k8s service(kube-proxy)
kube-proxy和service
kube-proxy 是k8s中的组件之一,是以Pod 形式真实运行的进程,而service 是它的代理功能的具体实现,service 是k8s 中一种资源类型,里面定义的是集群Pod 的访问转发规则。
存在的意义
service 作用
服务发现(防止pod 失联)
负载均衡(轮询转发请求到后端集群中的pod)
service与Pod 关联
两种方式
1、service 通过标签选择器selector 关联pod 的标签,找到pod 。
2、service 通过关联deployment 等资源,通过deployment 等资源间接关联pod。注意写yaml文件创建service 关联deployment 通过标签选择器配置成 selector: app: pay 形式关联的是pod 的标签不是 deployment 的标签,可以通过expose命令关联dep资源创建service。
service 的三种形式
ClusterIP
集群IP,仅供k8s内部访问(只能在pod 或node 上访问,无法外部访问),相当于service 加了1个vip,通过vip 提供访问地址,再转发给各个Pod
NodePort
在每个node 节点为相应Pod启动一个对外端口(默认30000起步),映射pod 内部端口。通过任意一个Pod 所在的节点ip+port 就能访问pod ,多个pod 需要在service 前面加一个LB(lvs/proxy)把每个节点的ip+port 加入,才能实现负载均衡,这样每个服务都得添加一次,增加了管理维护成本。
Loadblance
云服务厂商提供的,自动添加service 映射对外端口到负载上面,例如阿里云可以通过SLB为service 提供负载均衡。只有云服务厂商的k8s 才有此形式。
相关操作
service 的创建
方式一 expose


kubectl expose --help kubectl expose deployment nginx-dep1 --port=2022 --target-port=80 --type=NodePort -n kzf service代理资源类型 资源名称 代理对外端口 pod 中内部端口 端口暴露类型(默认ClusterIp) 命名空间
方式二 创建yaml
apiVersion: v1 kind: Service metadata: name: service-kzf1 namespace: asdf spec: clusterIP: NodePort #不写默认类型为Clusterip ports: - port: 2021 #clusterip 集群端口 targetPort: 80 #pod 内部端口 selector: app: nginx-label #通过标签选择pod
service 查看
kubectl get svc -n kzf NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx-dep1 NodePort xxx.xx.x.x <none> 2022:31992/TCP 27m service-kzf NodePort xxx.xx.x.x <none> 2020:32341/TCP 2d1h service-kzf1 ClusterIP xxx.xx.x.x <none> 2021/TCP 52m nginx-ingress LoadBalancer xxx.xx.x.x xx.xx.xxx.xx 80:3xxxx/TCP,443:xxxx6/TCP 29d 注解: type 分为三种类型NodePort/ClusterIP/LoadBalancer CLUSTER-IP 无论哪种类型都有clusterip 因为Node port 和loadbalancer 都是在它的基础上拓展的 EXTERNAL-IP 只有LoadBalancer 有,这是个负载均衡器的对外IP Port service 集群CLUSTER-IP IP 的端口:nodeport 类型节点上的端口 age 创建时间多久
服务发现
当service 创建完成后pod 客户端怎么发现它的连接地址和端口呢,有以下方式
通过环境变量发现服务
kubectl exec kubia-2isdly env
