:1、没有名字,2、函数体自带return
匿名函数的应用场景:应用于一次性的场景,临时使用(max,min,sorted,map,reduce,filter)
1 #有名函数 2 def func(x,y,z): 3 return x+y+z 4 print(func(1,2,3)) 5 6 #匿名函数 7 f=lambda x,y,z:x+y+z 8 print(f(1,2,3))
5、内置函数
注意:内置函数id()可以返回一个对象的身份,返回值为整数,这个整数通常对应与该对象在内存中的位置,但这与python的具体实现有关,不应该作为对身份的定义,即不够精准,最精准的还是以内存地址为准,is运算符用于比较两个对象的身份,等号比较两个对象的值,内置函数type()则返回一个对象的类型

1 #abs 返回整数的绝对值 2 print(abs(-1)) 3 4 #all函数用于判断给定的可迭代参数iterable中的所有元素是否不为0,'',False 或者iterable为空,如果是则返回True,否则返回False 5 def all(iterable): 6 for element in iterable: 7 if not element: 8 return False 9 return True 10 11 # >>> print(all([1,2,'a',None])) #列表,元素有为空 12 False 13 # >>> print(all([])) #列表,空列表 14 True 15 #>>> all(('a', 'b', 'c', 'd')) #元组,元素都不为空或0 16 True 17 18 #any当传入空可迭代对象时,返回False,当可迭代对象中任意一个为非空,则返回True 19 #bool值为假的情况:None,空,0,False 20 print(any([])) 21 print(any([' ',None,False])) #True 22 print(any(['',None,False])) #False 23 print(any(['',None,False,1])) #True 24 25 #bin,oct,hex 26 print(bin(10)) #把数字10转换为二进制 27 print(oct(10)) #把数字10转换为八进制 28 print(hex(10)) #把数字10转换为十六进制 29 30 #bytes 31 #unicode----encode----->bytes 即Unicode进行encode转换即得到bytes 32 print('hello'.encode('utf-8')) 33 print(bytes('hello',encoding='utf-8')) 34 35 #callable 用来检测对象是否可被调用,可被调用指的是对象加()可以运行。 36 print(callable(bytes)) 37 print(callable(abs)) 38 39 #chr可以根据ASCLL码数字,找到对应的字符 其中65到90是A-Z,97-122是a-z 40 print(chr(65)) 41 print(chr(90)) 42 print(chr(97)) 43 print(chr(122)) 44 45 #ord可根据对应的字符,找到对应的ASCLL码 46 print(ord('#')) 47 48 #complex 复数 49 #float #浮点数 50 #str #字符串 51 #list #列表 52 #tuple #元组 53 #dict #字典 54 #set #可变集合 55 #frozenset #不可变集合 56 s={1,2,3,4} #s=set({1,2,3,4}) #可以添加,删除 57 print(type(s)) 58 s.add(s(5)) 59 print(s) 60 61 s1=frozenset({1,2,3,4}) #不可以添加,删除 62 print(type(s1)) 63 64 #dir可以查看对象的属性和方法 65 import sys 66 # sys.path 67 # sys.argv 68 print(dir(sys)) 69 70 #divmod(a,b)方法返回的是a//b(除法取整)以及a对b的余数,返回结果类型为tuple,参数:a,b可以为数字(包括复数) 71 print(divmod(10,3)) 72 print(divmod(102,20)) 73 74 #enumerate 在for循环中可以把列表中的元素和其索引组成一个元组。 75 l=['a','b','c'] 76 res=enumerate(l) 77 for i in res: 78 print(i) 79 for index,item in enumerate(l): 80 print(index,item) 81 82 globals,locals #查看全局作用域和局部作用域 83 print(globals()) 84 85 #hash返回对象的哈希值,用整数表示,哈希值在字典查找时,可用于快速比较键的值,相等的数值,即使类型不一致,计算的哈希值是一样的 86 print(hash('abcdefg123')) 87 print(hash('abcdefg123')) 88 print(hash(1)) 89 print(hash(1.0)) 90 91 #help 查看帮助,及函数里的注释 