
python 入门总结(一)
自然语言用双引号,机器语言用单引号 例如dict的key
单行注释 #
多行注释 ''' '''
输入print
%s 字符串的占位符
%d 数字的占位符
如语句中有占位符那么所有的%都是占位符,可以用%%转义
n**m n的m次幂
逻辑运算符
-
and并且 -
or或者 -
not非的意思 -
运算顺序
-
and or not同时存在 先算括号然后算not然后算and最后算or -
x or y如果x0,那么就是y,否则就是x,记住and跟or相反,如果x0,那么就是x,否则就是y
-
bit_length() 二进制的长度
bool() 强制转化为boolean类型
空的东西都是Flase,非空的东西都是true
切片可以对字符串进行截取
- 语法
s[起始位置:结束位置]包左不包右 - 语法
s[其实位置:结束位置:步长]步长是没几个取一个,就是取后一个
字符串是不可变的对象,所以任何操作对原字符串本身是不会发生改变的
字符串操作
capitalize 首字母大写
lower 全部转换成小写
upper 全部装换成大写
swapcase 大小写互相交互位置
title() 单词的首字母大写
strip 去掉空格
lstrip 去掉左边空格
rstrip 去掉右边空格
split 切割
format 指定位置的索引 {}
startswith 判断字符串是不是某某开头
endswith 判断字符串是不是某某结尾
count(a) 查找"a"出现的次数
find("aa") 查找"aa"出现的位置,如果没有返回-1
isalnum 判断是否有字母和数字组成
isalpha 判断是否由字母组成
isdigit 判断是否有数字组成
isnumeric 判断数字(中文)
len() 内置函数.直接使用.不用点操作.判断字符串的长度
for 变量 in 可迭代对象 循环遍历
元组不可变,只读 ("a",) tuple 元组中的元素之时不允许删除但是我们可以删除整个元祖
- 元祖的不可变的意思是子元素是不可变,而子元素内部的子元素是可以变,这取决于子元素是否是可变对象
range(开始,结束,步长) 数字
insert 索引添加
lst.insert(1,"刘德华")
extend 迭代添加(用新列表扩展原来的列表)
lst.extend(["马化腾","小泽"])
字典 dict
字典的key必须是可哈希的,不可变,value没有限制
不是按照我们保存的顺序保存的,无序的
增
setdefault()如果字典中已经包含了这个key,不在继续保存- 如果key重复了,会替换原来的value
dict.update(dict2)- 把字典参数dict2的key/value对更新到字典dict里,如果键值有重复,更新替换
删除
pop()删除一个元素返回valuepopitem()随机删除clear()清空
查询
div[key]如果key不存在就会报错- get("aa","bb") 可以通过key来获取value的值,如果key不存在,返回None,可以给出一个默认值,当key不存在的时候返回默认值
keys 返回所有的key,虽然不是列表,但是可以迭代循环
values 返回所有的value
items 拿到所有的键值对
enumerate 枚举
is
比较内存地址是否相等
小数据池:字符串 数字
字符串
- 不能有特殊字符
- s * 20还是同一个地址,s * 21以后就是两个地址
数字的范围: -5-- 256
编码
各个编码之间的二进制,是不能相互识别的,会产生乱码
