

面向对象的三大特性:封装,继承和多态
一 继承
1 什么是继承:1.1 什么是什么的关系。一个类是另一个类的子类。
1.2 继承是一种创新类的方式。新建的类可以继承一个或多个父类。父类又称为基类或超类,新建的类又称为派生类或子类
继承一个父类叫做单继承;继承多个父类叫做多继承。
2 继承的好处:减少代码的冗余,增强了代码的重用性。
二 继承的用法
super:调用父类的功能和方法
格式一:在子类的内部调用父类的属性和方法
class 父类名:
def 属性(self):
功能
class 子类名(父类名):
def 属性(self):
super().属性名
class A:
def aa(self):
print(11)
class B(A):
def aa(self):
super().aa()
b=B()
b.aa()
在子类的内部调用父类的功能和方法可以不用传入参数,可以直接(super().属性名)就可以调用
查看继承
查看类继承了哪个父类的方式:子类名.__bases__
|
1
2
3
4
|
>>> SubClass1.__bases__ #__base__只查看从左到右继承的第一个子类,__bases__则是查看所有继承的父类(<class '__main__.ParentClass1'>,)>>> SubClass2.__bases__(<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>) |
提示:如果没有指定基类,python的类会默认继承object类,object是所有python类的基类,它提供了一些常见方法(如__str__)的实现。
1 >>> ParentClass1.__bases__ 2 (<class 'object'>,) 3 >>> ParentClass2.__bases__ 4 (<class 'object'>,)
在python3中,所有类默认继承object(在python3当中所有类都是新式类)
但凡是继承了object类的子类以及该子类的子类,都称为新式类
没有继承object类的子类成为经典类(在python2 中,没有继承object类,以及它的子类,都是经典类。)
格式二:在子类的外部调用父类的功能和方法
class 父类名:
def 属性(self):
功能
class 子类名(父类名):
pass
对象=子类名()
super(子类名,对象).属性()
# class A: # def aa(self): # print(11) # class B(A): # pass # b=B() # super(B,b).aa()
在子类外部调用父类的属性和方法是,必须要给super传入两个参数,一个是子类名,一个是对象名:super(子类名,对象).属性()
在多继承的时候,super继承的是第一个父类。
super:新式类调用父类的方法。super找到有该方法或属性的第一个父类。
# class People:
# def __init__(self,name,age,sex):
# self.name=name
# self.age=age
# self.sex=sex
# class Nan:
# pass
# class Student(Nan,People):
# def __init__(self,name,age,sex):
# super().__init__(name,age,sex)
# fang=Student('fang','男',18)
# print(fang.name)
父类名.__init__(self):经典类调用父类方法和属性的方式。
# class People:
# def __init__(self,name,age,sex):
# self.name=name
# self.age=age
# self.sex=sex
# class Nan:
# pass
# class Student(Nan,People):
# def __init__(self,name,age,sex):
# People.__init__(self,name,age,sex)
# fang=Student('fang','男',18)
# print(fang.name)
继承中子类可以继承父类的所有属性和方法
# class People:
# def __init__(self,name,age,sex):
# self.name=name
# self.age=age
# self.sex=sex
# class Nan:
# pass
# class Student(Nan,People):
# def __init__(self,name,age,sex):
# People.__init__(self,name,age,sex)
# fang=Student('fang','男',18)
# print(fang.name)
当子类和父类中有同名的方法和属性时,一定是调用自己的。
如果想要调用父类的方法和属性时,需要借用super来调用。
对象剋有调用自己和父类的所有方法和属性,首先是调用自己的,自己没有在去调用父类的。
谁(对象)调用方法,self就会指向谁。
自己私有的方法叫做派生方法;自己私有的属性叫做派生属性。
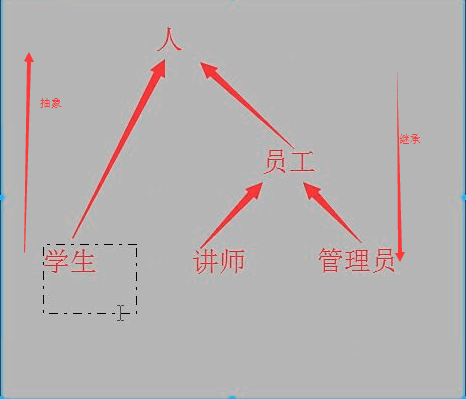
从下到上叫做抽象,从上到下就叫做继承。
继承与抽象(先抽象再继承)
抽象即抽取类似或者说比较像的部分。
解决代码重用的问题,减少代码冗余
继承是一种什么‘是’什么的关系
抽象分成两个层次:
1.将奥巴马和梅西这俩对象比较像的部分抽取成类;
2.将人,猪,狗这三个类比较像的部分抽取成父类。
抽象最主要的作用是划分类别(可以隔离关注点,降低复杂度)