92 # #给函数加文档解释,用到单引号,双引号,三引号 93 def func(): 94 ''' 95 #test function 96 #return: 97 ''' 98 pass 99 100 print(help(func)) 101 102 #id:是python解释器实现的功能,只是反映了变量在内存的地址 103 #但并不是真实的内存地址 104 x=1 105 print(id(x)) 106 107 def func():pass 108 print(id(func)) 109 print(func) 110 111 #isinstance 判断一个对象是什么类型,是返回True,否返回False 112 x=1 113 print(type(x) is int) 114 print(isinstance(x,int)) #x=int(1) 115 116 #迭代器iter,next 117 118 #len查看对象长度 119 #max同类型比较数值,取最大值 120 #min 同类型比较数值,取最小值 121 print(max([1,2,3,10])) 122 print(max(['a','b'])) 123 print(min([1,2,3,10])) 124 125 #pow 计算3的2次方,再对结果进行取模 126 print(pow(3,2,2)) #3**2%2 127 128 #range #取头不取尾 129 for i in range(1,5): 130 print(i) 131 132 # repr,str 133 print(type(str(1))) 134 print(type(repr(1))) 135 136 #reversed 功能是反转一个序列对象,将其元素从后向前颠倒构建一个新的迭代器 137 a=reversed(range(10)) 138 print(list(a)) 139 140 #slice 函数实现切片对象,主要用在切片操作函数里的参数传递 141 l=[1,2,3,4,5,6] 142 print(l[0:4:2]) 143 144 s=slice(0,4,2) 145 print(l[s]) 146 147 #sorted 排序 148 l=[1,10,4,3,-1] 149 print(sorted(l,reverse=True)) 150 151 #sum返回一个数字序列(非字符串)的和 152 print(sum([1, 2,3])) 153 print(sum(i for i in range(10))) 154 155 #vars实现返回对象object的属性和属性值的字典对象,如果默认不输入参数,就打印当前调用位置的属性和属性值,相当于locals()的功能。如果有参数输入,就只打印这个参数相应的属性和属性值 156 import m1 157 print(vars(m1) == m1.__dict__) 158 159 ##zip:拉链 160 s='hellosssssssssssssssss' 161 l=[1,2,3,4,5] 162 print(list(zip(s,l))) 163 164 #__import__,相当于import,可以接收输入的模块 165 import sys 166 m_name=input('module>>: ') 167 if m_name == 'sys': 168 m=__import__(m_name) 169 print(m) 170 print(m.path) 171 172 sys=__import__('sys') 173 print(sys) 174 175 #round四舍五入如果距离两边一样远,会保留到偶数的一边。比如round(0.5)和round(-0.5)都会保留到0,而round(1.5)会保留到2。 176 print(round(3.565,2)) 177 print(round(3.555,2)) 178 print(round(1.675, 2)) 179 print(round(2.685, 2)) #2.67 180 print(round(3.685,2)) 181 print(round(4.685,2)) 182 183 #与匿名函数结合使用 184 #max,min,sorted 185 salaries={ 186 'egon':3000, 187 'alex':100000000, 188 'wupeiqi':10000, 189 'yuanhao':2000 190 } 191 192 print(max(salaries)) 193 print(max(salaries.values())) 194 print(max(zip(salaries.values(),salaries.keys()))[1]) 195 def get_value(name): 196 return salaries[name] 197 198 print(max(salaries,key=get_value)) 199 l=[] 200 for name in salaries: 201 res=get_value(name) 202 l.append(res) 203 print(max(l)) 204 lambda name:salaries[name] 205 206 print(max(salaries,key=lambda