文件的存储,传输,不能是unicode(只能是utf-8 utf-16 gbk )
str 在内存中是用unicode编码
bytes 类型
s=b'alex'
encode 编码,如何将str-> bytes
decode 解码
fromkeys
- dic.fromkeys(keys,value) 返回的是一个字典 ,将keys的所有元素分别打印,对应的是value
join() 把列表变成字符串
列表不能再循环的时候删除,因为索引会跟着改变
# # 冒泡排序
# # lst=[86,3,5,7,23,53,13]
# # for i in range(len(lst)): # 记录内部排序的次数
# # i=0
# # while i<len(lst)-1:
# # if lst[i]>lst[i+1]:
# # lst[i],lst[i+1]=lst[i+1],lst[i]
# # i=i+1
文件操作
r,rb只读(字节b)
w,wb 只写
a,ab 追加
r+ 读写
在r+模式下,如果读写了内容,不论读取内容多少,光标显示的是多少,在写入或者操作文件的时候都是在结尾进行的操作
read
w+ 写读
a+ 写读(追加写读)
seek(n) 光标移动的位置
seek(0)开头seek(0,)第二个参数 0:在开头,1:在当前,2:末尾
write 在没有任何操作之前进行写,在开头写,如果读取过后就在末尾写
tell()
移动到当前位置
文件修改
-
创建新文件,把修改后的内容写入新文件,删除老文件,重命名新文件
-
rename改名字 -
import os
flush() 刷新缓冲区
def 函数名
三元运算符
a if a>b else b
*food 可以传入任意的位置参数,动态参数必须在位置参数后面,收到的内容是元组tuple
** 来接收动态关键字参数
关键字参数必须在位置参数后面,否则参数会混乱
顺序:
位置参数>*args>默认值参数>**kwargs
globals 全局作用域
不再使用局部作用域中的内容而改成全局作用域中的变量
nonlocal表示在局部作用中,调用父级使用空间中的变量(父级使用内部变量)
locals() 局部作用域
sum() 求和
def extendList(val,list=[]):
list.append(val)
return list
list1=extendList(10)
print("list1=%s"% list1)
# list=[10]
list2=extendList(123,[])
print("list=%s" % list2)
# list=[123]
list3=extendList("a")
print("list3=%s"% list3)
# list=[10,"a"]
key没有改变所有指向同一个对象
闭包
闭包就是内层函数,对外层函数(非全部)的变量的引用
_closure_ 检测函数是否是闭包,使用函数名._closure_ 返回cell就是闭包,返回None就不是闭包
__iter__() 获取迭代器
__next__() 迭代对象
yield 返回结果 可以让函数分段执行
send(值) 让生成器向下执行一次,给上一个yield传一个值(第一个和最后一个是不用传的)
列表推导式
[最终的结果(变量) for 变量 in 可迭代对象 if 筛选的条件]
lst=[ i for i in range(1,15)]
生成器表达式
g=(i for i in range(10))
print(list(g))
不同点,一个是[] 一个是(),一个是一次性给你好内存,一个是一个一个给你
