使用flink计算kafka消费消息排行榜(二)
1.安装
brew install kafka
2.出现日志
fangdada@fangdadadeMacBook-Pro ~ % brew install kafka
Updating Homebrew...
==> Installing dependencies for kafka: zookeeper
==> Installing kafka dependency: zookeeper
==> Downloading https://mirrors.ustc.edu.cn/homebrew-bottles/bottles/zookeeper-3.5.7.catalina.bottle.tar.gz
Already downloaded: /Users/fangdada/Library/Caches/Homebrew/downloads/31a050802ee3cfb12bae4b108394d33f8194225f13294110a73c902754b3b4eb--zookeeper-3.5.7.catalina.bottle.tar.gz
==> Pouring zookeeper-3.5.7.catalina.bottle.tar.gz
Warning: This keg was marked linked already, continuing anyway
==> Caveats
To have launchd start zookeeper now and restart at login:
brew services start zookeeper
Or, if you don't want/need a background service you can just run:
zkServer start
==> Summary
🍺 /usr/local/Cellar/zookeeper/3.5.7: 394 files, 11.3MB
==> Installing kafka
==> Downloading https://mirrors.ustc.edu.cn/homebrew-bottles/bottles/kafka-2.5.0.catalina.bottle.tar.gz
Already downloaded: /Users/fangdada/Library/Caches/Homebrew/downloads/e3a6462603701dfff8faf7c44c8daa08043a1f4401bf2e726ce388b68e633aa4--kafka-2.5.0.catalina.bottle.tar.gz
==> Pouring kafka-2.5.0.catalina.bottle.tar.gz
==> Caveats
To have launchd start kafka now and restart at login:
brew services start kafka
Or, if you don't want/need a background service you can just run:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties
==> Summary
🍺 /usr/local/Cellar/kafka/2.5.0: 187 files, 58.6MB
==> Caveats
==> zookeeper
To have launchd start zookeeper now and restart at login:
brew services start zookeeper
Or, if you don't want/need a background service you can just run:
zkServer start
==> kafka
To have launchd start kafka now and restart at login:
brew services start kafka
Or, if you don't want/need a background service you can just run:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties
3.日志中很清楚看到,软件安装的位置、配置文件的位置以及如何启动它们
位置:
/usr/local/Cellar/zookeeper
/usr/local/Cellar/kafka
配置文件位置:
/usr/local/etc/kafka/server.properties
/usr/local/etc/kafka/zookeeper.properties
启动命令:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties &
kafka-server-start /usr/local/etc/kafka/server.properties &
4.直接启动