name:salaries[name])) 207 print(min(salaries,key=lambda name:salaries[name])) 208 209 print(sorted(salaries)) 210 print(sorted(salaries,key=get_value)) 211 print(sorted(salaries,key=get_value,reverse=True)) 212 213 #map映射 214 names=['alex','wupeiqi','yuanhao','yanglei','egon'] 215 216 217 res=map(lambda x:x if x == 'egon' else x+'SB',names) 218 print(res) 219 print(list(res)) 220 221 222 def my_map(func,seq): 223 for item in seq: 224 yield func(item) 225 226 res1=my_map(lambda x:x+'_SB',names) 227 print(next(res1)) 228 print(next(res1)) 229 print(next(res1)) 230 231 #reduce函数接收的参数和 map()类似,一个函数 f,一个list,但行为和 map()不同,reduce()传入的函数 f 必须接收两个参数,reduce()对list的每个元素反复调用函数f,并返回最终结果值。 232 from functools import reduce 233 print(reduce(lambda x,y:x+y,range(101),100)) 234 print(reduce(lambda x,y:x+y,range(101))) 235 # 例如,编写一个f函数,接收x和y,返回x和y的和: 236 def f(x, y): 237 return x + y 238 # 调用reduce(f, [1, 3, 5, 7, 9])时,reduce函数将做如下计算: 239 # 先计算头两个元素:f(1, 3),结果为4; 240 # 再把结果和第3个元素计算:f(4, 5),结果为9; 241 # 再把结果和第4个元素计算:f(9, 7),结果为16; 242 # 再把结果和第5个元素计算:f(16, 9),结果为25; 243 # 由于没有更多的元素了,计算结束,返回结果25。 244 245 #filter()函数是 Python 内置的另一个有用的高阶函数,filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。 246 names=['alex_SB','wupeiqi_SB','yuanhao_SB','yanglei_SB','egon'] 247 print(list(filter(lambda name:name.endswith('SB'),names)))
1 cmd='print(x)' 2 #eval可以指定自己的作用域{全局作用域},{局部作用域} 3 eval(cmd,{'x':0},{'x':10000000}) 4 eval(cmd,{'x':0},{'y':10000000}) 5 x=0 6 #compile 编译, 7 s='for i in range(10):print(i,x)' 8 code=compile(s,'','exec') #exec编译为可执行代码 9 # print(code) 10 exec(code) 11 exec(code,{},{'x':1111}) #exec可以指定自己的作用域{全局作用域},{局部作用域}
阶段性练习:
1 文件内容如下,标题为:姓名,性别,年纪,薪资 egon male 18 3000 alex male 38 30000 wupeiqi female 28 20000 yuanhao female 28 10000 要求: 从文件中取出每一条记录放入列表中, 列表的每个元素都是{'name':'egon','sex':'male','age':18,'salary':3000}的形式 2 根据1得到的列表,取出薪资最高的人的信息 3 根据1得到的列表,取出最年轻的人的信息 4 根据1得到的列表,将每个人的信息中的名字映射成首字母大写的形式 5 根据1得到的列表,过滤掉名字以a开头的人的信息 6 使用递归打印斐波那契数列(前两个数的和得到第三个数) 0 1 1 2 3 4 7... 7 l=[1,2,[3,[4,5,6,[7,8,[9,10,[11,12,13,[14,15]]]]]]] 一个列表嵌套很多层,用递归取出所有的值
7、 模块
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1). 使用python编写的代码(.py文件)。
2). 已被编译为共享库或DLL的C或C++扩展。
3). 包好一组模块包。
4). 使用C遍写并链接到python解释器的内置模块。
8、为何要使用模块?
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更 清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来 导入其他的模块中,实现了功能的重复利用。
9、如何使用模块?
