用Java来测试Avro数据格式在Kafka的传输,及测试Avro Schema的兼容性
为了测试Avro Schema的兼容性,新建2个Java project,其中v1代表的是第一个版本, v2代表的是第二个版本。
2个project结构如下

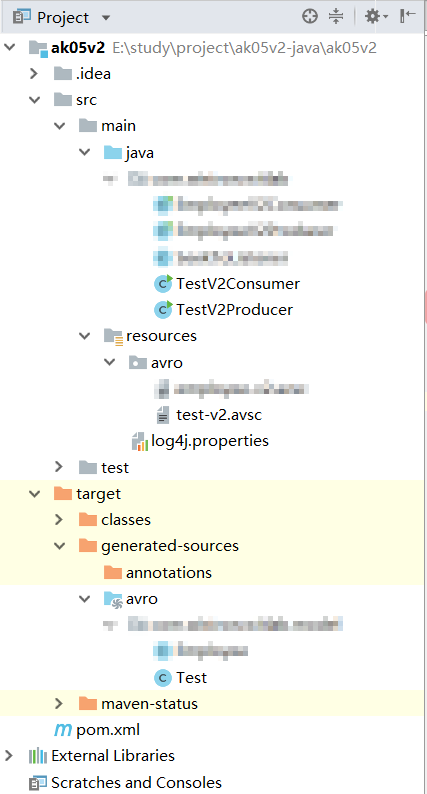
v1的主要代码:
pom.xml


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.test</groupId> <artifactId>ak05v1</artifactId> <version>1.0-SNAPSHOT</version> <properties> <avro.version>1.8.2</avro.version> <kafka.version>1.1.0</kafka.version> <confluent.version>5.3.0</confluent.version> </properties> <!--necessary to resolve confluent dependencies--> <repositories> <repository> <id>maven.repository</id> <url>https://maven.repository.redhat.com/earlyaccess/all/</url> </repository> </repositories> <dependencies> <!--我們需要引入avro的函式庫--> <!-- https://mvnrepository.com/artifact/org.apache.avro/avro --> <dependency> <groupId>org.apache.avro</groupId> <artifactId>avro</artifactId> <version>${avro.version}</version> </dependency> <!--dependencies needed for the kafka part--> <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>${kafka.version}</version> </dependency> <dependency> <groupId>io.confluent</groupId> <artifactId>kafka-avro-serializer</artifactId> <version>${confluent.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.25</version> </dependency> <!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.25</version> </dependency> </dependencies> <build> <plugins> <!--這個plugin會強制使用JDK8來compile程式--> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <!--這個plugin會根據avro裡頭的設定來產生java類別--> <plugin> <groupId>org.apache.avro</groupId> <artifactId>avro-maven-plugin</artifactId> <version>${avro.version}</version> <executions> <execution> <phase>generate-sources</phase> <goals> <goal>schema</goal> <goal>protocol</goal> <goal>idl-protocol</goal> </goals> <configuration> <sourceDirectory>${project.basedir}/src/main/resources/avro</sourceDirectory> <stringType>String</stringType> <createSetters>false</createSetters> <enableDecimalLogicalType>true</enableDecimalLogicalType> <fieldVisibility>private</fieldVisibility> </configuration> </execution> </executions> </plugin> <!--這個plugin會告訴IntelliJ去找尋根據avro設定所產生的java類別的源碼--> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>build-helper-maven-plugin</artifactId> <version>3.0.0</version> <executions> <execution> <id>add-source</id> <phase>generate-sources</phase> <goals> <goal>add-source</goal> </goals> <configuration> <sources> <source>target/generated-sources/avro</source> </sources> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
test.avsc
{
"type": "record",
"namespace": "com.model",
"name": "Test",
"fields": [
{ "name": "a", "type": "string"},
{ "name": "b", "type": "string", "default":"v1"},
{ "name": "c", "type": "string", "default":"v1"}
]
}
TestV1Producer.java
package com.test; import com.model.Test; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Properties; import java.util.concurrent.ExecutionException; /** * 示範如何使用SchemaRegistry與KafkaAvroSerializer來傳送資料進Kafka */ public class TestV1Producer { private static String KAFKA_BROKER_URL = "localhost:9092"; // Kafka集群在那裡? //private static String SCHEMA_REGISTRY_URL = "http://10.37.35.115:9086"; // SchemaRegistry的服務在那裡? private static String SCHEMA_REGISTRY_URL = "https://cp1.demo.playground.landoop.com/api/schema-registry"; public static void main(String[] args) throws ExecutionException, InterruptedException { // 步驟1. 