得到的值不一样,列表推导式得到的值一个生成器
生成器要值的时候才去取
字典推导式
dic={lst[i]:lst2[i] for i in range(len(lst))}
集合推导式
lst=["那化腾","马化腾","王建中","张建忠","张雪峰","张雪峰","张雪峰"]
s={i for i in lst}
print(s)
去重
没有元组推到式,不过可以认为是生成器表达式
字典是key:value 集合是key
内置函数
iter() 迭代
next() 输出下一个
print("aa","bb","cc") sep:分隔符 end最后
hash算法 目的是唯一,列表是不可哈希的,元组可以
callable() 是否是可以调用的
字符串的执行
eval执行简单的运算exec执行字符串函数
divmod 求商和余数
round 五舍六入
pow(a,b) a的b次幂
sum() 求和
max() 最大值
min() 最小值
reversed 倒序 list()
slice()
s=slice(1,3,1)
print(lst[s])
repr 原样输出,过滤掉转义字符\n\t\r不管百分号
ord 返回编码表中的码位
chr 已知码位计算字符
format
enumerate() 把索引和元素一起获取,索引默认从0开始
lst=["A","B","c","d"]
for index,el in enumerate(lst,100):
print(index)
print(el)
all() 全部是True返回True(可迭代对象)
any() 有一个是True则是True(可迭代对象)
lembda() 匿名函数
a=lambda x:x*x 语法:lambda 参数:返回值
__name__ 查看函数名
sorted 要给一个对象接受,reverseed 参数为True False 升序降序
lst=[
{"id":1,"name":"alex","age":18},
{"id":2,"name":"taibai","age":19},
{"id":3,"name":"wusir","age":13},
{"id":4,"name":"ritian","age":11},
{"id":5,"name":"nvshen","age":12},
]
def func(dic):
return dic["age"]
l1=sorted(lst,key=func)
print(l1)
filter 第一个参数是函数,第二个参数是可迭代的对象
lst=[1,3,4,5,6,7,8]
li=filter(lambda i:i%2==1,lst)
print(list(li))
list(filter(lambda dic:dic["age"]>40,lst))
map
lst=[1,2,3,4,5,6,7]
def func(i):
return i*i
li=map(func,lst)
print(list(li))
lst1=[1,3,5,6,7,8]
lst2=[2,43,4,5,6,8]
print(list(map(lambda x,y:x+y, lst1,lst2)))
#如果传入的多个参数,后面的列表要一一对应
递归
面向对象
Person.__dict__ 查询类中的所有内容(不能进行增删改操作)
函数.属性 对类中的单个的变量进行增删改查
-
类名+()产生一个实例(对象,对象空间)
-
自动执行类中的
__init__,将对象空间传给__init__的self 参数 -
给对象封装相应的属性