9.1 import
示例文件:spam.py,文件名spam.py,模块名spam
1 #spam.py 2 print('from the spam.py') 3 money=1000 4 def read1(): 5 print('spam->read1->money',money) 6 7 def read2(): 8 print('spam->read2 calling read') 9 read1() 10 11 def change(): 12 global money 13 money=0
9.1.1 模块可以包含可执行的语句好函数的定义,这些语句的目的的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句)如下:
1 #test.py 2 import spam #只在第一次导入时才执行spam.py内代码,此处的显式效果是只打印一次'from the spam.py',当然其他的
顶级代码也都被执行了,只不过没有显示效果. 3 import spam 4 import spam 5 import spam 6 7 ''' 8 执行结果: 9 from the spam.py 10 '''
我们可以从sys.module中找到当前已经加载的模块,sys.module是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入。
1 import sys 2 print('spam' in sys.modules) #存放的是已经加载到内的模块 3 import spam 4 print('spam' in sys.modules) 5 # import spam 6 # import spam 7 # import spam 8 # import spam 9 # import spam
9.1.2. 每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当作全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在导入时,与使用者的全局变量冲突。
1 #测试一:money与spam.money不冲突 2 #test.py 3 import spam 4 money=10 5 print(spam.money) 6 7 ''' 8 执行结果: 9 from the spam.py 10 1000 11 '''
1 #测试二:read1与spam.read1不冲突 2 #test.py 3 import spam 4 def read1(): 5 print('========') 6 spam.read1() 7 8 ''' 9 执行结果: 10 from the spam.py 11 spam->read1->money 1000 12 '''
1 #测试三:执行spam.change()操作的全局变量money仍然是spam中的 2 #test.py 3 import spam 4 money=1 5 spam.change() 6 print(money) 7 8 ''' 9 执行结果: 10 from the spam.py 11 1 12 '''
9.1.3. 总结:首次导入模块spam时会做三件事:
1). 为源文件(spam模块)创建新的名称空间,在spam中定义的函数和方法若是使用到了global时访问的就是这个名称空间。
2). 在新创建的名称空间中执行模块中包含的代码,见初始导入 import spam
3). 创建名字spam来引用该命名空间。
9.1.4. 为模块名起别名,相当于m1=1;m2=m1
1 import spam as sm 2 print(sm.money)
示范用法一;
有两种sql模块mysql和Oracle,根据用户的输入,选择不同的sql功能。
1 #mysql.py 2 def sqlparse(): 3 print('from mysql sqlparse') 4 #oracle.py 5 def sqlparse(): 6 print('from oracle sqlparse') 7 8 #test.py 9 db_type=input('>>: ') 10 if db_type == 'mysql': 11 import mysql as db 12 elif db_type == 'oracle': 13 import oracle as db 14 15 db.sqlparse()
示例用法二:
为已经导入的模块起别名的方式对编写可扩展的代码很有用,假设有两个模块xmlreader.py好csverader.py,它们都定义了函数read_data(filename):用来从文件中读取一些数据,但采用不同的输入格式,可以编写代码来选择性地挑选读取模块,例如:
1 if file_format == 'xml': 2 import xmlreader as reader 3 elif file_format == 'csv': 4 import csvreader as reader 5 data=reader.read_date(filename)
9.1.5. 在一行导入多个模块
1 import sys,os,re
10. from......import
1 from spam import read1,read2
这样在当前位置直接使用read1和read2就好了,执行时,仍然以spam.py文件全局名称空间
1 #测试一:导入的函数read1,执行时仍然回到spam.py中寻找全局变量money 2 #test.py 3 from spam import read1 4 money=1000 5 read1() 6 ''' 7 执行结果: 8 from the spam.py 9 spam->read1->money 1000 10 ''' 11 12 #测试二:导入的函数read2,执行时需要调用read1(),仍然回到spam.py中找read1() 13 #test.py 14 from spam import read2 15 def read1(): 16 print('==========') 17 read2() 18 19 ''' 20 执行结果: 21 from the spam.py 22 spam->read2 calling read 23 spam->read1->money 1000 24 '''