設定要連線到Kafka集群的相關設定 Properties props = new Properties(); props.put("bootstrap.servers", KAFKA_BROKER_URL); // Kafka集群在那裡? props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定msgKey的序列化器 props.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer"); // <-- 指定msgValue的序列化器 //props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("schema.registry.url", SCHEMA_REGISTRY_URL);// SchemaRegistry的服務在那裡? props.put("acks","all"); props.put("max.in.flight.requests.per.connection","1"); props.put("retries",Integer.MAX_VALUE+""); // 步驟2. 產生一個Kafka的Producer的實例 <-- 注意 Producer<String, Test> producer = new KafkaProducer<>(props); // msgKey是string, msgValue是Employee // 步驟3. 指定想要發佈訊息的topic名稱 String topicName = "ak05.test002"; try { // 步驟4. 直接使用Maven從scheam產生出來的物件來做為資料的容器 // 送進第1個員工(schema v1) Test test = Test.newBuilder() .setA("001") .setB("Jack") .setC("Ma") .build(); RecordMetadata metaData = producer.send(new ProducerRecord<String, Test>(topicName, test.getA(), test)).get(); // msgKey是string, msgValue是Employee System.out.println(metaData.offset() + " --> " + test); // 送進第2個員工(schema v1) test = Test.newBuilder() .setA("002") .setB("Pony") .setC("Ma") .build(); metaData = producer.send(new ProducerRecord<String, Test>(topicName, test.getA(), test)).get(); // msgKey是string, msgValue是Employee System.out.println(metaData.offset() + " --> " + test); // 送進第3個員工(schema v1) test = Test.newBuilder() .setA("003") .setB("Robin") .setC("Li") .build(); metaData = producer.send(new ProducerRecord<String, Test>(topicName, test.getA(), test)).get(); // msgKey是string, msgValue是Employee System.out.println(metaData.offset() + " --> " + test); } catch(Exception e) { e.printStackTrace(); } finally { producer.flush(); producer.close(); } } }
TestV1Consumer.java
package com.test; import com.model.Test; import org.apache.kafka.clients.consumer.Consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.record.TimestampType; import java.util.Arrays; import java.util.Properties; /** * 示範如何使用SchemaRegistry與KafkaAvroDeserializer來從Kafka裡讀取資料 */ public class TestV1Consumer { private static String KAFKA_BROKER_URL = "localhost:9092"; // Kafka集群在那裡? private static String SCHEMA_REGISTRY_URL = "http://10.37.35.115:9086"; // SchemaRegistry的服務在那裡? public static void main(String[] args) { // 步驟1. 設定要連線到Kafka集群的相關設定 Properties props = new Properties(); props.put("bootstrap.servers", KAFKA_BROKER_URL); // Kafka集群在那裡? props.put("group.id", "ak05-v1"); // <-- 這就是ConsumerGroup props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 指定msgKey的反序列化器 props.put("value.deserializer", "io.confluent.kafka.serializers.KafkaAvroDeserializer"); // 指定msgValue的反序列化器 props.put("schema.registry.url", SCHEMA_REGISTRY_URL); // <-- SchemaRegistry的服務在那裡? props.put("specific.avro.reader", "true"); // <-- 告訴KafkaAvroDeserializer來反序列成Avro產生的specific物件類別 // (如果沒有設定, 則都會以GenericRecord方法反序列) props.put("auto.offset.reset", "earliest"); // 是否從這個ConsumerGroup尚未讀取的partition/offset開始讀 props.put("enable.auto.commit", "false"); // 步驟2. 產生一個Kafka的Consumer的實例 Consumer<String, Test> consumer = new KafkaConsumer<>(props); // msgKey是string, msgValue是Test // 步驟3. 指定想要訂閱訊息的topic名稱 String topicName = "ak05.test002"; // 步驟4. 讓Consumer向Kafka集群訂閱指定的topic (每次重起的時候使用seekToListener來移動ConsumerGroup的offset到topic的最前面) consumer.subscribe(Arrays.asList(topicName), new SeekToListener(consumer)); // 步驟5. 