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties &
kafka-server-start /usr/local/etc/kafka/server.properties &
5.创建名为fangdada的topic
由于我的2181端口不知道被什么占用,kill后,还是占用状态,重启也不行,所以把zk启动端口设置成2182了,在上面的zk配置文件中配置即可。
kafka-topics --create --zookeeper localhost:2182 --replication-factor 1 --partitions 1 --topic fangdada
结果:

6.查看创建的topic
kafka-topics --list --zookeeper localhost:2182
结果可以看到fangdada的topic被创建了:
fangdada@fangdadadeMacBook-Pro ~ % kafka-topics --list --zookeeper localhost:2182
__consumer_offsets
fangdada
test
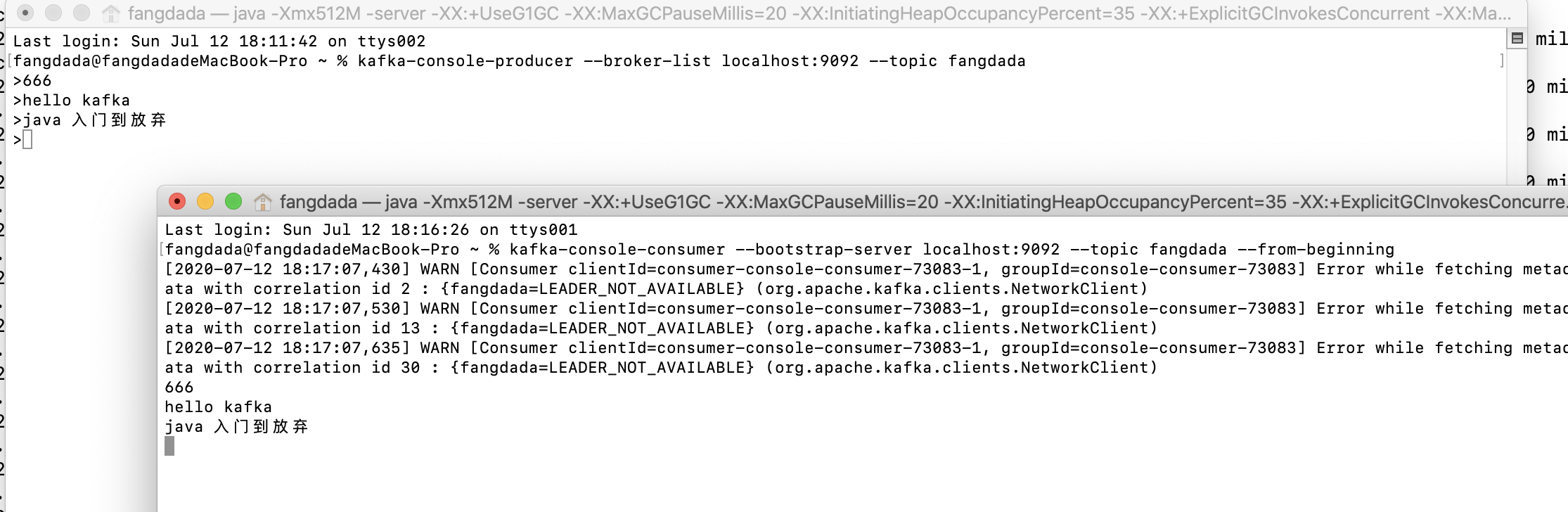
7.发送消息(zk默认端口是2181,kafka默认端口是9092,不要搞混了)
kafka-console-producer --broker-list localhost:9092 --topic fangdada
8.接收消息
kafka-console-consumer --bootstrap-server localhost:9092 --topic fangdada --from-beginning
9.结果
10.需求分解(下面代码转自开源项目God-Of-BigData)
* 告诉 Flink 框架基于时间做窗口,我们这里用processingTime,不用自带时间戳
* 过滤出图书点击行为数据
* 按一小时的窗口大小,每5秒钟统计一次,做滑动窗口聚合(Sliding Window)
* 聚合,输出窗口中点击量前N名的商品
代码:(虽然不太明白什么意思,但是觉得很牛逼)
package com.myflink.changxiao;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessAllWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer09;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.util.Comparator;
import java.util.Map;
import java.util.Properties;
import java.util.TreeMap;
/**
* @author fangdada
* @date 2020/7/11 10:16 下午
* @Version 1.0
*/
public class TopN {
public static void main(String[] args) throws Exception {
/**
*
* 书1 书2 书3
* (书1,1) (书2,1) (书3,1)
*/
//每隔5秒钟 计算过去1小时 的 Top 3 商品
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); //以processtime作为时间语义
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
FlinkKafkaConsumer09<String> input = new FlinkKafkaConsumer09<>("fangdada", new SimpleStringSchema(), properties);
//从最早开始消费 位点
input.setStartFromEarliest();
DataStream<String> stream = env
.addSource(input);
DataStream<Tuple2<String, Integer>> ds = stream
.flatMap(new LineSplitter()); //将输入语句split成一个一个单词并初始化count值为1的Tuple2<String, Integer>类型
DataStream<Tuple2<String, Integer>> wcount = ds
.keyBy(0)
.window(SlidingProcessingTimeWindows.of(Time.seconds(600),Time.seconds(5)))
//key之后的元素进入一个总时间长度为600s,每5s向后滑动一次的滑动窗口
.sum(1);// 将相同的key的元素第二个count值相加
wcount
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(5)))//(shu1, xx) (shu2,xx)....