需要特别强调的一点是:python中的变量赋值不是一种存储操作,而只是一种绑定关系,如下:
1 from spam import money,read1 2 money=100 #将当前位置的名字money绑定到了100 3 print(money) #打印当前的名字 4 read1() #读取spam.py中的名字money,仍然为1000 5 6 ''' 7 from the spam.py 8 100 9 spam->read1->money 1000 10 '''
10.1.2 也支持as
1 from spam import read1 as read
10.1.3 也支持导入多行
1 from spam import (read1, 2 read2, 3 money)
10.1.4 from spam import * 把spam中所有的不是以下划线(_)开头的名字都导入到当前位置,大部分情况下我们的python程序不应该使用这种导入方式,因为*不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字,而且可读性极其的差,在交互环境中导入时没有问题。
1 from spam import * #将模块spam中所有的名字都导入到当前名称空间 2 print(money) 3 print(read1) 4 print(read2) 5 print(change) 6 7 ''' 8 执行结果: 9 from the spam.py 10 1000 11 <function read1 at 0x1012e8158> 12 <function read2 at 0x1012e81e0> 13 <function change at 0x1012e8268> 14 '''
可以使用__all__来控制*(用来发布新版本)
在spam.py中新增一行
__all__=['money','read1'] #这样在另外一个文件中用from spam import *就这能导入列表中规定的两个名字
10.1.5 考虑到性能的原因,每个模块被导入一次,放入字典sys.module中,如果你改变了模块的内容,你必须重启程序,python不支持重新加载或卸载之前导入的模块。
有的同学可能会想到直接从sys.module中删除一个模块不就可以卸载了吗,注意了,你删了sys.module中的模块对象仍然可能被其他程序的组件所引用,因而不会被清楚。 特别的对于我们引用了这个模块中的一个类,用这个类产生了很多对象,因而这些对象都有关于这个模块的引用。 如果只是你想交互测试的一个模块,使用 importlib.reload(), e.g. import importlib; importlib.reload(modulename),这只能用于测试环境
1 def func1(): 2 print('func1')
1 import time,importlib 2 import aa 3 4 time.sleep(20) 5 # importlib.reload(aa) 6 aa.func1()
在20秒的等待时间里,修改aa.py中func1的内容,等待test.py的结果。 打开importlib注释,重新测试
11. 把模块当做脚本执行
我们可以通过模块的全局变量__name__来查看模块名: 当做脚本运行: __name__ 等于'__main__' 当做模块导入: __name__= 作用:用来控制.py文件在不同的应用场景下执行不同的逻辑 if __name__ == '__main__':
1 #fib.py 2 3 def fib(n): # write Fibonacci series up to n 4 a, b = 0, 1 5 while b < n: 6 print(b, end=' ') 7 a, b = b, a+b 8 print() 9 10 def fib2(n): # return Fibonacci series up to n 11 result = [] 12 a, b = 0, 1 13 while b < n: 14 result.append(b) 15 a, b = b, a+b 16 return result 17 18 if __name__ == "__main__": 19 import sys 20 fib(int(sys.argv[1]))
执行
1 #python fib.py <arguments> 2 python fib.py 50 #在命令行
12. 模块搜索路径
python解释器在启动时会加载一些模块,可以使用sys.modules查看,在第一次导入某个模块时(比如spam),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用,如果没有,解释器则会查找同名的内建模块,如果还没有找到就从sys.path给出的目录列表中一次寻找spam.py文件。
所以总结模块的查找顺序是:内存中已经加载的模块-----》内置模块-----》sys.path路径中包含的模块
注意:我们自定义的模块名不应该与系统内置模块重名。
在sys.path初始化后,python程序可以修改sys.path,路径放到前面的优先于标准库被加载。
1 >>> import sys 2 >>> sys,path.append('/a/b/c/d') #在sys.path路径后添加 3 >>> sys.path.insert(0,'/x/y/z') #排在前的目录,优先被搜索
注意:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理。
1 #首先制作归档文件:zip module.zip foo.py bar.py 2 3 import sys 4 sys.path.append('module.zip') 5 import foo,bar 6 7 #也可以使用zip中目录结构的具体位置 8 sys.path.append('module.zip/lib/python') 9 10 #windows下的路径不加r开头,会语法错误 11 sys.path.insert(0,r'C:\Users\Administrator\PycharmProjects\a')
强调:只能从.zip文件中导入.py,.pyc等文件。使用c编写的共享库和扩展块无法直接从.zip文件中加载(此时setuptools等打包系统有时能提供一种规避方法),且从.zip中加载文件不会创建.pyc或者.pyo文件,因此一定要事先创建他们,来避免加载模块是性能下降。