持續的拉取Kafka有進來的訊息 try { System.out.println("Start listen incoming messages ..."); while (true) { // 請求Kafka把新的訊息吐出來 ConsumerRecords<String, Test> records = consumer.poll(1000); // 如果有任何新的訊息就會進到下面的迭代 for (ConsumerRecord<String, Test> record : records){ // ** 在這裡進行商業邏輯與訊息處理 ** // 取出相關的metadata String topic = record.topic(); int partition = record.partition(); long offset = record.offset(); TimestampType timestampType = record.timestampType(); long timestamp = record.timestamp(); // 取出msgKey與msgValue String msgKey = record.key(); Test msgValue = record.value(); //<-- 注意 // 秀出metadata與msgKey & msgValue訊息 System.out.println(topic + "-" + partition + "-" + offset + " : (" + record.key() + ", " + msgValue + ")"); } consumer.commitAsync(); } } finally { // 步驟6. 如果收到結束程式的訊號時關掉Consumer實例的連線 consumer.close(); System.out.println("Stop listen incoming messages"); } } }
v2的主要代码:
pom.xml与v1一致
test-v2.avsc
{ "type": "record", "namespace": "com.wistron.witlab.model", "name": "Test", "fields": [ { "name": "a", "type": "string"}, { "name": "c", "type": "string", "default": "v2"}, { "name": "d", "type": "string", "default": "v2"}, { "name": "e", "type": "string", "default": "v2"} ] }
TestV2Producer.java
package com.test; import com.model.Test; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Properties; import java.util.concurrent.ExecutionException; /** * 示範如何使用SchemaRegistry與KafkaAvroSerializer來傳送資料進Kafka */ public class TestV2Producer { private static String KAFKA_BROKER_URL = "localhost:9092"; // Kafka集群在那裡? //private static String SCHEMA_REGISTRY_URL = "http://10.37.35.115:9086"; // SchemaRegistry的服務在那裡? private static String SCHEMA_REGISTRY_URL = "https://cp1.demo.playground.landoop.com/api/schema-registry"; public static void main(String[] args) throws ExecutionException, InterruptedException { // 步驟1. 設定要連線到Kafka集群的相關設定 Properties props = new Properties(); props.put("bootstrap.servers", KAFKA_BROKER_URL); // Kafka集群在那裡? props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定msgKey的序列化器 props.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer"); // <-- 指定msgValue的序列化器 //props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("schema.registry.url", SCHEMA_REGISTRY_URL);// SchemaRegistry的服務在那裡? props.put("acks","all"); props.put("max.in.flight.requests.per.connection","1"); props.put("retries",Integer.MAX_VALUE+""); // 步驟2. 產生一個Kafka的Producer的實例 <-- 注意 Producer<String, Test> producer = new KafkaProducer<>(props); // msgKey是string, msgValue是Employee // 步驟3. 指定想要發佈訊息的topic名稱 String topicName = "ak05.test002"; try { // 步驟4. 直接使用Maven從scheam產生出來的物件來做為資料的容器 // 送進第1個員工(schema v1) Test test = Test.newBuilder() .setA("a1") .setC("c1") .setD("d1") .setE("e1") .build(); RecordMetadata metaData = producer.send(new ProducerRecord<String, Test>(topicName, test.getA(), test)).get(); // msgKey是string, msgValue是Employee System.out.println(metaData.offset() + " --> " + test); // 送進第2個員工(schema v1) test = Test.newBuilder() .setA("a2") .setC("c2") .setD("d2") .setE("e2") .build(); metaData = producer.send(new ProducerRecord<String, Test>(topicName, test.getA(), test)).get(); // msgKey是string, msgValue是Employee System.out.println(metaData.offset() + " --> " + test); // 送進第3個員工(schema v1) test = Test.newBuilder() .setA("a3") .setC("c3") .setD("d3") .setE("e3") .build(); metaData = producer.send(new ProducerRecord<String, Test>(topicName, test.getA(), test)).get(); // msgKey是string, msgValue是Employee System.out.println(metaData.offset() + " --> " + test); } catch(Exception e) { e.printStackTrace(); } finally { producer.flush(); producer.close(); } } }
