1. 文件处理流程
1). 打开文件,等到文件句柄并赋值给一个变量
2). 通过句柄对文件进行操作
3). 关闭文件
2. 文件基本操作
2.1 文件操作基本流程


1 f=open('user','r') 2 line_data=f.readline() #读取一行 3 print(line_data) #打印一行 4 print('分割线'.center(30,'=')) 5 data=f.read() #读取剩余 6 print(data) #打印读取内容 7 f.close() #关闭文件 8 9 with open('test','r',encoding='utf-8') as f1: #这样打开文件,不需要直接关闭文件,执行完程序,会自动关闭文件 10 l=f1.readlines() #会把文件内容全部读出变为列表形式,可以加参数,指定读取文件的大小 11 print(l) 12 for line in l: 13 print(line)
2.2 字符编码
文件保存编码如下:
此刻错误的打开方式:
f=open('test','r',encoding='utf-8') f.read()
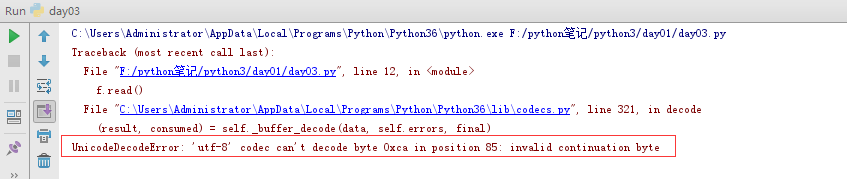
正确的打开方式:
#不指定打开编码,用操作系统默认编码,windows 系统默认编码是gbk,linux系统一般是utf8编码 f=open('test','r',encoding='gbk') #打开文件test,字符编码是gbk,这里是windows平台,不指定编码也可以 data=f.read() f.close() print(data)
2.3. 文件打开方式
文件句柄 = open('文件','打开模式')
打开文件时,需要指定文件路径和以何等方式打开文件,打开文件以后,即可获取该文件句柄,日后通过此文件文件句柄对该文件操作
打开文件的模式有:
- r,只读模式(默认模式,文件必须存在,不存在会报错)
- w,只写模式(不可读,文件不存在则创建,会清空文件)
- a,追加模式(可读,不存在则创建,存在则只追加)
“+”表示可以同时读写某个文件
- r+,读写(可读,可写)
- w+,写读(可写,可读)
- a+,写读(可写,可读)
“b”表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- ab 或 a+b
注:以b的方式打开时,读取到的内容是字节类型,写入是也要指定为字节类型,不能指定字符编码。
练习 利用b模式,编写一个cp工具,要求如下:
1.即可以拷贝文本,也可以拷贝视频,图片等文件
2. 用户一旦参数错误,打印命令的正确使用方法,如:usage :cp source_file target_file
提示:可以使用 import sys
1 import sys #导入模块 2 sys.argv 3 if len(sys.argv) < 3: 4 print('usage :cp source_file target_file') 5 sys.exit() 6 with open(r'%s'%sys.argv[1],'rb') as read_f,open(r'%s'%sys.argv[2],'wb') as write_f: 7 for line in read_f: 8 write_f.write(line)
2.4 文件内光标移动
1)read(3)
a.文件打开方式为文本模式时,代表读取3个字符
b.文件打开方式为b模式时,代表读取3个字节
2)其余的文件内的光标移动都是以字节为单位如seek,tell,truncate
注意:
a. seek有3种光标移动方式0,1,2,其中1,2必须在b模式下,但无论那种模式,都是以bytes为单位移动的
b.truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+的方式打开文件,因为那样直接清空文件了,所以truncate要在r+或a或a+模式下测试效果