-
Person.money="货币" # 增 Person.animal="中等动物" # 改 del Person.mind #删除 print(Person.__dict__)
class Count:
count = 0
def __init__(self):
Count.count = self.count + 1
查看类被调用几次
通过类名可以更改我的类中的静态变量值
Count.count=6
Count.__dict__
但是通过对象,不能改变只能引用类中的静态变量
类的两个属性
静态属性就是直接在类中定义的变量
动态属性就是定义在类中的方法
组合(不太懂)
from math import pi
# 求圆和圆环的面积和周长
class Circle:
def __init__(self,r):
self.r=r
def aera(self):
return self.r**2*pi
def perimeter(self):
return self.r*2*pi
class Ring:
def __init__(self,r1,r2):
self.r1=Circle(r1)
self.r2=Circle(r2)
def area(self):
return self.r1.aera()-self.r2.aera()
def perimeter(self):
return self.r1.perimeter()+self.r2.perimeter()
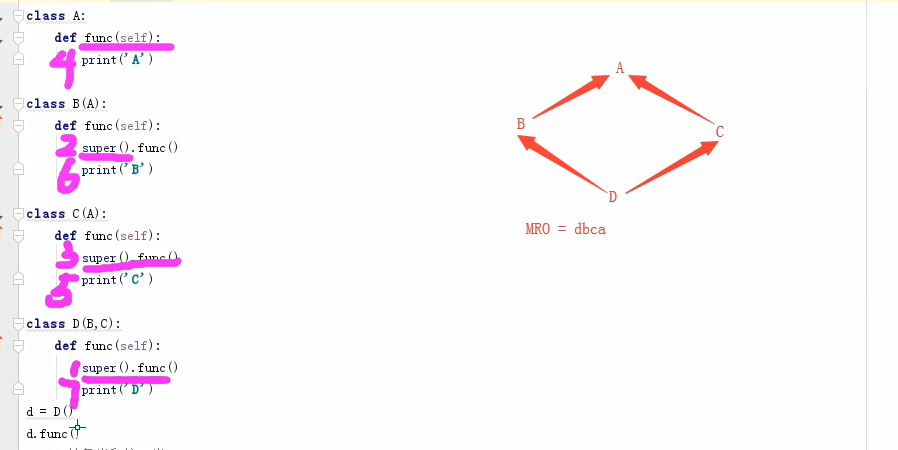
继承
只执行父类的方法:子类中不要定义与父类同名的方法
自执行子类的方法:在子类创建这个方法
既要执行子类的方法,又要执行父类的方法:
super().__init__(name,sex,age)
继承:单继承,多继承
类:经典类,新式类
新式类:凡是继承object都是新式类
python3x 所有的类都是新式类,因为python3x中的类默认继承object
经典类:不继承object都是经典类
python2x 所有的类默认都不继承object,所有类默认都是经典类,你可以让其继承新式类
单继承:新式类,经典类的查询顺序一样
多继承:
- 新式类:遵循广度优先 类名.mro()
- 经典类:遵循深度优先
- 多继承的新式类 广度优先:一条路走到倒数第二级,判断,如果其他路能走到终点,则返回走别一条路,如果不能,则走到终点
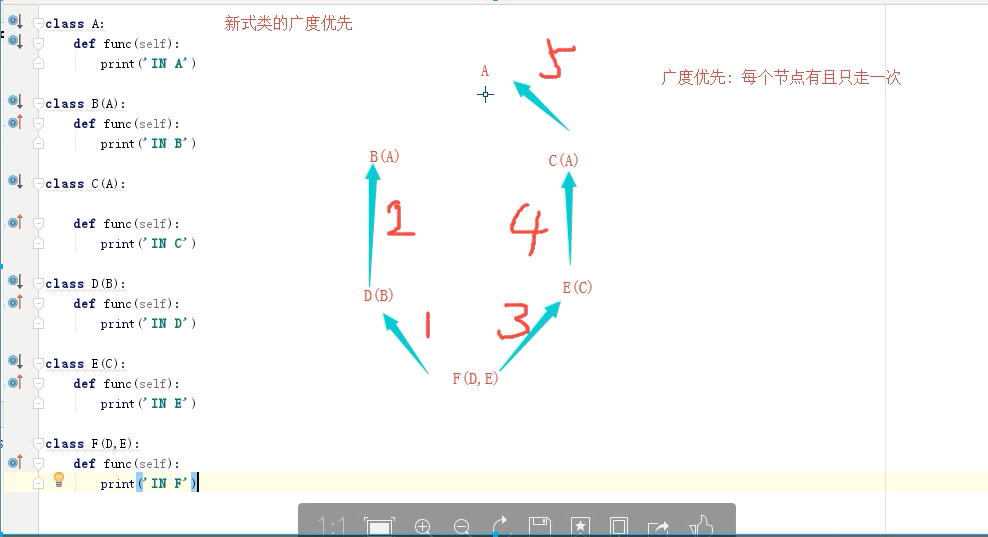
- 多继承的经典类:一条路走到黑
- 深度优先,广度优先:只能是继承两个类的情况
继承的优点:
- 节约代码
- 规范代码
统一化接口设计
-
# class Alipay: # def __init__(self, money): # self.money = money # # def pay(self): # print("使用京东支付了%s" % self.money) # # # class Jdpay: # def __init__(self, money): # self.money = money # # def pay(self): # print("使用京东支付了%s" % self.money) def pay(obj): obj.pay() a1 = Alipay(200) j1 = Jdpay(100) pay(a1)
抽象类接口类
from abc import ABCMEta, abstractmethod
