Mac上tesseract-OCR的安装配置
Mac上tesseract-OCR的安装配置
tesseract简介
OCR(Optical Character Recognition)即光学字符识别技术,专门用于对图片文字进行识别,并获取文本。
tesseract-ocr引擎先由HP实验室研发,后来成为一个开源项目,主要由google进行改进优化。
安装步骤
安装homebrew
Homebrew是MacOS上的包管理器,类似于ubuntu中的apt-get,centos中的yum,Homebrew安装很简单
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
安装完毕后可以用brew -v测试
Homebrew 1.3.1
Homebrew/homebrew-core (git revision 0290; last commit 2017-08-23)
安装tesseract
brew install --with-training-tools tesseract #同时安装附加组件,后面自定义字库会用到
安装完毕后用tesseract -v测试
tesseract 3.05.01
leptonica-1.74.4
libjpeg 9b : libpng 1.6.31 : libtiff 4.0.8 : zlib 1.2.8
基本用法
tesseract test.png output #识别test.png的图片,把结果放到output.txt中
test.png
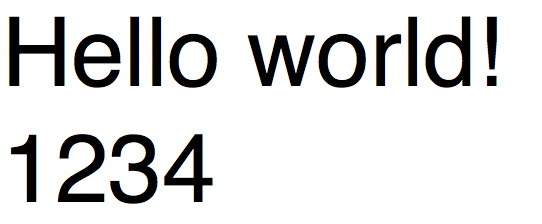
output.txt自动生成

更多可选参数的用法可以通过tesseract -h查询
python接口
python有着更加优雅的方式调用系统的tesseract工具,首先安装pytesseract模块
sudo pip install pytesseract
pytesseract是对tesseract的封装,要和PIL联合使用,基本用法如下:
import pytesseract
from PIL import Image
img = Image.open('./test.png') #先创建image对象
text = pytesseract.image_to_string(img) #直接转化成string,更多参数可以查看文档
repr(text) #"u'Hello world!\\n1234'"
结束语
默认的tesseract-ocr工具识别能力有限,很多地方需要个性化定制(如中文),博主也还在学习过程中,以后再会有进一步说明,欢迎大家学习交流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号