TestV2Consumer.java
package com.test; import com.model.Test; import org.apache.kafka.clients.consumer.Consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.record.TimestampType; import java.util.Arrays; import java.util.Properties; /** * 示範如何使用SchemaRegistry與KafkaAvroDeserializer來從Kafka裡讀取資料 */ public class TestV2Consumer { private static String KAFKA_BROKER_URL = "localhost:9092"; // Kafka集群在那裡? private static String SCHEMA_REGISTRY_URL = "http://10.37.35.115:9086"; // SchemaRegistry的服務在那裡? public static void main(String[] args) { // 步驟1. 設定要連線到Kafka集群的相關設定 Properties props = new Properties(); props.put("bootstrap.servers", KAFKA_BROKER_URL); // Kafka集群在那裡? props.put("group.id", "ak05-v2"); // <-- 這就是ConsumerGroup props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 指定msgKey的反序列化器 props.put("value.deserializer", "io.confluent.kafka.serializers.KafkaAvroDeserializer"); // 指定msgValue的反序列化器 props.put("schema.registry.url", SCHEMA_REGISTRY_URL); // <-- SchemaRegistry的服務在那裡? props.put("specific.avro.reader", "true"); // <-- 告訴KafkaAvroDeserializer來反序列成Avro產生的specific物件類別 // (如果沒有設定, 則都會以GenericRecord方法反序列) props.put("auto.offset.reset", "earliest"); // 是否從這個ConsumerGroup尚未讀取的partition/offset開始讀 props.put("enable.auto.commit", "false"); // 步驟2. 產生一個Kafka的Consumer的實例 Consumer<String, Test> consumer = new KafkaConsumer<>(props); // msgKey是string, msgValue是Test // 步驟3. 指定想要訂閱訊息的topic名稱 String topicName = "ak05.test002"; // 步驟4. 讓Consumer向Kafka集群訂閱指定的topic (每次重起的時候使用seekToListener來移動ConsumerGroup的offset到topic的最前面) consumer.subscribe(Arrays.asList(topicName), new SeekToListener(consumer)); // 步驟5. 持續的拉取Kafka有進來的訊息 try { System.out.println("Start listen incoming messages ..."); while (true) { // 請求Kafka把新的訊息吐出來 ConsumerRecords<String, Test> records = consumer.poll(1000); // 如果有任何新的訊息就會進到下面的迭代 for (ConsumerRecord<String, Test> record : records){ // ** 在這裡進行商業邏輯與訊息處理 ** // 取出相關的metadata String topic = record.topic(); int partition = record.partition(); long offset = record.offset(); TimestampType timestampType = record.timestampType(); long timestamp = record.timestamp(); // 取出msgKey與msgValue String msgKey = record.key(); Test msgValue = record.value(); //<-- 注意 // 秀出metadata與msgKey & msgValue訊息 System.out.println(topic + "-" + partition + "-" + offset + " : (" + record.key() + ", " + msgValue + ")"); } consumer.commitAsync(); } } finally { // 步驟6. 如果收到結束程式的訊號時關掉Consumer實例的連線 consumer.close(); System.out.println("Stop listen incoming messages"); } } }
测试步骤:
- Run producer-v1,去schema registry UI看schema版本
- Run producer-v2,去schema registry UI看schema版本
- Run consumer-v1,旧schema读新数据,演示forward
- Run consumer-v2,新schema读旧数据,演示backward
1.
Run TestV1Producer,发送成功
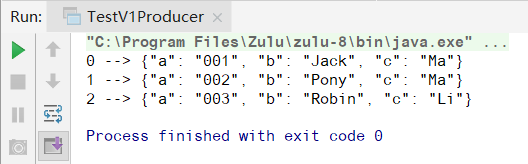
去schema registry UI查看schema信息,此时schema版本是v.1

2.
Run TestV2Producer,发送成功

去schema registry UI查看schema信息,此时schema版本是v.2

3.
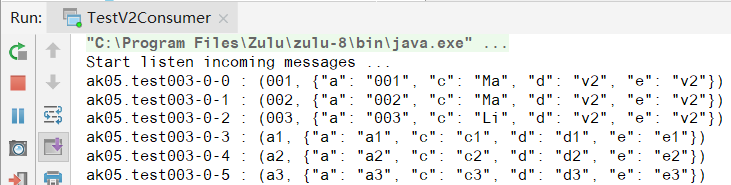
Run TestV1Consumer,用旧schema去读新数据,测试forward(向前兼容),可以看到,新旧资料都读取了

4.
Run TestV2Consumer,用新schema去读旧数据,测试backward(向后兼容)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号