class Payment(metaclass=ABCMEta):# 抽象类(接口类)
@abstractmethod# 强制指定一个规范,凡事继承我的类中必须有pay方法,如果,如果没有就会报错
def pay(self):
pass
封装
广义的封装: 把方法和属性都封装在一个类里,定义一个规范来描述一类事物
狭义的封装: 私有化,只有在类的内部访问
__age 对于私有静态字段来说,只能在本类中,类的外部
python处处都是多态
- 一种类型的多种形态,多个子类去继承父类,那么每一个子类都是这个父类的一种形态
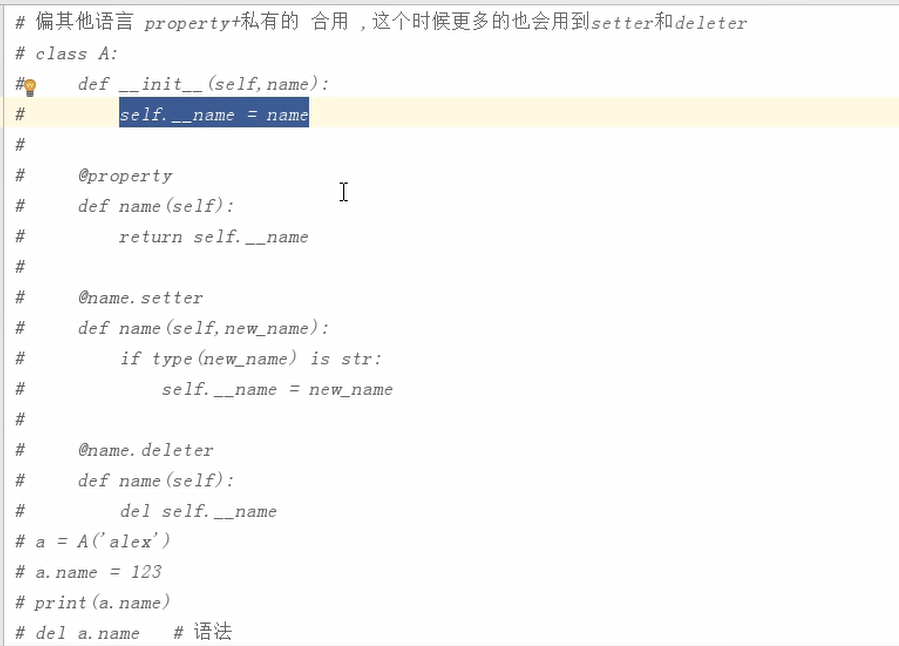
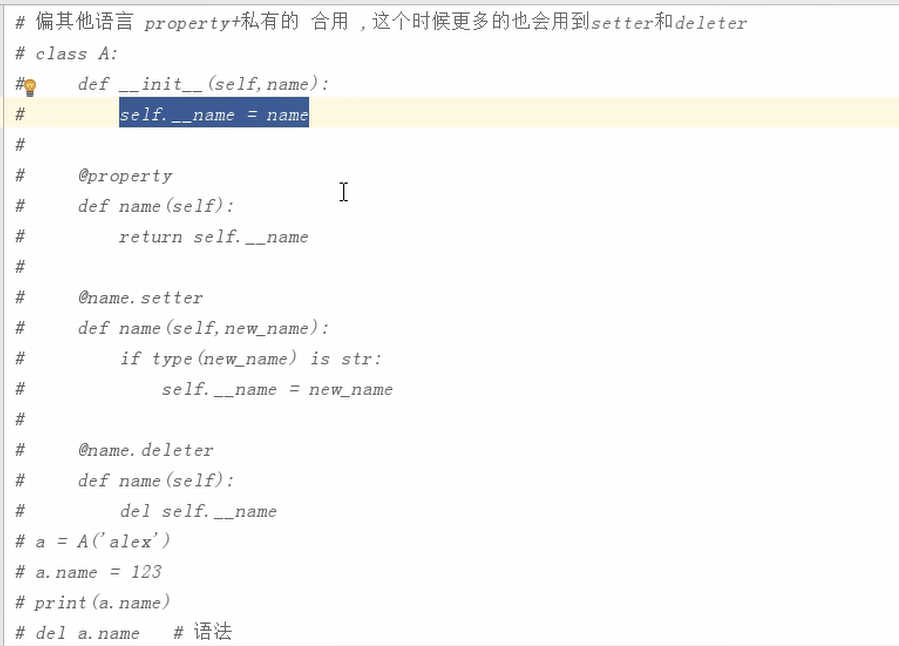
property 装饰器函数,内置函数,帮助你将类中的方法伪装成属性,特性
- 调用方法的时候不需要主动加括号
- 让程序的逻辑性更合理
@方法名.setter装饰器,修改被property装饰的属性的时候会调用被这个@方法名.deleter装饰器,修改被property装饰的属性的时候会调用被这个装饰器装饰的方法,除了self之外还有一个参数,被修改的值
静态方法
class A:
@staticmethod
def func():
print(666)
A.func()
类方法
# class A:
# name="alex"
# count=1
# @classmethod
# def func(cls): # 此方法无需对象参与
# print(cls)
# print(cls.age)
# def func2(self):
# print(self)
# class B(A):
# age=22
# def f1(self):
# pass
# # B.func()
# b1=B()
# b1.func2()
属性:将方法伪装成一个属性,代码上没有什么提升,只是更合理
@property
@属性名.setter
@属性.deleter
类方法
@classmethod
只能有类名调用(对象调用,传给cls参数也是该对象的所属类)
使用场景
1.无序对象参与
2.对类中的静态变量进行修改
3.在父类中类方法得到子类的类空间
静态方法
@staticmethod
代码性,清晰
复用性
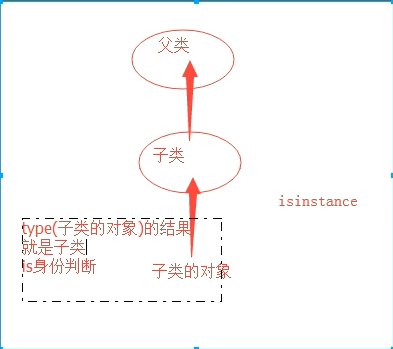
isinstance() 判断对象所属类型,包括继承关系
issubclass() 判断类与类之间的继承关系(前面父类,后面子类)
class A:pass
class B(A):pass
print(issubclass(B,A))# True
print(issubclass(A,B))#False
反射
反射: 用字符串数据类型的变量名来访问这个变量的值
class Student:
ROLE = 'STUDENT'
# eval 这个东西 明确的写在你的代码里
print(Student.ROLE)
# 'ROLE'
# eval()
print(getattr(Student,"ROLE"))

反射的方法:getatter hasattr setattr delattr
class Student:
ROLE = 'STUDENT'
@classmethod
def check_course(cls):
print('查看课程了')
@staticmethod
def login():
print("登录")
# 反射查看属性
print(Student.ROLE)