1 with open('user','r') as f: 2 print(f.read(3)) #读取3个字符 3 print(f.tell()) #光标在第3个字符后 4 5 with open('user','rb') as f: 6 print(f.read(3)) 7 f.seek(0) #光标移到开头 8 print(f.tell()) 9 10 f.seek(0,1) #光标从当前位置开始 11 print(f.read()) 12 13 f.seek(1,1) #光标从当前位置的第2个开始 14 print(f.tell()) 15 16 f.seek(0,2) #光标移动到结尾 17 print(f.tell()) 18 19 f.seek(-1,2) #光标移动到倒数第一个字节前 20 print(f.read().decode('utf-8')) 21 print(f.tell()) 22 23 with open('test','r+',encoding='utf-8') as f: 24 f.truncate(64) #把文章截断,只要64个字节,其他的删除 25 data=f.read() 26 print(data)
2.5 文件的修改
1 import os 2 with open('test','r',encoding='utf-8') as read_f,\ 3 open('test.swap','w',encoding='utf-8') as write_f: 4 for line in read_f: 5 if line.endswith('hello world'): 6 line='哈哈哈\n' 7 write_f.write(line) 8 os.remove('test') 9 os.rename('test.swap','test')
3. 函数
3.1 为什么有用函数
- 不同函数感觉代码的组织结构不清晰
- 代码冗余
- 无法统一管理维护难度大
3.2 函数的分类
- 内置函数
- 自定义函数
3.3 为何要定义函数
- 函数即变量,变量必须先定义后使用,未定义而直接引用函数,就相当于一个在引用一个不存在的变量名代码演示
3.4 函数的使用
- 先定义
- 再调用
3.5 函数定义阶段
只检测语法,不执行代码
1 def foo(): 2 print('from foo') 3 bar() 4 5 def bar(): 6 print('from bar') 7 8 foo()
3.6 定义函数(函数名要能反映其意义)及语法
函数的语法:
def 函数名(arg1,arg2,arg3):
#注释
函数体
return 返回值
函数名一般是动词,arg1 是参数,一个函数内部可以有多个return,但是只执行一次,函数就结束调用,并且会把return后面的值作为函数的执行结果返回
3.7 函数的定义的3种形式
- 无参函数,应用场景仅仅只是执行一些操作,比如,用户交互,打印
- 有参函数,需要根据外部传进来的参数,才能执行相应的逻辑,比如统计长度,求最大值最小值。
- 空函数,设计代码结构
1 def foo(): 2 print('from foo') 3 foo() 4 5 def my_max(x,y): 6 if x > y : 7 return x 8 else: 9 return y 10 res=my_max(2,3) 11 print(res) 12 13 def select(): 14 #select function 15 pass 16 17 def insert(): 18 #insert function 19 pass
3.8 函数的调用
1)先找到函数名
2)再根据名字调用代码
3 )函数的返回值
1 大前提:return的返回值没有类型限制 2 1. 没有return:返回None,等同于return None 3 2. return 一个值:返回该值 4 3. return val1,val2,val3:返回(val1,val2,val3)
1 def func(): 2 print('from func') 3 # return [1,2,3],'a',1,{'a':3} 4 res=func() 5 print(res) 6 7 def func(): 8 print('from func') 9 return [1,2,3],'a',1,{'a':3} 10 res=func() 11 print(res)
返回值什么时候该有?
通常调用函数,经过一系列的操作,最后要拿到一个明确的结果,则必须要有返回值
通常有参函数需要返回值,输入参数,经过计算,得到一个最终计算
返回值什么时候不需要有?