#官网链接:https://docs.python.org/3/tutorial/modules.html#the-module-search-path 搜索路径: 当一个命名为spam的模块被导入时 解释器首先会从内建模块中寻找该名字 找不到,则去sys.path中找该名字 sys.path从以下位置初始化 执行文件所在的当前目录 PTYHONPATH(包含一系列目录名,与shell变量PATH语法一样) 依赖安装时默认指定的 注意:在支持软连接的文件系统中,执行脚本所在的目录是在软连接之后被计算的,换句话说,包含软连接的目录不会被添加到模块的搜索路径中 在初始化后,我们也可以在python程序中修改sys.path,执行文件所在的路径默认是sys.path的第一个目录,在所有标准库路径的前面。这意味着,当前目录是优先于标准库目录的,需要强调的是:我们自定义的模块名不要跟python标准库的模块名重复,除非你是故意的,傻叉。
13. 编译python文件
为了提高加载模块的速度,而非运行速度。python解释器会在__pycache__目录中下缓存每个模块编译后的版本,格式为:module.version.pyc。通常会包含python的版本号,例如,在cpython3.6版本下,spam.py模块会被缓存成__pycache__/spam.cpython-36.pyc,这种命名规范保证了编译后的结果多版本共存。
python检查源文件的修改时间与编译的版本进行对比,如果过期就需要重新编译,这是完全自动的过程。并且编译的模块是平台独立的,所以相同的库可以在不同的架构的相同之间共享,即pyc使一种跨平台的字节码,类似于JAVA火,.NET,是由python虚拟机来执行的,但是pyc的内容跟python的版本相关,不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是可以反编译的,因而它的出现是用来提升模块的加载速度的。
python解释器在以下两种情况下不检测缓存
1. 如果是在命令行中被直接导入模块,则按照这种方式,每次导入都会重新编译,并且不会存储编译后的结果(python3.3以前的版本应该是这样)
1 python -m spam.py
2. 如果源文件不存在,那么缓存的结果也不会被使用,如果想在没有源文件的情况下来使用编译后的结果,则编译后的结果必须在源目录下
test# ls __pycache__ spam.py test# rm -rf spam.py test# mv __pycache__/spam.cpython-36.pyc ./spam.pyc test# python3 spam.pyc spam
提示:
1. 模块名区分大小写,foo.py与FOO.py代表的是两个模块
2. 可以使用-O或者-OO转换python命令来减少编译模块的大小
3. 在速度上从.pyc文件中读指令来执行不会比从.py文件中读指令执行更快,只有在模块被加载时,.pyc文件才是更快。
4、只有使用import语句是才将文件自动编译为.pyc文件,在命令行或标准输入中指定运行脚本则不会生成这类文件,因而我们可以使用compieall模块为一个目录中的所有模块创建.pyc文件。
模块可以作为一个脚本(使用python -m compileall)编译Python源 python -m compileall /module_directory 递归着编译 如果使用python -O -m compileall /module_directory -l则只一层 命令行里使用compile()函数时,自动使用python -O -m compileall 详见:https://docs.python.org/3/library/compileall.html#module-compileall
14 . 包
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
1. 无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
2. 包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
3. import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
强调:
1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
包A和包B下有相同的模块也不会冲突,如A.a与B.a来自两个命名空间
├── api │ ├── __init__.py │ ├── policy.py │ └── versions.py ├── cmd │ ├── __init__.py │ └── manage.py ├── db │ ├── __init__.py │ └── models.py └── __init__.py
1 #文件内容 2 3 #policy.py 4 def get(): 5 print('from policy.py') 6 7 #versions.py 8 def create_resource(conf): 9 print('from version.py: ',conf) 10 11 #manage.py 12 def main(): 13 print('from manage.py') 14 15 #models.py 16 def register_models(engine): 17 print('from models.py: ',engine)
14.1 注意事项
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。 2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。 3.对比import item 和from item import name的应用场景: 如果我们想直接使用name那必须使用后者。
14.2 import
在与包glance同级别的文件中测试
1 import glance.db.models 2 glance.db.models.register_models('mysql')
14.3 from.....import....