//所有key元素进入一个5s长的窗口(选5秒是因为上游窗口每5s计算一轮数据,topN窗口一次计算只统计一个窗口时间内的变化)
.process(new TopNAllFunction(3))
.print();
//redis sink redis -> 接口
env.execute();
}//
private static final class LineSplitter implements
FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
//String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
/*for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}*/
//(书1,1) (书2,1) (书3,1)
out.collect(new Tuple2<String, Integer>(value, 1));
}
}
private static class TopNAllFunction
extends
ProcessAllWindowFunction<Tuple2<String, Integer>, String, TimeWindow> {
private int topSize = 3;
public TopNAllFunction(int topSize) {
this.topSize = topSize;
}
@Override
public void process(
ProcessAllWindowFunction<Tuple2<String, Integer>, String, TimeWindow>.Context arg0,
Iterable<Tuple2<String, Integer>> input,
Collector<String> out) throws Exception {
TreeMap<Integer, Tuple2<String, Integer>> treemap = new TreeMap<Integer, Tuple2<String, Integer>>(
new Comparator<Integer>() {
@Override
public int compare(Integer y, Integer x) {
return (x < y) ? -1 : 1;
}
}); //treemap按照key降序排列,相同count值不覆盖
for (Tuple2<String, Integer> element : input) {
treemap.put(element.f1, element);
if (treemap.size() > topSize) { //只保留前面TopN个元素
treemap.pollLastEntry();
}
}
for (Map.Entry<Integer, Tuple2<String, Integer>> entry : treemap
.entrySet()) {
out.collect("=================\n热销图书列表:\n"+ new Timestamp(System.currentTimeMillis()) + treemap.toString() + "\n===============\n");
}
}
}
}
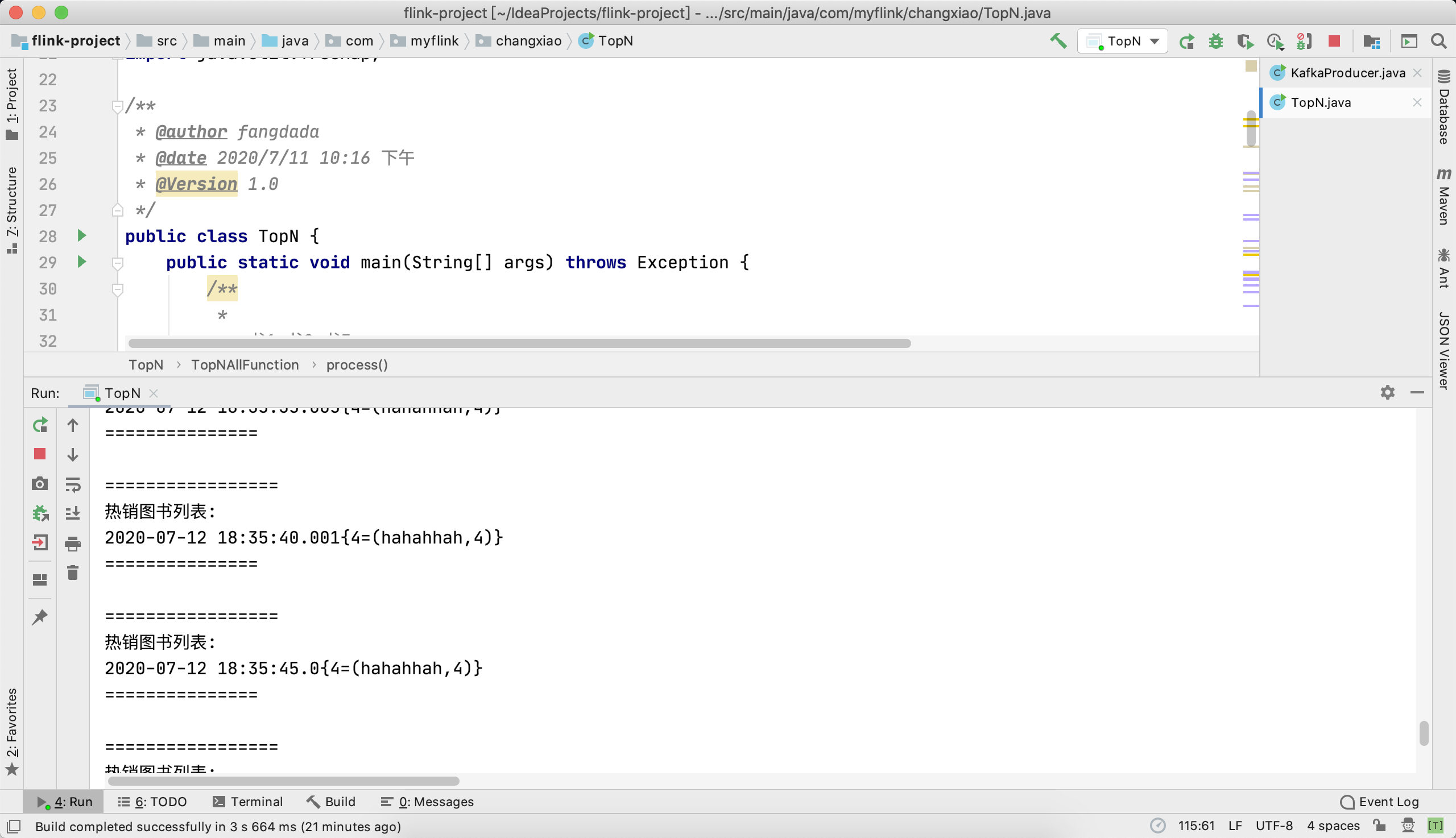
12.idea执行结果图
flink计算的结果,就是从kafka生产者发送消息到消费者消费消息中消息量的计算,取出排名前3的消息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号