print(getattr(Student, "ROLE"))
print(Student.__dict__)
# 反射调用方法
# getattr(Student,'check_course')() #类方法
# getattr(Student,'login')() # 静态方法
num = input(">>>")
if hasattr(Student, num):
getattr(Student, num)()
setattr(a,'name','alex_SB') 对象,属性,替换的属性
单例(指向同一块内存空间)
- 如果一个类,从头到尾只有一个实例,说明从头到尾只开辟一块属于对象的空间,那么这个类就是一个单例类
__call__ 相当于对象()
Lisp语言???

a.func 就是在a对象中存储了类对象的指针(想当于记录了func地址的变量)
抽象类和接口类

classmethod 类方法的装饰器, 内置函数
staticmethod 静态方法的装饰器 内置函数
如果一个类里面的方法,既不需要用到self中的资源,也不用cls中的资源,想当于一个普通的函数
但是你由于某种原因,还要拿这个方法放在类中,这个时候,就将这个方法变成一个静态方法
某种原因:
- 你完全想用面向对象编程,所有的函数都必须写在类中
- 某个功能确确实实施这个类的方法,但是确确实实没有用过和这个类有关系的资源
列表中不要用pop(参数) insert() 特别消耗性能,但是可以用pop() append()
import sys
mymodule=sys.modules["__mian__"]
getattr(mymodule,"变量名")
__名字__不是被直接调用间接调用: 内置函数/面向对象中特殊语法/python提供的语法糖
__str__:str(obj) 要求必须实现__str__要求这个方法的返回值必须是字符串str类型
__call__: 对象() 用类写装饰器
__len__: 要求obj必须实现了__len__,要求这个方法的返回值必须是数字int类型
__new__: 在实例化的过程中,最先执行的方法,在执行init之前,用来创造一个对象,构造方法
__init__: 在实例化的过程中,在new执行之后,自动触发的一个初始化
__repr__是__str__的备胎,如果有__str__没有的话要向上找,只要父类不是object,就执行父类的__str__,但是如果出了object之外的父类都没有__str__方法,就执行子类的__repr__方法,如果子类也没有,还要向上继续找父类中的__repr__方法,一直到找不到,再执行object类中的__str__方法
hash

hash方法
底层数据结构基于hash值寻址的优化操作
hash是一个算法,能够把某一个要存在内存里的值通过一系列计算,保证不同值的hash结果是不一样的
对同一个值在多次执行python代码的时候hash值不一样
但是对同一个值,在同一次执行python代码的时候hash值永远不变
class Employee:
def __init__(self, name, age, sex, partment):
self.name = name
self.age = age
self.sex = sex
self.partment = partment
def __hash__(self):
return hash('%s%s' % (self.name, self.sex))
def __eq__(self, other):