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c 是错误语法
我们在与包glance同级别的文件中测试
1 from glance.db import models 2 models.register_models('mysql') 3 4 from glance.db.models import register_models 5 register_models('mysql')
14.4 __init__.py文件
不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件(我们可以在每个包的文件内都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码。
14.5、from glance.api import *
此处是想从包api中导入所有,实际上该语句只会导入包api__init__.py文件中定义的名字,我们可以在这个文件中定义__all__:
1 #在__init__.py中定义 2 x=10 3 4 def func(): 5 print('from api.__init.py') 6 7 __all__=['x','func','policy']
此时我们在于glance同级的文件中执行from glance.api import * 就导入__all__中的内容。
14.6、绝对导入和相对导入
最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间相互导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始。
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
例如:我们在glance/api/version.py中想要导入glance/cmd/manage.py
1 在glance/api/version.py 2 3 #绝对导入 4 from glance.cmd import manage 5 manage.main() 6 7 #相对导入 8 from ..cmd import manage 9 manage.main()
测试结果:注意一定要在于glance同级的文件中测试
1 from glance.api import versions
注意:在使用pytharm时,有的情况会为你多做一些事情,这是软件相关的东西,会影响你对模块导入的理解,因而在测试时,一定要回命令行去执行,模拟生产环境。
特别需要注意的是:可以用import导入内置或者第三方模块(已经在sys.path中),但是要绝对避免使用from...import...的绝对或者相对导入,且包的相对导入只能用from的形式。
14.7、单独导入包
单独导入包名称时不会导入包中所有包含的所有子模块,如
1 #在与glance同级的test.py中 2 import glance 3 glance.cmd.manage.main() 4 5 ''' 6 执行结果: 7 AttributeError: module 'glance' has no attribute 'cmd' 8 9 '''
解决方法;
1 #glance/__init__.py 2 from . import cmd 3 4 #glance/cmd/__init__.py 5 from . import manage
执行:
1 #在于glance同级的test.py中 2 import glance 3 glance.cmd.manage.main()
注意:__all__不能解决,__all__是用于控制from....import * 。
15、软件开发规范
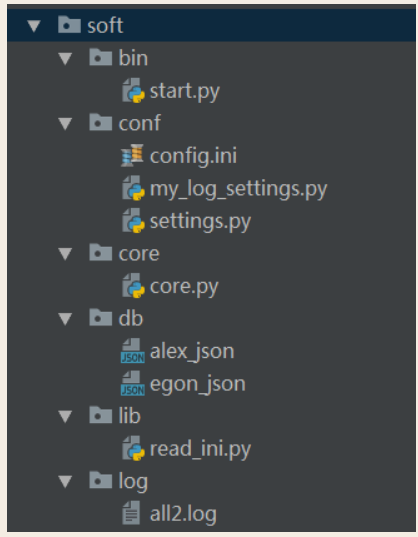
1 #=============>bin目录:存放执行脚本 2 #start.py 3 import sys,os 4 5 BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) 6 sys.path.append(BASE_DIR) 7 8 from core import core 9 from conf import my_log_settings 10 11 if __name__ == '__main__': 12 my_log_settings.load_my_logging_cfg() 13 core.run() 14 15 #=============>conf目录:存放配置文件 16 #config.ini 17 [DEFAULT] 18 user_timeout = 1000 19 20 [egon] 21 password = 123 22 money = 10000000 23 24 [alex] 25 password = alex3714 26 money=10000000000 27 28 [yuanhao] 29 password = ysb123 30 money=10 31 32 #settings.py 33 import os 34 config_path=r'%s\%s' %(os.path.dirname(os.path.abspath(__file__)),'config.ini') 35 user_timeout=10 36 user_db_path=r'%s\%s' %(os.path.dirname(os.path.dirname(os.path.abspath(__file__))),\ 37 'db') 38 39 40 #my_log_settings.py 41 """ 42 logging配置 43 """ 44 45 import os 46 import logging.config 47 48 # 定义三种日志输出格式 开始 49 50 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ 51 '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 52 53 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' 54 55 id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' 56 57 # 定义日志输出格式 结束 58 59 logfile_dir = r'%s\log' %os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # log文件的目录 60 61 logfile_name = 'all2.log' # log文件名 62 63 # 如果不存在定义的日志目录就创建一个 64 if not os.path.isdir(logfile_dir): 65 os.mkdir(logfile_dir) 66 67 # log文件的全路径 68 logfile_path = os.path.join(logfile_dir, logfile_name) 69 70 # log配置字典 71 LOGGING_DIC = { 72 'version': 1, 73 'disable_existing_loggers': False, 74 'formatters': { 75 'standard': { 76 'format': standard_format 77 }, 78 'simple': { 79 'format': simple_format 80 }, 81 }, 82 'filters': {}, 83 'handlers': { 84 #打印到终端的日志 85 'console': { 86 'level': 'DEBUG', 87 'class': 'logging.StreamHandler', # 打印到屏幕 88 'formatter': 'simple' 89 }, 90 #打印到文件的日志,收集info及以上的日志 91 'default': { 92 'level': 'DEBUG', 93 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 94 'formatter': 'standard', 95 'filename': logfile_path, # 日志文件 96 'maxBytes': 1024*1024*5, # 日志大小 5M 97 'backupCount': 5, 98 