通常调用函数,仅仅执行一系列操作,最后不需要一个明确的结果,则无需返回值
通常无参函数不需要有
4 .函数调用的3种形式
- 语句形式:foo()
- 表达式形式:res=my_max(2,3)*10
- 当中另一个函数的参数:range(len('hello world'))
1 def my_max(x,y): 2 if x > y: 3 return x 4 else: 5 return y 6 7 my_max(1,2) #语句形式 8 res=my_max(1,2)*10 #表达式形式 9 res2=my_max(my_max(1,2),3) #函数调用可以当做另外一个函数的参数 10 print(res2)
5. 函数的参数
1)形参和实参的定义:
1 def my_max(x,y): #x,y是形参 2 if x > y : 3 return x 4 else: 5 return y 6 res=my_max(2,3) #2,3是实参 7 print(res)
2) 形参即变量名,实参即变量值,函数调用则值绑定到名字上,函数执行完毕,解除绑定
3) 具体应用
位置参数:按照从左到右的顺序定义参数
位置形参:必选参数
位置实参:按照位置为形参传值
关键字参数:按照key=value的形式定义参数
无需按照位置为形参传值
注意的问题:
a. 关键字实参必须在位置实参的右边
b. 对同一形参不能重复传值
默认参数:形参在定义时就已经为其赋值
可以传值也可以不传值,经常需要变动参数的定义为位置形参,变动较小的参数定义为默认参数(形参)
注意的问题:
a.只在定义时赋值一次
b.默认参数的定义在位置形参的右边
c.默认参数通常定义为不可变类型
可变长参数:
针对实参在定义时长度不固定的情况,应该从形参的角度找到可以接收可变长实参的方案,这就是可变长参数(实参)
而实参有按位置和关键字两种定义方式,针对这两种形式的可变长,形参也应该有两种解决方案,分别是*args,**kwargs
1 #=========*args========= 2 def foo(x,y,*args): 3 print(x,y) 4 print(args) 5 foo(1,2,3,4,5,6) 6 7 def foo(x,y,*args): 8 print(x,y) 9 print(args) 10 foo(1,2,*[3,4,5,6]) 11 12 def foo(x,y,z): 13 print(x,y) 14 print(z) 15 foo(*[1,2,3]) 16 17 #========**kwargs====== 18 def foo(x,y,**kwargs): 19 print(x,y) 20 print(kwargs) 21 foo(1,2,z=3,a=4,b=5,d=6) 22 23 def foo(x,y,**kwargs): 24 print(x,y) 25 print(kwargs) 26 foo(1,y=2,**{'z': 3, 'a': 4, 'b': 5, 'd': 6}) 27 28 def foo(x,y,z): 29 print(x,y,z) 30 foo(**{'x':1,'y':2,'z':3}) 31 32 #====*args,**kwargs===== 33 def foo(x,y,z): 34 print(x,y,z) 35 36 def wrapper(*args,**kwargs): 37 print('========>') 38 foo(*args,**kwargs) 39 wrapper(1,2,3) 40 ###这个可以测试函数的运行时间 41 import time 42 def register(name,age,sex='male'): 43 start_time=time.time() 44 print(name) 45 print(age) 46 print(sex) 47 time.sleep(3) 48 stop_time=time.time() 49 print('run time is %s' %(stop_time-start_time)) 50 51 def wrapper(*args, **kwargs): #args=('egon',) kwargs={'age':18} 52 start_time=time.time() 53 register(*args, **kwargs) 54 stop_time=time.time() 55 print('run time is %s' %(stop_time-start_time)) 56 57 wrapper('egon',age=18)
命名关键字参数:*后定义的参数,必须被传值(有默认值除外),且必须按照关键字实参的形式传递可以保证,传入的参数一定包含某些关键字
1 def foo(x,y,*args,a=1,b,**kwargs): 2 print(x,y) 3 print(args) 4 print(a) 5 print(b) 6 print(kwargs) 7 8 foo(1,2,3,4,5,6,a=1,b=2,c=3,d=5,e=6) 9 #结果: 10 1 2 11 (3, 4, 5, 6) 12 1 13 2 14 {'c': 3, 'd': 5, 'e': 6}
6.练习
1 1、写函数,,用户传入修改的文件名,与要修改的内容,执行函数,完成批了修改操作 2 2、写函数,计算传入字符串中【数字】、【字母】、【空格] 以及 【其他】的个数 3 3、写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5。 4 4、写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。 5 5、写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。 6 6、写函数,检查字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。 7 dic = {"k1": "v1v1", "k2": [11,22,33,44]} 8 PS:字典中的value只能是字符串或列表