通过DNS发现服务
在kube-system 命名空间有个dns 的pod 负载dns服务。在集群中的其他 pod 都被配置成使用其作为 dns ( Kubemetes 通过修改每 容器的/ etc/reso conf 实现)。
Tip:
service 集群 IP个虚拟 IP ,ping 的时候无法ping通,只有在与服务端口结合时才有意义。
连接集群外部的服务
介绍服务 endpoint
手动配置服务的 endpoint
apiVersion: vl kind: Service metadata: name: external-service spec: ports: - port:80
为没有选择器的service创建endpoints。Endpoint是一个单独的资源并不是service的一个属性。由于创建的资源中并不包含选择器,相关的Endpoints资源并没有自动创建,所以必须手动创建。如下所示
apiVersion: vl kind: Endpoints metadata: name: external-service # Endpoint的名称必须和服务的名称相匹配 subsets: - addresses: - ip: 11.11.11.11 - ip: 22.22.22.22 ports: - port: 80
为外部服务创建别名
apiVersion: vl kind: Service metadata: name: external-service spec: type: ExternalName externalName: someapi.asdf.com ports: - port: 80
将服务暴漏给内部客户端
ClusterIp 类型即可,Clusterip 就是一个虚拟vip ,代理后端的一组pod,只能在集群内部访问(pod 里面访问/集群节点访问)
将服务暴露给外部客户端
方式一:NodePort
$ kubectl get svc kubia-nodeport NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubia-nodeport 10.111.254.223 <nodes> 80:30123/TCP 2m EXTERNAL-IP列。 它显示nodes 表明服务可通过任何集群节点的IP地址访问。 PORT(S)列显示集群IP (8 0) 的内部端口和节点端口(30123), 可 以通过以下地址访问该服务: • 10.11.254.223:80 • <ls七node'sIP>:30123 • <2ndnode'sIP>:30123, 等等

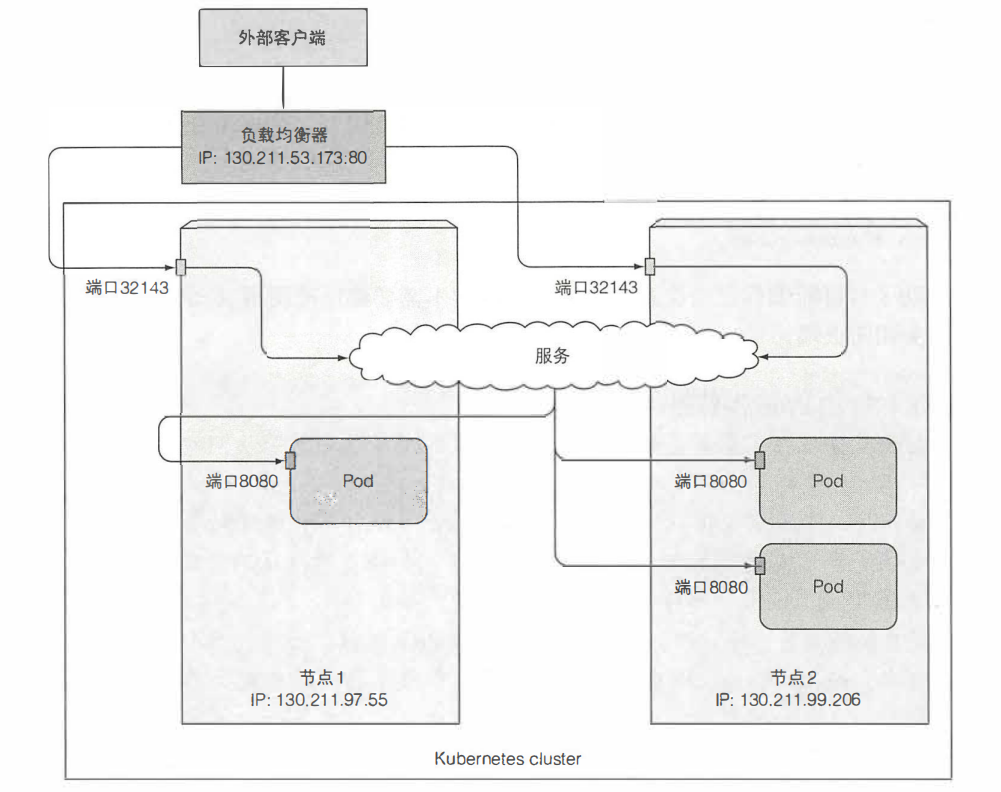
方式二:LoadBalance
kubect1 get svc kubia-loadbalancer NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubia-loadbalancer 10.111.241.153 130.211.53.173 80:32143/TCP lm 在这种情况下, 负载均衡器的IP地址为130.211.53.173, 因此现在可以通过该 IP 地址访问该服务: $ curl h七七p://130.211.53.173
访问流程图
方式三:Ingress
使用 headless服务来发现独立的pod
创建headless服务
apiVersion: vl kind: Service metadata: name: kubia-headless spec: clusterIP: None #这使得服务成为headless
ports: - port: 80 targetPort: 8080 selector: app: kubia
service 与就绪探针
service 负载功能实现原理
service 负载均衡实现主要有两种方式
iptables(早期)
iptables 是一个工具它通过linux 的netfilter 来进行ip 包的过滤处理。主要通过维护一张规则表,从上到下匹配表中规则,每次变动都不是增量而是全表变动。随着表的增大效率降低。
ipvs(k8s version:1.11以后)
ipvs实际上就是lvs 的原理。采用它的轮询策略(w,rr/wrr.lc,wlc),内核级别的,效率高。