if self.name == other.name and self.sex == other.sex:
return True
employ_lst = []
for i in range(200):
employ_lst.append(Employee('alex', i, 'male', 'python'))
for i in range(200):
employ_lst.append(Employee('wusir', i, 'male', 'python'))
for i in range(200):
employ_lst.append(Employee('taibai', i, 'male', 'python'))
employ_set = set(employ_lst)
for person in employ_set:
print(person.__dict__)
# set集合的去重机制: 先调用hash再调用eq,eq不是每次都触发,只有hash相等才触发
eq
- ==
- set的去重
模块
模块的分类
-
内置模块
安装python解释器的时候跟着装上那些方法
-
自定义模块
-
第三方模块/扩展模块
什么是模块
- 有的功能开发者自己无法完成,这样的话需要借助已经实现的函数\类来完成这些功能
- 你实现不了的功能都由别人替你实现
模块的名字
- 要遵循变量的命名规范
- 全部小写
模块的重命名
-
import my_module as m
导入多个模块
-
import os,my_module 但是PEP8的规范都应该分开写 import os import my_modules 所有的模块导入都应该尽量放在这个文件的开头 导入顺序 #先导入内置模块 #在导入第三方模块 # 最后倒入自定义模块
__del__ 方法
- 在清除一个对象在内存中使用的时候,会触发这个对象所在的类中的析构方法
item 系列
- 对象[] 就需要实现item系列
getitemsetitemdelitem
from my_module import login
- 在my_module文件中调用login变量
- 不导入并不意味着不存,而是没有建立文件到模块中其他名字的引用
- 当模块中导入的方法或者变量和本文件重名的时候,那么这个名字只代表最后一次对它复制的哪个方法或者变量
- 在本文件中对全部变量的修改完全不会影响到模块中的变量引用
import不会重复导入
from 模块 import *
- 导入模块中的所有变量和方法
__all__=[]控制* 导入的内容
在编写py文件的时候
- 所有不在函数和类中封装的内容都应该写在
if__name__ =__main__的下面(快捷键是main) 所有不需要调用就能执行的内容
在使用反射自己模块中的内容的时候
import sys
getattr(sys.modules[__name__],变量名)
模块的循环引用
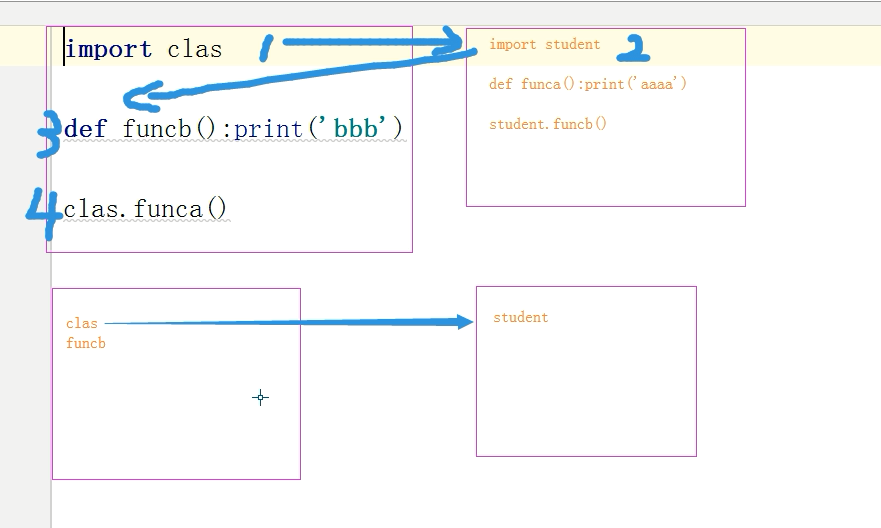
- 在模块的导入中 不要产生循环引用问题,如果发生循环导入了,就会发生明明写了但是找不到
包
直接导入模块
- from 包.包 import 模块
相对导入包
- 在
__init__导入包的时候,from . imort 包名点就是当前位置 - 使用相对导入只能被当作模块执行,不能被当做脚本执行
正则
<<正则指引>> 书
<<精通正则表达式>>
关于正则的学习都是试出来的,正则千千万,要想成为大神就嘚多练 网址
\s 包括回车\n 空格和制表符\t tab
\b 单词边界