1 # 1、写函数,,用户传入修改的文件名,与要修改的内容,执行函数,完成批了修改操作 2 def rename_f(filename,old,new): 3 import os 4 with open(filename,'r',encoding='utf-8') as read_f,\ 5 open('.bak.swap','w',encoding='utf-8') as write_f: 6 for line in read_f: 7 if old in line: 8 line=line.replace(old,new) 9 write_f.write(line) 10 os.remove(filename) 11 os.rename('.bak.swap',filename) 12 rename_f('user.txt','test1','stu') 13 # 2、写函数,计算传入字符串中【数字】、【字母】、【空格] 以及 【其他】的个数 14 def check_str(msg): 15 res={ 16 'num':0, 17 'string':0, 18 'space':0, 19 'other':0 20 } 21 for s in msg: 22 if s.isdigit(): 23 res['num']+=1 24 elif s.isalpha(): 25 res['string']+=1 26 elif s.isspace(): 27 res['space']+=1 28 else: 29 res['other']+=1 30 return res 31 res=check_str('hello name:aSB passowrd:alex3714') 32 print(res) 33 # 3、写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5。 34 def func1(seq): 35 if len(seq) > 5: 36 return True 37 else: 38 return False 39 print(func1([1,2,3,4,5,6])) 40 41 # 4、写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。 42 def func1(seq): 43 if len(seq) > 2: 44 seq=seq[0:2] 45 return seq 46 print(func1([1,2,3,4])) 47 # 5、写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。 48 def func2(seq): 49 return seq[::2] 50 print(func2([1,2,3,4,5,6,7])) 51 52 # 6、写函数,检查字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。 53 # dic = {"k1": "v1v1", "k2": [11,22,33,44]} 54 # PS:字典中的value只能是字符串或列表 55 def check_dic(dic): 56 d={} 57 for k,v in dic.items(): 58 if len(v) >2: 59 d[k]=v[0:2] 60 return d 61 print(check_dic({"k1": "v1v1", "k2": [11,22,33,44]}))
7.函数对象
函数对象:函数是第一类对象,即函数可以当作数据传递
1)可以被引用
2)可以当作参数传递
3)返回值可以是函数
4)可以当作容器类型的元素
1 # 利用该特性,优雅的取代多分支的if 2 def foo(): 3 print('foo') 4 5 def bar(): 6 print('bar') 7 8 dic = { 9 'foo': foo, 10 'bar': bar, 11 } 12 while True: 13 choice = input('>>: ').strip() 14 if choice in dic: 15 dic[choice]()
作业:
有以下员工信息表
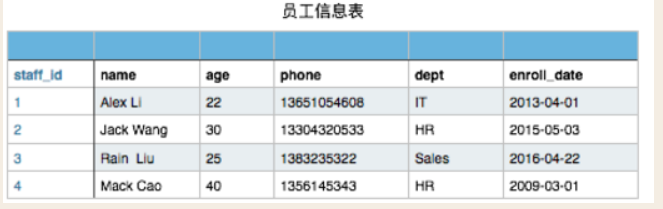
此表在文件存储是可以这样表示:
1,Alex Li,22,13651054608,IT,2013-04-01
现需要对这个员工信息文件,实现增删改查操作 1. 可进行模糊查询,语法至少支持下面3种: 1. select name,age from staff_table where age > 22 2. select * from staff_table where dept = "IT" 3. select * from staff_table where enroll_date like "2013" 4. 查到的信息,打印后,最后面还要显示查到的条数 2. 可创建新员工纪录,以phone做唯一键,staff_id需自增 3. 可删除指定员工信息纪录,输入员工id,即可删除 4. 可修改员工信息,语法如下: UPDATE staff_table SET dept="Market" WHERE where dept = "IT" 注意:以上需求,要充分使用函数,请尽你的最大限度来减少重复代码!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号