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 99 }, 100 }, 101 'loggers': { 102 #logging.getLogger(__name__)拿到的logger配置 103 '': { 104 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 105 'level': 'DEBUG', 106 'propagate': True, # 向上(更高level的logger)传递 107 }, 108 }, 109 } 110 111 112 def load_my_logging_cfg(): 113 logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置 114 logger = logging.getLogger(__name__) # 生成一个log实例 115 logger.info('It works!') # 记录该文件的运行状态 116 117 if __name__ == '__main__': 118 load_my_logging_cfg() 119 120 #=============>core目录:存放核心逻辑 121 #core.py 122 import logging 123 import time 124 from conf import settings 125 from lib import read_ini 126 127 config=read_ini.read(settings.config_path) 128 logger=logging.getLogger(__name__) 129 130 current_user={'user':None,'login_time':None,'timeout':int(settings.user_timeout)} 131 def auth(func): 132 def wrapper(*args,**kwargs): 133 if current_user['user']: 134 interval=time.time()-current_user['login_time'] 135 if interval < current_user['timeout']: 136 return func(*args,**kwargs) 137 name = input('name>>: ') 138 password = input('password>>: ') 139 if config.has_section(name): 140 if password == config.get(name,'password'): 141 logger.info('登录成功') 142 current_user['user']=name 143 current_user['login_time']=time.time() 144 return func(*args,**kwargs) 145 else: 146 logger.error('用户名不存在') 147 148 return wrapper 149 150 @auth 151 def buy(): 152 print('buy...') 153 154 @auth 155 def run(): 156 157 print(''' 158 购物 159 查看余额 160 转账 161 ''') 162 while True: 163 choice = input('>>: ').strip() 164 if not choice:continue 165 if choice == '1': 166 buy() 167 168 169 170 if __name__ == '__main__': 171 run() 172 173 #=============>db目录:存放数据库文件 174 #alex_json 175 #egon_json 176 177 #=============>lib目录:存放自定义的模块与包 178 #read_ini.py 179 import configparser 180 def read(config_file): 181 config=configparser.ConfigParser() 182 config.read(config_file) 183 return config 184 185 #=============>log目录:存放日志 186 #all2.log 187 [2017-07-29 00:31:40,272][MainThread:11692][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] 188 [2017-07-29 00:31:41,789][MainThread:11692][task_id:core.core][core.py:25][ERROR][用户名不存在] 189 [2017-07-29 00:31:46,394][MainThread:12348][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] 190 [2017-07-29 00:31:47,629][MainThread:12348][task_id:core.core][core.py:25][ERROR][用户名不存在] 191 [2017-07-29 00:31:57,912][MainThread:10528][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] 192 [2017-07-29 00:32:03,340][MainThread:12744][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] 193 [2017-07-29 00:32:05,065][MainThread:12916][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] 194 [2017-07-29 00:32:08,181][MainThread:12916][task_id:core.core][core.py:25][ERROR][用户名不存在] 195 [2017-07-29 00:32:13,638][MainThread:7220][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] 196 [2017-07-29 00:32:23,005][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] 197 [2017-07-29 00:32:40,941][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] 198 [2017-07-29 00:32:47,222][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] 199 [2017-07-29 00:32:51,949][MainThread:7220][task_id:core.core][core.py:25][ERROR][用户名不存在] 200 [2017-07-29 00:33:00,213][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] 201 [2017-07-29 00:33:50,118][MainThread:8500][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] 202 [2017-07-29 00:33:55,845][MainThread:8500][task_id:core.core][core.py:20][INFO][登录成功] 203 [2017-07-29 00:34:06,837][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在] 204 [2017-07-29 00:34:09,405][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在] 205 [2017-07-29 00:34:10,645][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号