a|b a或者b 如果a,b有重叠要把长的那个放前面,短的那个放后面(abc|ab)
. 除了换行符的所有字符
? 表示0或者1
贪婪匹配 内部用的是回溯算法(默认是贪婪模式)
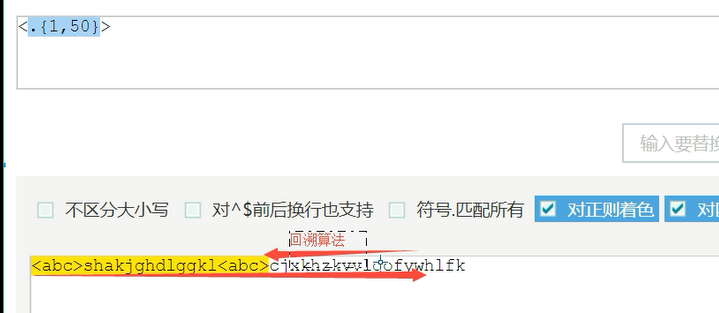
在量词的后面跟了一个? 取消贪婪匹配,就是非贪婪(惰性)匹配
.*?x 匹配任意字符知道找到一个x
.*x 匹配最后一个x
转义符 print(r'\n') 注意是在python 中
\( 匹配小括号
[-] 只有写在字符组的首位的时候才是减号
re模块
ret = re.findall('\d+', 'wjakfjkawf12344ajfajf12若2')
print(ret)
# 参数 返回值类型 :列表 返回值个数:1 返回值内容:所有匹配的内容
# 有值就是一个有值的列表,无值就是一个无值的列表
ret2 = re.search('\d+', 'fjakfwj12334afjkafj3423')
print(type(ret2))
# 返回值类型:正则匹配结果的对象; 返回值个数:如果匹配上了就返回对象
# 没有值就返回None
print(ret2.group())
# 返回的对象的第一个结果
#match
ret4=re.match('\d+','129393ashfk1238382')
print(ret4)
ret5=re.match('^\d+','%^129393ashfk1238382')
print(ret5)
sub 想当于replace替换
ret6=re.sub('\d+','H',"fajwekfafwfffjwf32442323",1)
subn 替换的次数
ret7=re.subn('\d+','H','rejkqjrek2134jkjf3r34f')
split 切割
ret8=re.split('\d+','alex34ergjg33taibai23faf')
compile
把正则表达式放里面,节省时间:只有在多次使用某一个相同的正则表达式的时候,这个compile
才会帮助我们提高程序的效率
finditer 空间效率
相当于拿到的是一个迭代器
ret=re.finditer('\d','fjafjak32332fjakfj233fjafk2344fakfj2323')
for r in ret:
print(r.group())
findall 会优先显示分组中的内容,要想取消分组优先(?:正则表达式)
split 遇到分组 会保留分组内被切割的内容在分组中
分组遇到search
如果search中有分组的话,通过group(n)拿到分组的内容
ret2=re.search('\d+(.\d+)(.\d+)(.\d+)?','1.2.3.4-2*(60+(-30+3))')
print(ret2.group())
print(ret2.group(1))
print(ret2.group(2))
print(ret2.group(3))
分组命名
(?P<name>正则表达式)表示给分组起名字(?P=name)表示使用这个分组,这里匹配到的内容应该和分组的内容全部一样
ret=re.search("<(?P<name>\w+)>\w+</(?P=name)>","<h1>helllo</h1>")
print(ret.group('name'))
决定自己的高度的是你的态度,而不是你的才能
记得我们是终身初学者和学习者
总有一天我也能成为大佬



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!