继承:是基于抽象的结果,通过编程语言去实现它,肯定是先经历抽象这个过程,才能通过继承的方式去表达出抽象的结构。
抽象只是分析和设计的过程中,一个动作或者说一种技巧,通过抽象可以得到类

继承的实现原理
1 继承的实现顺序
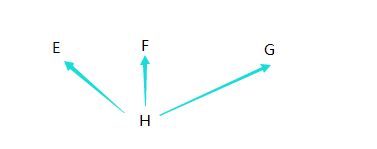 从左到有依次查找,
从左到有依次查找, 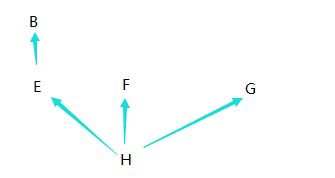 每一个分支查找完了才进行下一个分支的查找
每一个分支查找完了才进行下一个分支的查找
在新式类中每个分支属于同一个父类的时候查找的顺序是如下
 这种属于广度优先,就是在新式类中,查找从左到右每个分支依次查找完毕过后,最后在查找他们共同的父类。
这种属于广度优先,就是在新式类中,查找从左到右每个分支依次查找完毕过后,最后在查找他们共同的父类。
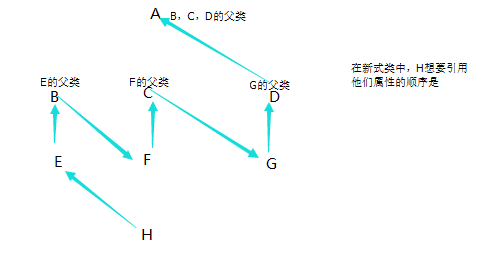
在经典类中每个分支属于同一个父类的时候查找的顺序是如下
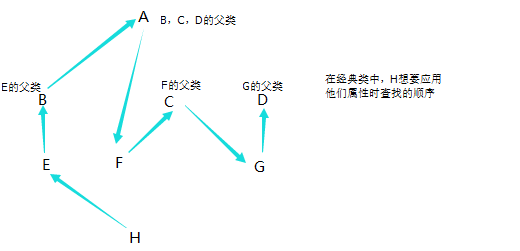 这种属于深度查找,就是在经典类中,从左到右,每个分支查找到底,在进行下一个分支的查找,但是在他们共同父类第一次查找过后,就不会在查找他们共同的父类了。
这种属于深度查找,就是在经典类中,从左到右,每个分支查找到底,在进行下一个分支的查找,但是在他们共同父类第一次查找过后,就不会在查找他们共同的父类了。



class A(object): def test(self): print('from A') class B(A): def test(self): print('from B') class C(A): def test(self): print('from C') class D(B): def test(self): print('from D') class E(C): def test(self): print('from E') class F(D,E): # def test(self): # print('from F') pass f1=F() f1.test() print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性 #新式类继承顺序:F->D->B->E->C->A #经典类继承顺序:F->D->B->A->E->C #python3中统一都是新式类 #pyhon2中才分新式类与经典类
2 继承原理(python如何实现的继承)
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如
>>> F.mro() #等同于F.__mro__ [<class '__main__.F'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
子类调用父类的方法
子类继承了父类的方法,然后想进行修改,注意了是基于原有的基础上修改,那么就需要在子类中调用父类的方法
方法一:父类名.父类方法()
# class People: # def __init__(self,name,age,sex): # self.name=name # self.age=age # self.sex=sex # def foo(self): # print('from your') # class Teacher(People): # def __init__(self,name,age,sex,level,salary): # People.__init__(self,name,age,sex) #指名道姓的调用People类的__init__的函数 # self.level=level # self.salary=salary # def foo(self): # print('from sb') # t1=Teacher('egon',81,'girl',-10,3000) # t1.foo()
方法二:super()
# class People: # def __init__(self,name,age,sex): # self.name=name # self.age=age # self.sex=sex # def foo(self): # print('from your') # class Teacher(People): # def __init__(self,name,age,sex,level,salary): # super().__init__(name,age,sex) #调用的是父类__init__的功能,实际上是调用父类的绑定方法 # self.level=level # self.salary=salary # def foo(self): # super().foo() # print('from sb') # t1=Teacher('egon',81,'girl',-10,3000) # t1.foo()
当你使用super()函数时,Python会在MRO列表上继续搜索下一个类。只要每个重定义的方法统一使用super()并只调用它一次,那么控制流最终会遍历完整个MRO列表,每个方法也只会被调用一次(注意注意注意:使用super调用的所有属性,都是从MRO列表当前的位置往后找,千万不要通过看代码去找继承关系,一定要看MRO列表)
在python中使用super()时括号里需要加上类名和自己,如下
#python2中super()的使用方法是 # class People: # def __init__(self,name,age,sex): # self.name=name # self.age=age # self.sex=sex # def foo(self): # print('from your') # class Teacher(People): # def __init__(self,name,age,sex,level,salary): # super(Teacher.srlf).__init__(name,age,sex) #调用的是父类__init__的功能,实际上是调用父类的绑定方法 # self.level=level # self.salary=salary # def foo(self): # super(Teacher.self).foo() # print('from sb') # t1=Teacher('egon',81,'girl',-10,3000) # t1.foo()
二 接口与归一化设计
什么是接口?接口只是定义了一些方法,而没有去实现,多用于程序设计时,只是设计需要有什么样的功能,但是并没有实现任何功能,这些功能需要被另一个类(B)继承后,由 类B去实现其中的某个功能或全部功能。,
继承有两种用途:
1 继承基类的方法,并且做出自己的改变或者扩展(代码重用)
2 声明某个子类兼容于某基类,定义一个接口类Interface,接口类中定义了一些接口名(就是函数名)且并未实现接口的功能,子类继承接口类,并且实现接口中的功能


1 # class Interface: #定义接口Interface类来模仿接口的概念,python中压根就没有interface关键字
2 # def read(self): #定接口函数read
3 # pass
4 # def write(self): #定接口函数write
5 # pass
6 # class Txt(Interface): #文本,具体实现read和write
7 # def read(self):
8 # print('文本数据的读取方法')
9 # def write(self):
10 # print('文本数据的写入方法')
11 # class Sata(Interface): #硬盘,具体实现read和write
12 # def read(self):
13 # print('硬盘数据的读取方法')
14 # def write(self):
15 # print('硬盘数据的写入方法')
16 # class Process(Interface):
17 # def read(self):
18 # print('进程数据的读取方法')
19 # def write(self):
20 # print('进程数据的写入方法')
21 #
22 #
23 # txt=Txt()
24 # disk=Sata()
25 # process=Process()
26 #
27 #
28 # txt.read()
29 # disk.read()
30 # process.read()
实践中,继承的第一种含义意义并不很大,甚至常常是有害的。因为它使得子类与基类出现强耦合。
继承的第二种含义非常重要。它又叫“接口继承”。
接口继承实质上是要求“做出一个良好的抽象,这个抽象规定了一个兼容接口,使得外部调用者无需关心具体细节,可一视同仁的处理实现了特定接口的所有对象”——这在程序设计上,叫做归一化。
归一化使得高层的外部使用者可以不加区分的处理所有接口兼容的对象集合——就好象linux的泛文件概念一样,所有东西都可以当文件处理,不必关心它是内存、磁盘、网络还是屏幕(当然,对底层设计者,当然也可以区分出“字符设备”和“块设备”,然后做出针对性的设计:细致到什么程度,视需求而定)。
在python中根本就没有一个叫做interface的关键字,上面的代码只是看起来像接口,其实并没有起到接口的作用,子类完全可以不用去实现接口 ,如果非要去模仿接口的概念,可以借助第三方模块:
为何要用接口
接口提取了一群类共同的函数,可以把接口当做一个函数的集合。
然后让子类去实现接口中的函数。
这么做的意义在于归一化,什么叫归一化,就是只要是基于同一个接口实现的类,那么所有的这些类产生的对象在使用时,从用法上来说都一样。
归一化,让使用者无需关心对象的类是什么,只需要的知道这些对象都具备某些功能就可以了,这极大地降低了使用者的使用难度。
比如:我们定义一个动物接口,接口里定义了有跑、吃、呼吸等接口函数,这样老鼠的类去实现了该接口,松鼠的类也去实现了该接口,由二者分别产生一只老鼠和一只松鼠送到你面前,即便是你分别不到底哪只是什么鼠你肯定知道他俩都会跑,都会吃,都能呼吸。
再比如:我们有一个汽车接口,里面定义了汽车所有的功能,然后由本田汽车的类,奥迪汽车的类,大众汽车的类,他们都实现了汽车接口,这样就好办了,大家只需要学会了怎么开汽车,那么无论是本田,还是奥迪,还是大众我们都会开了,开的时候根本无需关心我开的是哪一类车,操作手法(函数调用)都一样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号